Kubernetes 博客
- Kubernetes 1.20:CSI 驱动程序中的 Pod 身份假扮和短时卷
- Kubernetes 1.20: 最新版本
- 别慌: Kubernetes 和 Docker
- 弃用 Dockershim 的常见问题
- 为开发指南做贡献
- 结构化日志介绍
- Kubernetes 1.18: Fit & Finish
- 基于 MIPS 架构的 Kubernetes 方案
- Kubernetes 1.17:稳定
- 使用 Java 开发一个 Kubernetes controller
- 使用 Microk8s 在 Linux 上本地运行 Kubernetes
- Kubernetes 文档最终用户调研
- 圣迭戈贡献者峰会日程公布!
- 2019 指导委员会选举结果
- San Diego 贡献者峰会开放注册!
- OPA Gatekeeper:Kubernetes 的策略和管理
- 欢迎参加在上海举行的贡献者峰会
- 壮大我们的贡献者研讨会
- 如何参与 Kubernetes 文档的本地化工作
- Kubernetes 1.14 稳定性改进中的进程ID限制
- Raw Block Volume 支持进入 Beta
- 新贡献者工作坊上海站
- Kubernetes 文档更新,国际版
- Kubernetes 2018 年北美贡献者峰会
- 2018 年督导委员会选举结果
- Kubernetes 中的拓扑感知数据卷供应
- Kubernetes v1.12: RuntimeClass 简介
- KubeDirector:在 Kubernetes 上运行复杂状态应用程序的简单方法
- 在 Kubernetes 上对 gRPC 服务器进行健康检查
- The Machines Can Do the Work, a Story of Kubernetes Testing, CI, and Automating the Contributor Experience
- 使用 CSI 和 Kubernetes 实现卷的动态扩容
- 动态 Kubelet 配置
- 用于 Kubernetes 集群 DNS 的 CoreDNS GA 正式发布
- IPVS-Based In-Cluster Load Balancing Deep Dive
- Airflow在Kubernetes中的使用(第一部分):一种不同的操作器
- Kubernetes 内的动态 Ingress
- Kubernetes 这四年
- Kubernetes 1 11:向 discuss kubernetes 问好
- 在 Kubernetes 上开发
- Kubernetes 社区 - 2017 年开源排行榜榜首
- “基于容器的应用程序设计原理”
- Kubernetes 1.9 对 Windows Server 容器提供 Beta 版本支持
- Kubernetes 中自动缩放
- Kubernetes 1.8 的五天
- Kubernetes 社区指导委员会选举结果
- 使用 Kubernetes Pet Sets 和 Datera Elastic Data Fabric 的 FlexVolume 扩展有状态的应用程序
- Kubernetes 生日快乐。哦,这是你要去的地方!
- Dashboard - Kubernetes 的全功能 Web 界面
- Citrix + Kubernetes = 全垒打
- 容器中运行有状态的应用!? Kubernetes 1.3 说 “是!”
- CoreOS Fest 2016: CoreOS 和 Kubernetes 在柏林(和旧金山)社区见面会
- SIG-ClusterOps: 提升 Kubernetes 集群的可操作性和互操作性
- “SIG-Networking:1.3 版本引入 Kubernetes 网络策略 API”
- 在 Rancher 中添加对 Kuernetes 的支持
- KubeCon EU 2016:伦敦 Kubernetes 社区
- Kubernetes 社区会议记录 - 20160218
- Kubernetes 社区会议记录 - 20160204
- 容器世界现状,2016年1月
- Kubernetes 社区会议记录 - 20160114
- 为什么 Kubernetes 不用 libnetwork
- Simple leader election with Kubernetes and Docker
- 使用 Puppet 管理 Kubernetes Pods,Services 和 Replication Controllers
- Kubernetes 1.1 性能升级,工具改进和社区不断壮大
- Weekly Kubernetes Community Hangout Notes - July 31 2015
- 宣布首个Kubernetes企业培训课程
- 幻灯片:Kubernetes 集群管理,爱丁堡大学演讲
- OpenStack 上的 Kubernetes
- Kubernetes 社区每周聚会笔记- 2015年5月1日
- AppC Support for Kubernetes through RKT
- Kubernetes 社区每周聚会笔记- 2015年4月24日
- Borg: Kubernetes 的前身
- Kubernetes 社区每周聚会笔记- 2015年4月17日
- Kubernetes Release: 0.15.0
- 每周 Kubernetes 社区例会笔记 - 2015年4月3日
- Kubernetes 社区每周聚会笔记 - 2015年3月27日
- Kubernetes 采集视频
- 欢迎来到 Kubernetes 博客!
Kubernetes 1.20:CSI 驱动程序中的 Pod 身份假扮和短时卷
作者: Shihang Zhang(谷歌)
通常,当 CSI 驱动程序挂载 诸如 Secret 和证书之类的凭据时,它必须通过存储提供者的身份认证才能访问这些凭据。 然而,对这些凭据的访问是根据 Pod 的身份而不是 CSI 驱动程序的身份来控制的。 因此,CSI 驱动程序需要某种方法来取得 Pod 的服务帐户令牌。
当前,有两种不是那么理想的方法来实现这一目的,要么通过授予 CSI 驱动程序使用 TokenRequest API 的权限,要么直接从主机文件系统中读取令牌。
两者都存在以下缺点:
- 违反最少特权原则
- 每个 CSI 驱动程序都需要重新实现获取 Pod 的服务帐户令牌的逻辑
第二种方式问题更多,因为:
- 令牌的受众默认为 kube-apiserver
- 该令牌不能保证可用(例如,
AutomountServiceAccountToken=false) - 该方法不适用于以与 Pod 不同的(非 root 用户)用户身份运行的 CSI 驱动程序。请参见 服务帐户令牌的文件许可权部分
- 该令牌可能是旧的 Kubernetes 服务帐户令牌,如果
BoundServiceAccountTokenVolume=false,该令牌不会过期。
Kubernetes 1.20 引入了一个内测功能 CSIServiceAccountToken 以改善安全状况。这项新功能允许 CSI 驱动程序接收 Pod 的绑定服务帐户令牌。
此功能还提供了一个重新发布卷的能力,以便可以刷新短时卷。
Pod 身份假扮
使用 GCP APIs
使用 Workload Identity,Kubernetes 服务帐户可以在访问 Google Cloud API 时验证为 Google 服务帐户。
如果 CSI 驱动程序要代表其为挂载卷的 Pod 访问 GCP API,则可以使用 Pod 的服务帐户令牌来
交换 GCP 令牌。启用功能 CSIServiceAccountToken 后,
可通过 NodePublishVolume RPC 调用中的卷上下文来访问 Pod 的服务帐户令牌。例如:通过 Secret 存储 CSI 驱动
访问 Google Secret Manager。
使用Vault
如果用户将 Kubernetes 作为身份验证方法配置,
则 Vault 使用 TokenReview API 来验证 Kubernetes 服务帐户令牌。
对于使用 Vault 作为资源提供者的 CSI 驱动程序,它们需要将 Pod 的服务帐户提供给 Vault。
例如,Secret 存储 CSI 驱动和
证书管理器 CSI 驱动。
短时卷
为了使诸如证书之类的短时卷保持有效,CSI 驱动程序可以在其 CSIDriver 对象中指定 RequiresRepublish=true,
以使 kubelet 定期针对已挂载的卷调用 NodePublishVolume。
这些重新发布操作使 CSI 驱动程序可以确保卷内容是最新的。
下一步
此功能是 Alpha 版,预计将在 1.21 版中移至 Beta 版。 请参阅以下 KEP 和 CSI 文档中的更多内容:
随时欢迎您提供反馈!
- SIG-Auth 定期开会,可以通过 Slack 和邮件列表加入
- SIG-Storage 定期开会,可以通过 Slack 和邮件列表加入
Kubernetes 1.20: 最新版本
我们很高兴地宣布 Kubernetes 1.20 的发布,这是我们 2020 年的第三个也是最后一个版本!此版本包含 42 项增强功能:11 项增强功能已升级到稳定版,15 项增强功能正在进入测试版,16 项增强功能正在进入 Alpha 版。
1.20 发布周期在上一个延长的发布周期之后恢复到 11 周的正常节奏。这是一段时间以来功能最密集的版本之一:Kubernetes 创新周期仍呈上升趋势。此版本具有更多的 Alpha 而非稳定的增强功能,表明云原生生态系统仍有许多需要探索的地方。
主题
Volume 快照操作变得稳定
此功能提供了触发卷快照操作的标准方法,并允许用户以可移植的方式在任何 Kubernetes 环境和支持的存储提供程序上合并快照操作。
此外,这些 Kubernetes 快照原语充当基本构建块,解锁为 Kubernetes 开发高级企业级存储管理功能的能力,包括应用程序或集群级备份解决方案。
请注意,快照支持要求 Kubernetes 分销商捆绑 Snapshot 控制器、Snapshot CRD 和验证 webhook。还必须在集群上部署支持快照功能的 CSI 驱动程序。
Kubectl Debug 功能升级到 Beta
kubectl alpha debug 功能在 1.20 中升级到测试版,成为 kubectl debug. 该功能直接从 kubectl 提供对常见调试工作流的支持。此版本的 kubectl 支持的故障排除场景包括:
- 通过创建使用不同容器映像或命令的 pod 副本,对在启动时崩溃的工作负载进行故障排除。
- 通过在 pod 的新副本或使用临时容器中添加带有调试工具的新容器来对 distroless 容器进行故障排除。(临时容器是默认未启用的 alpha 功能。)
- 通过创建在主机命名空间中运行并可以访问主机文件系统的容器来对节点进行故障排除。
请注意,作为新的内置命令,kubectl debug 优先于任何名为 “debug” 的 kubectl 插件。你必须重命名受影响的插件。
kubectl alpha debug 现在不推荐使用,并将在后续版本中删除。更新你的脚本以使用 kubectl debug。 有关更多信息 kubectl debug,请参阅[调试正在运行的 Pod]((https://kubernetes.io/zh/docs/tasks/debug-application-cluster/debug-running-pod/)。
测试版:API 优先级和公平性 {#beta-api-priority-and-fairness)
Kubernetes 1.20 由 1.18 引入,现在默认启用 API 优先级和公平性 (APF)。这允许 kube-apiserver 按优先级对传入请求进行分类。
Alpha 更新:IPV4/IPV6
基于用户和社区反馈,重新实现了 IPv4/IPv6 双栈以支持双栈服务。 这允许将 IPv4 和 IPv6 服务集群 IP 地址分配给单个服务,还允许服务从单 IP 堆栈转换为双 IP 堆栈,反之亦然。
GA:进程 PID 稳定性限制
进程 ID (pid) 是 Linux 主机上的基本资源。达到任务限制而不达到任何其他资源限制并导致主机不稳定是很可能发生的。
管理员需要机制来确保用户 pod 不会导致 pid 耗尽,从而阻止主机守护程序(运行时、kubelet 等)运行。此外,重要的是要确保 pod 之间的 pid 受到限制,以确保它们对节点上的其他工作负载的影响有限。
默认启用一年后,SIG Node 在 SupportNodePidsLimit(节点到 Pod PID 隔离)和 SupportPodPidsLimit(限制每个 Pod 的 PID 的能力)上都将 PID 限制升级为 GA。
Alpha:节点体面地关闭
用户和集群管理员希望 Pod 遵守预期的 Pod 生命周期,包括 Pod 终止。目前,当一个节点关闭时,Pod 不会遵循预期的 Pod 终止生命周期,也不会正常终止,这可能会导致某些工作负载出现问题。
该 GracefulNodeShutdown 功能现在处于 Alpha 阶段。GracefulNodeShutdown 使 kubelet 知道节点系统关闭,从而在系统关闭期间正常终止 pod。
主要变化
Dockershim 弃用
Dockershim,Docker 的容器运行时接口 (CRI) shim 已被弃用。不推荐使用对 Docker 的支持,并将在未来版本中删除。由于 Docker 映像遵循开放容器计划 (OCI) 映像规范,因此 Docker 生成的映像将继续在具有所有 CRI 兼容运行时的集群中工作。 Kubernetes 社区写了一篇关于弃用的详细博客文章,并为其提供了一个专门的常见问题解答页面。
Exec 探测超时处理
一个关于 exec 探测超时的长期错误可能会影响现有的 pod 定义,已得到修复。在此修复之前,exec 探测器不考虑 timeoutSeconds 字段。相反,探测将无限期运行,甚至超过其配置的截止日期,直到返回结果。
通过此更改,如果未指定值,将应用默认值 1 second,并且如果探测时间超过一秒,现有 pod 定义可能不再足够。
新引入的 ExecProbeTimeout 特性门控所提供的修复使集群操作员能够恢复到以前的行为,但这种行为将在后续版本中锁定并删除。为了恢复到以前的行为,集群运营商应该将此特性门控设置为 false。
有关更多详细信息,请查看有关配置探针的更新文档。
其他更新
稳定版
- RuntimeClass
- 内置 API 类型默认值
- 添加了对 Pod 层面启动探针和活跃性探针的扼制
- 在 Windows 上支持 CRI-ContainerD
- SCTP 对 Services 的支持
- 将 AppProtocol 添加到 Services 和 Endpoints 上
值得注意的功能更新
发行说明
你可以在发行说明中查看 1.20 发行版的完整详细信息。
可用的发布
Kubernetes 1.20 可在 GitHub 上下载。有一些很棒的资源可以帮助你开始使用 Kubernetes。你可以在 Kubernetes 主站点上查看一些交互式教程,或者使用 kind 的 Docker 容器在你的机器上运行本地集群。如果你想尝试从头开始构建集群,请查看 Kelsey Hightower 的 Kubernetes the Hard Way 教程。
发布团队
这个版本是由一群非常敬业的人促成的,他们在世界上发生的许多事情的时段作为一个团队走到了一起。 非常感谢发布负责人 Jeremy Rickard 以及发布团队中的其他所有人,感谢他们相互支持,并努力为社区发布 1.20 版本。
发布 Logo

raddest: adjective, Slang. excellent; wonderful; cool:
Kubernetes 1.20 版本是迄今为止最激动人心的版本。
2020 年对我们中的许多人来说都是充满挑战的一年,但 Kubernetes 贡献者在此版本中提供了创纪录的增强功能。这是一项了不起的成就,因此发布负责人希望以一点轻松的方式结束这一年,并向 Kubernetes 1.14 - Caturnetes 和一只名叫 Humphrey 的 “rad” 猫致敬。
Humphrey是发布负责人的猫,有一个永久的 blep. 在 1990 年代,Rad 是美国非常普遍的俚语,激光背景也是如此。Humphrey 在 1990 年代风格的学校照片中感觉像是结束这一年的有趣方式。希望 Humphrey 和它的 blep 在 2020 年底给你带来一点快乐!
发布标志由 Henry Hsu - @robotdancebattle 创建。
用户亮点
- Apple 正在世界各地的数据中心运行数千个节点的 Kubernetes 集群。观看 Alena Prokarchyk 的 KubeCon NA 主题演讲,了解有关他们的云原生之旅的更多信息。
项目速度
CNCF K8S DevStats 项目聚集了许多有关Kubernetes和各分项目的速度有趣的数据点。这包括从个人贡献到做出贡献的公司数量的所有内容,并且清楚地说明了为发展这个生态系统所做的努力的深度和广度。
在持续 11 周(9 月 25 日至 12 月 9 日)的 v1.20 发布周期中,我们看到了来自 26 个国家/地区 的 967 家公司 和 1335 名个人(其中 44 人首次为 Kubernetes 做出贡献)的贡献。
生态系统更新
- KubeCon North America 三周前刚刚结束,这是第二个虚拟的此类活动!现在所有演讲都可以点播,供任何需要赶上的人使用!
- 6 月,Kubernetes 社区成立了一个新的工作组,作为对美国各地发生的 Black Lives Matter 抗议活动的直接回应。WG Naming 的目标是尽可能彻底地删除 Kubernetes 项目中有害和不清楚的语言,并以可移植到其他 CNCF 项目的方式进行。在 KubeCon 2020 North America 上就这项重要工作及其如何进行进行了精彩的介绍性演讲,这项工作的初步影响实际上可以在 v1.20 版本中看到。
- 此前于今年夏天宣布,在 Kubecon NA 期间发布了经认证的 Kubernetes 安全专家 (CKS) 认证 ,以便立即安排!遵循 CKA 和 CKAD 的模型,CKS 是一项基于性能的考试,侧重于以安全为主题的能力和领域。该考试面向当前的 CKA 持有者,尤其是那些想要完善其在保护云工作负载方面的基础知识的人(这是我们所有人,对吧?)。
活动更新
KubeCon + CloudNativeCon Europe 2021 将于 2021 年 5 月 4 日至 7 日举行!注册将于 1 月 11 日开放。你可以在此处找到有关会议的更多信息。 请记住,CFP 将于太平洋标准时间 12 月 13 日星期日晚上 11:59 关闭!
即将发布的网络研讨会
请继续关注今年 1 月即将举行的发布网络研讨会。
参与其中
如果你有兴趣为 Kubernetes 社区做出贡献,那么特别兴趣小组 (SIG) 是一个很好的起点。其中许多可能符合你的兴趣!如果你有什么想与社区分享的内容,你可以参加每周的社区会议,或使用以下任一渠道:
- 在新的 Kubernetes Contributor 网站上了解更多关于为Kubernetes 做出贡献的信息
- 在 Twitter @Kubernetesio 上关注我们以获取最新更新
- 加入关于讨论的社区讨论
- 加入 Slack 社区
- 分享你的 Kubernetes 故事
- 在博客上阅读更多关于 Kubernetes 发生的事情
- 了解有关 Kubernetes 发布团队的更多信息
别慌: Kubernetes 和 Docker
作者: Jorge Castro, Duffie Cooley, Kat Cosgrove, Justin Garrison, Noah Kantrowitz, Bob Killen, Rey Lejano, Dan “POP” Papandrea, Jeffrey Sica, Davanum “Dims” Srinivas
Kubernetes 从版本 v1.20 之后,弃用 Docker 这个容器运行时。
不必慌张,这件事并没有听起来那么吓人。
弃用 Docker 这个底层运行时,转而支持符合为 Kubernetes 创建的容器运行接口 Container Runtime Interface (CRI) 的运行时。 Docker 构建的镜像,将在你的集群的所有运行时中继续工作,一如既往。
如果你是 Kubernetes 的终端用户,这对你不会有太大影响。
这事并不意味着 Docker 已死、也不意味着你不能或不该继续把 Docker 用作开发工具。
Docker 仍然是构建容器的利器,使用命令 docker build 构建的镜像在 Kubernetes 集群中仍然可以运行。
如果你正在使用 GKE、EKS、或 AKS
(默认使用 containerd)
这类托管 Kubernetes 服务,你需要在 Kubernetes 后续版本移除对 Docker 支持之前,
确认工作节点使用了被支持的容器运行时。
如果你的节点被定制过,你可能需要根据你自己的环境和运行时需求更新它们。
请与你的服务供应商协作,确保做出适当的升级测试和计划。
如果你正在运营你自己的集群,那还应该做些工作,以避免集群中断。 在 v1.20 版中,你仅会得到一个 Docker 的弃用警告。 当对 Docker 运行时的支持在 Kubernetes 某个后续发行版(目前的计划是 2021 年晚些时候的 1.22 版)中被移除时, 你需要切换到 containerd 或 CRI-O 等兼容的容器运行时。 只要确保你选择的运行时支持你当前使用的 Docker 守护进程配置(例如 logging)。
那为什么会有这样的困惑,为什么每个人要害怕呢?
我们在这里讨论的是两套不同的环境,这就是造成困惑的根源。 在你的 Kubernetes 集群中,有一个叫做容器运行时的东西,它负责拉取并运行容器镜像。 Docker 对于运行时来说是一个流行的选择(其他常见的选择包括 containerd 和 CRI-O), 但 Docker 并非设计用来嵌入到 Kubernetes,这就是问题所在。
你看,我们称之为 “Docker” 的物件实际上并不是一个物件——它是一个完整的技术堆栈, 它其中一个叫做 “containerd” 的部件本身,才是一个高级容器运行时。 Docker 既酷炫又实用,因为它提供了很多用户体验增强功能,而这简化了我们做开发工作时的操作, Kubernetes 用不到这些增强的用户体验,毕竟它并非人类。
因为这个用户友好的抽象层,Kubernetes 集群不得不引入一个叫做 Dockershim 的工具来访问它真正需要的 containerd。 这不是一件好事,因为这引入了额外的运维工作量,而且还可能出错。 实际上正在发生的事情就是:Dockershim 将在不早于 v1.23 版中从 kubelet 中被移除,也就取消对 Docker 容器运行时的支持。 你心里可能会想,如果 containerd 已经包含在 Docker 堆栈中,为什么 Kubernetes 需要 Dockershim。
Docker 不兼容 CRI, 容器运行时接口。 如果支持,我们就不需要这个 shim 了,也就没问题了。 但这也不是世界末日,你也不需要恐慌——你唯一要做的就是把你的容器运行时从 Docker 切换到其他受支持的容器运行时。
要注意一点:如果你依赖底层的 Docker 套接字(/var/run/docker.sock),作为你集群中工作流的一部分,
切换到不同的运行时会导致你无法使用它。
这种模式经常被称之为嵌套 Docker(Docker in Docker)。
对于这种特殊的场景,有很多选项,比如:
kaniko、
img、和
buildah。
那么,这一改变对开发人员意味着什么?我们还要写 Dockerfile 吗?还能用 Docker 构建镜像吗?
此次改变带来了一个不同的环境,这不同于我们常用的 Docker 交互方式。 你在开发环境中用的 Docker 和你 Kubernetes 集群中的 Docker 运行时无关。 我们知道这听起来让人困惑。 对于开发人员,Docker 从所有角度来看仍然有用,就跟这次改变之前一样。 Docker 构建的镜像并不是 Docker 特有的镜像——它是一个 OCI(开放容器标准)镜像。 任一 OCI 兼容的镜像,不管它是用什么工具构建的,在 Kubernetes 的角度来看都是一样的。 containerd 和 CRI-O 两者都知道怎么拉取并运行这些镜像。 这就是我们制定容器标准的原因。
所以,改变已经发生。 它确实带来了一些问题,但这不是一个灾难,总的说来,这还是一件好事。 根据你操作 Kubernetes 的方式的不同,这可能对你不构成任何问题,或者也只是意味着一点点的工作量。 从一个长远的角度看,它使得事情更简单。 如果你还在困惑,也没问题——这里还有很多事情; Kubernetes 有很多变化中的功能,没有人是100%的专家。 我们鼓励你提出任何问题,无论水平高低、问题难易。 我们的目标是确保所有人都能在即将到来的改变中获得足够的了解。 我们希望这已经回答了你的大部分问题,并缓解了一些焦虑!❤️
还在寻求更多答案吗?请参考我们附带的 弃用 Dockershim 的常见问题。
弃用 Dockershim 的常见问题
本文回顾了自 Kubernetes v1.20 版宣布弃用 Dockershim 以来所引发的一些常见问题。 关于 Kubernetes kubelets 从容器运行时的角度弃用 Docker 的细节以及这些细节背后的含义,请参考博文 别慌: Kubernetes 和 Docker。
为什么弃用 dockershim
维护 dockershim 已经成为 Kubernetes 维护者肩头一个沉重的负担。 创建 CRI 标准就是为了减轻这个负担,同时也可以增加不同容器运行时之间平滑的互操作性。 但反观 Docker 却至今也没有实现 CRI,所以麻烦就来了。
Dockershim 向来都是一个临时解决方案(因此得名:shim)。 你可以进一步阅读 移除 Kubernetes 增强方案 Dockershim 以了解相关的社区讨论和计划。
此外,与 dockershim 不兼容的一些特性,例如:控制组(cgoups)v2 和用户名字空间(user namespace),已经在新的 CRI 运行时中被实现。 移除对 dockershim 的支持将加速这些领域的发展。
在 Kubernetes 1.20 版本中,我还可以用 Docker 吗?
当然可以,在 1.20 版本中仅有的改变就是:如果使用 Docker 运行时,启动 kubelet 的过程中将打印一条警告日志。
什么时候移除 dockershim
考虑到此改变带来的影响,我们使用了一个加长的废弃时间表。 在 Kubernetes 1.22 版之前,它不会被彻底移除;换句话说,dockershim 被移除的最早版本会是 2021 年底发布的 1.23 版。 更新:dockershim 计划在 Kubernetes 1.24 版被移除, 请参阅移除 Kubernetes 增强方案 Dockershim。 我们将与供应商以及其他生态团队紧密合作,确保顺利过渡,并将依据事态的发展评估后续事项。
我现有的 Docker 镜像还能正常工作吗?
当然可以,docker build 创建的镜像适用于任何 CRI 实现。
所有你的现有镜像将和往常一样工作。
私有镜像呢?
当然可以。所有 CRI 运行时均支持 Kubernetes 中相同的拉取(pull)Secret 配置, 不管是通过 PodSpec 还是通过 ServiceAccount 均可。
Docker 和容器是一回事吗?
虽然 Linux 的容器技术已经存在了很久, 但 Docker 普及了 Linux 容器这种技术模式,并在开发底层技术方面发挥了重要作用。 容器的生态相比于单纯的 Docker,已经进化到了一个更宽广的领域。 像 OCI 和 CRI 这类标准帮助许多工具在我们的生态中成长和繁荣, 其中一些工具替代了 Docker 的某些部分,另一些增强了现有功能。
现在是否有在生产系统中使用其他运行时的例子?
Kubernetes 所有项目在所有版本中出产的工件(Kubernetes 二进制文件)都经过了验证。
此外,kind 项目使用 containerd 已经有年头了, 并且在这个场景中,稳定性还明显得到提升。 Kind 和 containerd 每天都会做多次协调,以验证对 Kubernetes 代码库的所有更改。 其他相关项目也遵循同样的模式,从而展示了其他容器运行时的稳定性和可用性。 例如,OpenShift 4.x 从 2019 年 6 月以来,就一直在生产环境中使用 CRI-O 运行时。
至于其他示例和参考资料,你可以查看 containerd 和 CRI-O 的使用者列表, 这两个容器运行时是云原生基金会([CNCF])下的项目。
人们总在谈论 OCI,那是什么?
OCI 代表开放容器标准, 它标准化了容器工具和底层实现(technologies)之间的大量接口。 他们维护了打包容器镜像(OCI image-spec)和运行容器(OCI runtime-spec)的标准规范。 他们还以 runc 的形式维护了一个 runtime-spec 的真实实现, 这也是 containerd 和 CRI-O 依赖的默认运行时。 CRI 建立在这些底层规范之上,为管理容器提供端到端的标准。
我应该用哪个 CRI 实现?
这是一个复杂的问题,依赖于许多因素。 在 Docker 工作良好的情况下,迁移到 containerd 是一个相对容易的转换,并将获得更好的性能和更少的开销。 然而,我们建议你先探索 CNCF 全景图 提供的所有选项,以做出更适合你的环境的选择。
当切换 CRI 底层实现时,我应该注意什么?
Docker 和大多数 CRI(包括 containerd)的底层容器化代码是相同的,但其周边部分却存在一些不同。 迁移时一些常见的关注点是:
- 日志配置
- 运行时的资源限制
- 直接访问 docker 命令或通过控制套接字调用 Docker 的节点供应脚本
- 需要访问 docker 命令或控制套接字的 kubectl 插件
- 需要直接访问 Docker 的 Kubernetes 工具(例如:kube-imagepuller)
- 像
registry-mirrors和不安全的注册表这类功能的配置 - 需要 Docker 保持可用、且运行在 Kubernetes 之外的,其他支持脚本或守护进程(例如:监视或安全代理)
- GPU 或特殊硬件,以及它们如何与你的运行时和 Kubernetes 集成
如果你只是用了 Kubernetes 资源请求/限制或基于文件的日志收集 DaemonSet,它们将继续稳定工作, 但是如果你用了自定义了 dockerd 配置,则可能需要为新容器运行时做一些适配工作。
另外还有一个需要关注的点,那就是当创建镜像时,系统维护或嵌入容器方面的任务将无法工作。
对于前者,可以用 crictl 工具作为临时替代方案
(参见 从 docker 命令映射到 crictl);
对于后者,可以用新的容器创建选项,比如
img、
buildah、
kaniko、或
buildkit-cli-for-kubectl,
他们均不需要访问 Docker。
对于 containerd,你可以从它们的 文档 开始,看看在迁移过程中有哪些配置选项可用。
对于如何协同 Kubernetes 使用 containerd 和 CRI-O 的说明,参见 Kubernetes 文档中这部分: 容器运行时。
我还有问题怎么办?
如果你使用了一个有供应商支持的 Kubernetes 发行版,你可以咨询供应商他们产品的升级计划。 对于最终用户的问题,请把问题发到我们的最终用户社区的论坛:https://discuss.kubernetes.io/。
你也可以看看这篇优秀的博文: 等等,Docker 刚刚被 Kubernetes 废掉了? 一个对此变化更深入的技术讨论。
我可以加入吗?
只要你愿意,随时随地欢迎加入!
为开发指南做贡献
当大多数人想到为一个开源项目做贡献时,我猜想他们可能想到的是贡献代码修改、新功能和错误修复。作为一个软件工程师和一个长期的开源用户和贡献者,这也正是我的想法。 虽然我已经在不同的工作流中写了不少文档,但规模庞大的 Kubernetes 社区是一种新型 "客户"。我只是不知道当 Google 要求我和 Lion's Way 的同胞们对 Kubernetes 开发指南进行必要更新时会发生什么。
本文最初出现在 Kubernetes Contributor Community blog。
与社区合作的乐趣
作为专业的写手,我们习惯了受雇于他人去书写非常具体的项目。我们专注于技术服务,产品营销,技术培训以及文档编制,范围从相对宽松的营销邮件到针对 IT 和开发人员的深层技术白皮书。 在这种专业服务下,每一个可交付的项目往往都有可衡量的投资回报。我知道在从事开源文档工作时不会出现这个指标,但我不确定它将如何改变我与项目的关系。
我们的写作和传统客户之间的关系有一个主要的特点,就是我们在一个公司里面总是有一两个主要的对接人。他们负责审查我们的文稿,并确保文稿内容符合公司的声明且对标于他们正在寻找的受众。 这随之而来的压力--正好解释了为什么我很高兴我的写作伙伴、鹰眼审稿人同时也是嗜血编辑的 Joel 处理了大部分的客户联系。
在与 Kubernetes 社区合作时,所有与客户接触的压力都消失了,这让我感到惊讶和高兴。
"我必须得多仔细?如果我搞砸了怎么办?如果我让开发商生气了怎么办?如果我树敌了怎么办?"。 当我第一次加入 Kubernetes Slack 上的 "#sig-contribex " 频道并宣布我将编写 开发指南 时,这些问题都在我脑海中奔腾,让我感觉如履薄冰。
"Kubernetes 编码准则已经生效,让我们共同勉励。" — Jorge Castro, SIG ContribEx co-chair
事实上我的担心是多虑的。很快,我就感觉到自己是被欢迎的。我倾向于认为这不仅仅是因为我正在从事一项急需的任务,而是因为 Kubernetes 社区充满了友好、热情的人们。 在每周的 SIG ContribEx 会议上,我们关于开发指南进展情况的报告会被立即纳入其中。此外,会议的领导会一直强调 Kubernetes 编码准则,我们应该像 Bill 和 Ted 一样,相互进步。
这并不意味着这一切都很简单
开发指南需要一次全面检查。当我们拿到它的时候,它已经捆绑了大量的信息和很多新开发者需要经历的步骤,但随着时间的推移和被忽视,它变得相当陈旧。 文档的确需要全局观,而不仅仅是点与点的修复。结果,最终我向这个项目提交了一个巨大的 pull 请求。社区仓库:新增 267 行,删除 88 行。
pull 请求的周期需要一定数量的 Kubernetes 组织成员审查和批准更改后才能合并。这是一个很好的做法,因为它使文档和代码都保持在相当不错的状态, 但要哄骗合适的人花时间来做这样一个赫赫有名的审查是很难的。 因此,那次大规模的 PR 从我第一次提交到最后合并,用了 26 天。 但最终,它是成功的.
由于 Kubernetes 是一个发展相当迅速的项目,而且开发人员通常对编写文档并不十分感兴趣,所以我也遇到了一个问题,那就是有时候, 描述 Kubernetes 子系统工作原理的秘密珍宝被深埋在 天才工程师的迷宫式思维 中,而不是用单纯的英文写在 Markdown 文件中。 当我要更新端到端(e2e)测试的入门文档时,就一头撞上了这个问题。
这段旅程将我带出了编写文档的领域,进入到一些未完成软件的全新用户角色。最终我花了很多心思与新的 kubetest2`框架 的开发者之一合作, 记录了最新 e2e 测试的启动和运行过程。 你可以通过查看我的 已完成的 pull request 来自己判断结果。
没有人是老板,每个人都给出反馈。
但当我暗自期待混乱的时候,为 Kubernetes 开发指南做贡献以及与神奇的 Kubernetes 社区互动的过程却非常顺利。 没有争执,我也没有树敌。每个人都非常友好和热情。这是令人愉快的。
对于一个开源项目,没人是老板。Kubernetes 项目,一个近乎巨大的项目,被分割成许多不同的特殊兴趣小组(SIG)、工作组和社区。 每个小组都有自己的定期会议、职责分配和主席推选。我的工作与 SIG ContribEx(负责监督并寻求改善贡献者体验)和 SIG Testing(负责测试)的工作有交集。 事实证明,这两个 SIG 都很容易合作,他们渴望贡献,而且都是非常友好和热情的人。
在 Kubernetes 这样一个活跃的、有生命力的项目中,文档仍然需要与代码库一起进行维护、修订和测试。 开发指南将继续对 Kubernetes 代码库的新贡献者起到至关重要的作用,正如我们的努力所显示的那样,该指南必须与 Kubernetes 项目的发展保持同步。
Joel 和我非常喜欢与 Kubernetes 社区互动并为开发指南做出贡献。我真的很期待,不仅能继续做出更多贡献,还能继续与过去几个月在这个庞大的开源社区中结识的新朋友进行合作。
结构化日志介绍
作者: Marek Siarkowicz(谷歌),Nathan Beach(谷歌)
日志是可观察性的一个重要方面,也是调试的重要工具。 但是Kubernetes日志传统上是非结构化的字符串,因此很难进行自动解析,以及任何可靠的后续处理、分析或查询。
在Kubernetes 1.19中,我们添加结构化日志的支持,该日志本身支持(键,值)对和对象引用。 我们还更新了许多日志记录调用,以便现在将典型部署中超过99%的日志记录量迁移为结构化格式。
为了保持向后兼容性,结构化日志仍将作为字符串输出,其中该字符串包含这些“键” =“值”对的表示。 从1.19的Alpha版本开始,日志也可以使用--logging-format = json标志以JSON格式输出。
使用结构化日志
我们在klog库中添加了两个新方法:InfoS和ErrorS。 例如,InfoS的此调用:
klog.InfoS("Pod status updated", "pod", klog.KObj(pod), "status", status)
将得到下面的日志输出:
I1025 00:15:15.525108 1 controller_utils.go:116] "Pod status updated" pod="kube-system/kubedns" status="ready"
或者, 如果 --logging-format=json 模式被设置, 将会产生如下结果:
{
"ts": 1580306777.04728,
"msg": "Pod status updated",
"pod": {
"name": "coredns",
"namespace": "kube-system"
},
"status": "ready"
}
这意味着下游日志记录工具可以轻松地获取结构化日志数据,而无需使用正则表达式来解析非结构化字符串。这也使处理日志更容易,查询日志更健壮,并且分析日志更快。
使用结构化日志,所有对Kubernetes对象的引用都以相同的方式进行结构化,因此您可以过滤输出并且仅引用特定Pod的日志条目。您还可以发现指示调度程序如何调度Pod,如何创建Pod,监测Pod的运行状况以及Pod生命周期中的所有其他更改的日志。
假设您正在调试Pod的问题。使用结构化日志,您可以只过滤查看感兴趣的Pod的日志条目,而无需扫描可能成千上万条日志行以找到相关的日志行。
结构化日志不仅在手动调试问题时更有用,而且还启用了更丰富的功能,例如日志的自动模式识别或日志和所跟踪数据的更紧密关联性(分析)。
最后,结构化日志可以帮助降低日志的存储成本,因为大多数存储系统比非结构化字符串更有效地压缩结构化键值数据。
参与其中
虽然在典型部署中,我们已按日志量更新了99%以上的日志条目,但仍有数千个日志需要更新。 选择一个您要改进的文件或目录,然后[迁移现有的日志调用以使用结构化日志](https://github.com/kubernetes/community/blob/master/contributors/devel/sig-instrumentation/migration-to-structured-logging.md)。这是对Kubernetes做出第一笔贡献的好方法!
Kubernetes 1.18: Fit & Finish
我们很高兴宣布 Kubernetes 1.18 版本的交付,这是我们 2020 年的第一版! Kubernetes 1.18 包含 38 个增强功能:15 项增强功能已转为稳定版,11 项增强功能处于 beta 阶段,12 项增强功能处于 alpha 阶段。
Kubernetes 1.18 是一个近乎 “完美” 的版本。 为了改善 beta 和稳定的特性,已进行了大量工作,以确保用户获得更好的体验。 我们在增强现有功能的同时也增加了令人兴奋的新特性,这些有望进一步增强用户体验。
对 alpha,beta 和稳定版进行几乎同等程度的增强是一项伟大的成就。 它展现了社区在提高 Kubernetes 的可靠性以及继续扩展其现有功能方面所做的巨大努力。
主要内容
Kubernetes 拓扑管理器(Topology Manager)进入 Beta 阶段 - 对齐!
Kubernetes 在 1.18 版中的 Beta 阶段功能 拓扑管理器特性 启用 CPU 和设备(例如 SR-IOV VF)的 NUMA 对齐,这将使您的工作负载在针对低延迟而优化的环境中运行。在引入拓扑管理器之前,CPU 和设备管理器将做出彼此独立的资源分配决策。 这可能会导致在多处理器系统上非预期的资源分配结果,从而导致对延迟敏感的应用程序的性能下降。
Serverside Apply 推出Beta 2
Serverside Apply 在1.16 中进入 Beta 阶段,但现在在 1.18 中进入了第二个 Beta 阶段。 这个新版本将跟踪和管理所有新 Kubernetes 对象的字段更改,从而使您知道什么更改了资源以及何时发生了更改。
使用 IngressClass 扩展 Ingress 并用 IngressClass 替换已弃用的注释
在 Kubernetes 1.18 中,Ingress 有两个重要的补充:一个新的 pathType 字段和一个新的 IngressClass 资源。pathType 字段允许指定路径的匹配方式。 除了默认的ImplementationSpecific类型外,还有新的 Exact和Prefix 路径类型。
IngressClass 资源用于描述 Kubernetes 集群中 Ingress 的类型。 Ingress 对象可以通过在Ingress 资源类型上使用新的ingressClassName 字段来指定与它们关联的类。 这个新的资源和字段替换了不再建议使用的 kubernetes.io/ingress.class 注解。
SIG-CLI 引入了 kubectl alpha debug
SIG-CLI 一直在争论着调试工具的必要性。随着 临时容器 的发展,我们如何使用基于 kubectl exec 的工具来支持开发人员的必要性变得越来越明显。 kubectl alpha debug 命令 的增加,(由于是 alpha 阶段,非常欢迎您反馈意见),使开发人员可以轻松地在集群中调试 Pod。我们认为这个功能的价值非常高。 此命令允许创建一个临时容器,该容器在要尝试检查的 Pod 旁边运行,并且还附加到控制台以进行交互式故障排除。
为 Kubernetes 引入 Windows CSI 支持(Alpha)
用于 Windows 的 CSI 代理的 Alpha 版本随 Kubernetes 1.18 一起发布。 CSI 代理通过允许Windows 中的容器执行特权存储操作来启用 Windows 上的 CSI 驱动程序。
其它更新
毕业转为稳定版
- 基于污点的逐出操作
kubectl diff- CSI 块存储支持
- API 服务器 dry run
- 在 CSI 调用中传递 Pod 信息
- 支持树外 vSphere 云驱动
- 对 Windows 负载支持 GMSA
- 对不可挂载的CSI卷跳过挂载
- PVC 克隆
- 移动 kubectl 包代码到 staging
- Windows 的 RunAsUserName
- 服务和端点的 AppProtocol
- 扩展 Hugepage 特性
- client-go signature refactor to standardize options and context handling
- Node-local DNS cache
主要变化
- EndpointSlice API
- Moving kubectl package code to staging
- CertificateSigningRequest API
- Extending Hugepage Feature
- client-go 的调用规范重构来标准化选项和管理上下文
发布说明
在我们的 发布文档中查看 Kubernetes 1.18 发行版的完整详细信息。
下载安装
Kubernetes 1.18 可以在 GitHub 上下载。 要开始使用Kubernetes,请查看这些 交互教程 或通过kind 使用 Docker 容器运行本地 kubernetes 集群。您还可以使用kubeadm轻松安装 1.18。
发布团队
通过数百位贡献了技术和非技术内容的个人的努力,使本次发行成为可能。 特别感谢由 Searchable AI 的网站可靠性工程师 Jorge Alarcon Ochoa 领导的发布团队。 34 位发布团队成员协调了发布的各个方面,从文档到测试、验证和功能完整性。
随着 Kubernetes 社区的发展壮大,我们的发布过程很好地展示了开源软件开发中的协作。 Kubernetes 继续快速获取新用户。 这种增长创造了一个积极的反馈回路,其中有更多的贡献者提交了代码,从而创建了更加活跃的生态系统。 迄今为止,Kubernetes 已有 40,000 独立贡献者 和一个超过3000人的活跃社区。
发布 logo
![]()
为什么是 LHC
LHC 是世界上最大,功能最强大的粒子加速器。它是由来自世界各地成千上万科学家合作的结果,所有这些合作都是为了促进科学的发展。以类似的方式,Kubernetes 已经成为一个聚集了来自数百个组织的数千名贡献者–所有人都朝着在各个方面改善云计算的相同目标努力的项目! 发布名称“ A Bit Quarky” 的意思是提醒我们,非常规的想法可以带来巨大的变化,对开放性保持开放态度将有助于我们进行创新。
关于设计者
Maru Lango 是目前居住在墨西哥城的设计师。她的专长是产品设计,她还喜欢使用 CSS + JS 进行品牌、插图和视觉实验,为技术和设计社区的多样性做贡献。您可能会在大多数社交媒体上以 @marulango 的身份找到她,或查看她的网站: https://marulango.com
高光用户
- 爱立信正在使用 Kubernetes 和其他云原生技术来交付高标准的 5G 网络,这可以在 CI/CD 上节省多达 90% 的支出。
- Zendesk 正在使用 Kubernetes 运行其现有应用程序的约 70%。它还正在使所构建的所有新应用都可以在 Kubernetes 上运行,从而节省时间、提高灵活性并加快其应用程序开发的速度。
- LifeMiles 因迁移到 Kubernetes 而降低了 50% 的基础设施开支。Kubernetes 还使他们可以将其可用资源容量增加一倍。
生态系统更新
- CNCF发布了年度调查 的结果,表明 Kubernetes 在生产中的使用正在飞速增长。调查发现,有78%的受访者在生产中使用Kubernetes,而去年这一比例为 58%。
- CNCF 举办的 “Kubernetes入门” 课程有超过 100,000 人注册。
项目速度
CNCF 继续完善 DevStats。这是一个雄心勃勃的项目,旨在对项目中的无数贡献数据进行可视化展示。K8s DevStats 展示了主要公司贡献者的贡献细目,以及一系列令人印象深刻的预定义的报告,涉及从贡献者个人的各方面到 PR 生命周期的各个方面。
在过去的一个季度中,641 家不同的公司和超过 6,409 个个人为 Kubernetes 作出贡献。 查看 DevStats 以了解有关 Kubernetes 项目和社区发展速度的信息。
活动信息
Kubecon + CloudNativeCon EU 2020 已经推迟 - 有关最新信息,请查看新型肺炎发布页面。
即将到来的发布的线上会议
在 2020 年 4 月 23 日,和 Kubernetes 1.18 版本团队一起了解此版本的主要功能,包括 kubectl debug、拓扑管理器、Ingress 毕业为 V1 版本以及 client-go。 在此处注册:https://www.cncf.io/webinars/kubernetes-1-18/ 。
如何参与
参与 Kubernetes 的最简单方法是加入众多与您的兴趣相关的 特别兴趣小组 (SIGs) 之一。 您有什么想向 Kubernetes 社区发布的内容吗? 参与我们的每周 社区会议,并通过以下渠道分享您的声音。 感谢您一直以来的反馈和支持。
- 在 Twitter 上关注我们 @Kubernetesio,了解最新动态
- 在 Discuss 上参与社区讨论
- 加入 Slack 上的社区
- 在Stack Overflow提问(或回答)
- 分享您的 Kubernetes 故事
- 通过 blog了解更多关于 Kubernetes 的新鲜事
- 了解更多关于 Kubernetes 发布团队 的信息
基于 MIPS 架构的 Kubernetes 方案
作者: 石光银,尹东超,展望,江燕,蔡卫卫,高传集,孙思清(浪潮)
背景
MIPS (Microprocessor without Interlocked Pipelined Stages) 是一种采取精简指令集(RISC)的处理器架构 (ISA),出现于 1981 年,由 MIPS 科技公司开发。如今 MIPS 架构被广泛应用于许多电子产品上。
Kubernetes 官方目前支持众多 CPU 架构诸如 x86, arm/arm64, ppc64le, s390x 等。然而目前还不支持 MIPS 架构,始终是一个遗憾。随着云原生技术的广泛应用,MIPS 架构下的用户始终对 Kubernetes on MIPS 有着迫切的需求。
成果
多年来,为了丰富开源社区的生态,我们一直致力于在 MIPS 架构下适配 Kubernetes。随着 MIPS CPU 的不断迭代优化和性能的提升,我们在 mips64el 平台上取得了一些突破性的进展。
多年来,我们一直积极投入 Kubernetes 社区,在 Kubernetes 技术应用和优化方面具备了丰富的经验。最近,我们在研发过程中尝试将 Kubernetes 适配到 MIPS 架构平台,并取得了阶段性成果。成功完成了 Kubernetes 以及相关组件的迁移适配,不仅搭建出稳定高可用的 MIPS 集群,同时完成了 Kubernetes v1.16.2 版本的一致性测试。
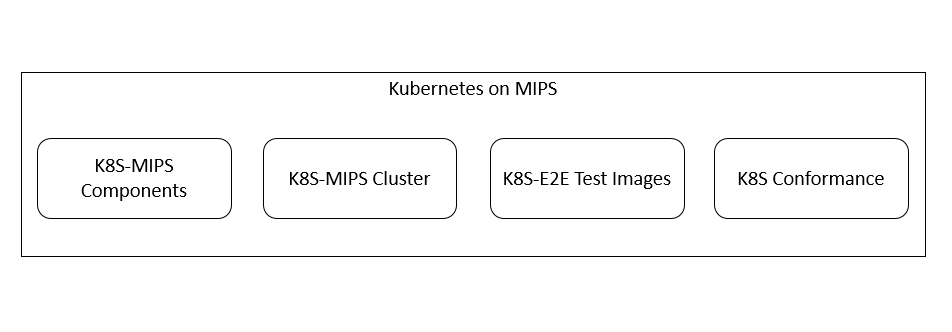
图一 Kubernetes on MIPS
K8S-MIPS 组件构建
几乎所有的 Kubernetes 相关的云原生组件都没有提供 MIPS 版本的安装包或镜像,在 MIPS 平台上部署 Kubernetes 的前提是自行编译构建出全部所需组件。这些组件主要包括:
- golang
- docker-ce
- hyperkube
- pause
- etcd
- calico
- coredns
- metrics-server
得益于 Golang 优秀的设计以及对于 MIPS 平台的良好支持,极大地简化了上述云原生组件的编译过程。首先,我们在 mips64el 平台编译出了最新稳定的 golang, 然后通过源码构建的方式编译完成了上述大部分组件。
在编译过程中,我们不可避免地遇到了很多平台兼容性的问题,比如关于 golang 系统调用 (syscall) 的兼容性问题, syscall.Stat_t 32 位 与 64 位类型转换,EpollEvent 修正位缺失等等。
构建 K8S-MIPS 组件主要使用了交叉编译技术。构建过程包括集成 QEMU 工具来实现 MIPS CPU 指令的转换。同时修改 Kubernetes 和 E2E 镜像的构建脚本,构建了 Hyperkube 和 MIPS 架构的 E2E 测试镜像。
成功构建出以上组件后,我们使用工具完成 Kubernetes 集群的搭建,比如 kubespray、kubeadm 等。
| 名称 | 版本 | MIPS 镜像仓库 |
|---|---|---|
| MIPS 版本 golang | 1.12.5 | - |
| MIPS 版本 docker-ce | 18.09.8 | - |
| MIPS 版本 CKE 构建 metrics-server | 0.3.2 | registry.inspurcloud.cn/library/cke/kubernetes/metrics-server-mips64el:v0.3.2 |
| MIPS 版本 CKE 构建 etcd | 3.2.26 | registry.inspurcloud.cn/library/cke/etcd/etcd-mips64el:v3.2.26 |
| MIPS 版本 CKE 构建 pause | 3.1 | registry.inspurcloud.cn/library/cke/kubernetes/pause-mips64el:3.1 |
| MIPS 版本 CKE 构建 hyperkube | 1.14.3 | registry.inspurcloud.cn/library/cke/kubernetes/hyperkube-mips64el:v1.14.3 |
| MIPS 版本 CKE 构建 coredns | 1.6.5 | registry.inspurcloud.cn/library/cke/kubernetes/coredns-mips64el:v1.6.5 |
| MIPS 版本 CKE 构建 calico | 3.8.0 | registry.inspurcloud.cn/library/cke/calico/cni-mips64el:v3.8.0 registry.inspurcloud.cn/library/cke/calico/ctl-mips64el:v3.8.0 registry.inspurcloud.cn/library/cke/calico/node-mips64el:v3.8.0 registry.inspurcloud.cn/library/cke/calico/kube-controllers-mips64el:v3.8.0 |
注: CKE 是浪潮推出的一款基于 Kubernetes 的容器云服务引擎
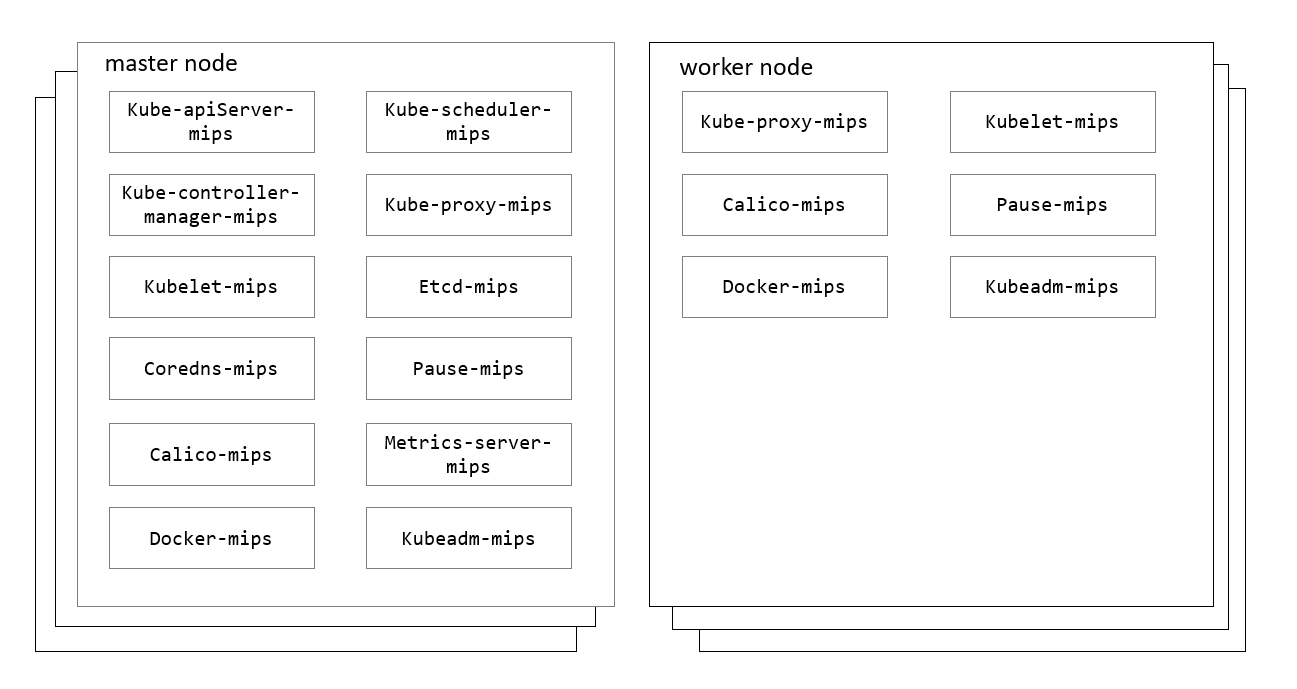
图二 K8S-MIPS 集群组件

图三 CPU 架构
图四 集群节点信息
运行 K8S 一致性测试
验证 K8S-MIP 集群稳定性和可用性最简单直接的方式是运行 Kubernetes 的 一致性测试。
一致性测试是一个独立的容器,用于启动 Kubernetes 端到端的一致性测试。
当执行一致性测试时,测试程序会启动许多 Pod 进行各种端到端的行为测试,这些 Pod 使用的镜像源码大部分来自于 kubernetes/test/images 目录下,构建的镜像位于 gcr.io/kubernetes-e2e-test-images/。由于镜像仓库中目前并不存在 MIPS 架构的镜像,我们要想运行 E2E 测试,必须首先构建出测试所需的全部镜像。
构建测试所需镜像
第一步是找到测试所需的所有镜像。我们可以执行 sonobuoy images-p e2e 命令来列出所有镜像,或者我们可以在 /test/utils/image/manifest.go 中找到这些镜像。尽管 Kubernetes 官方提供了完整的 Makefile 和 shell 脚本,为构建测试映像提供了命令,但是仍然有许多与体系结构相关的问题未能解决,比如基础映像和依赖包的不兼容问题。因此,我们无法通过直接执行这些构建命令来制作 mips64el 架构镜像。
多数测试镜像都是使用 golang 编写,然后编译出二进制文件,并基于相应的 Dockerfile 制作出镜像。这些镜像对我们来说可以轻松地制作出来。但是需要注意一点:测试镜像默认使用的基础镜像大多是 alpine, 目前 Alpine 官方并不支持 mips64el 架构,我们暂时未能自己制作出 mips64el 版本的 alpine 础镜像,只能将基础镜像替换为我们目前已有的 mips64el 基础镜像,比如 debian-stretch,fedora, ubuntu 等。替换基础镜像的同时也需要替换安装依赖包的命令,甚至依赖包的版本等。
有些测试所需镜像的源码并不在 kubernetes/test/images 下,比如 gcr.io/google-samples/gb-frontend:v6 等,没有明确的文档说明这类镜像来自于何方,最终还是在 github.com/GoogleCloudPlatform/kubernetes-engine-samples 这个仓库找到了原始的镜像源代码。但是很快我们遇到了新的问题,为了制作这些镜像,还要制作它依赖的基础镜像,甚至基础镜像的基础镜像,比如 php:5-apache、redis、perl 等等。
经过漫长庞杂的的镜像重制工作,我们完成了总计约 40 个镜像的制作 ,包括测试镜像以及直接和间接依赖的基础镜像。
最终我们将所有镜像在集群内准备妥当,并确保测试用例内所有 Pod 的镜像拉取策略设置为 imagePullPolicy: ifNotPresent。
这是我们构建出的部分镜像列表:
docker.io/library/busybox:1.29docker.io/library/nginx:1.14-alpinedocker.io/library/nginx:1.15-alpinedocker.io/library/perl:5.26docker.io/library/httpd:2.4.38-alpinedocker.io/library/redis:5.0.5-alpinegcr.io/google-containers/conformance:v1.16.2gcr.io/google-containers/hyperkube:v1.16.2gcr.io/google-samples/gb-frontend:v6gcr.io/kubernetes-e2e-test-images/agnhost:2.6gcr.io/kubernetes-e2e-test-images/apparmor-loader:1.0gcr.io/kubernetes-e2e-test-images/dnsutils:1.1gcr.io/kubernetes-e2e-test-images/echoserver:2.2gcr.io/kubernetes-e2e-test-images/ipc-utils:1.0gcr.io/kubernetes-e2e-test-images/jessie-dnsutils:1.0gcr.io/kubernetes-e2e-test-images/kitten:1.0gcr.io/kubernetes-e2e-test-images/metadata-concealment:1.2gcr.io/kubernetes-e2e-test-images/mounttest-user:1.0gcr.io/kubernetes-e2e-test-images/mounttest:1.0gcr.io/kubernetes-e2e-test-images/nautilus:1.0gcr.io/kubernetes-e2e-test-images/nonewprivs:1.0gcr.io/kubernetes-e2e-test-images/nonroot:1.0gcr.io/kubernetes-e2e-test-images/resource-consumer-controller:1.0gcr.io/kubernetes-e2e-test-images/resource-consumer:1.5gcr.io/kubernetes-e2e-test-images/sample-apiserver:1.10gcr.io/kubernetes-e2e-test-images/test-webserver:1.0gcr.io/kubernetes-e2e-test-images/volume/gluster:1.0gcr.io/kubernetes-e2e-test-images/volume/iscsi:2.0gcr.io/kubernetes-e2e-test-images/volume/nfs:1.0gcr.io/kubernetes-e2e-test-images/volume/rbd:1.0.1k8s.gcr.io/etcd:3.3.15k8s.gcr.io/pause:3.1
最终我们执行一致性测试并且得到了测试报告,包括 e2e.log,显示我们通过了全部的测试用例。此外,我们将测试结果以 pull request 的形式提交给了 k8s-conformance 。
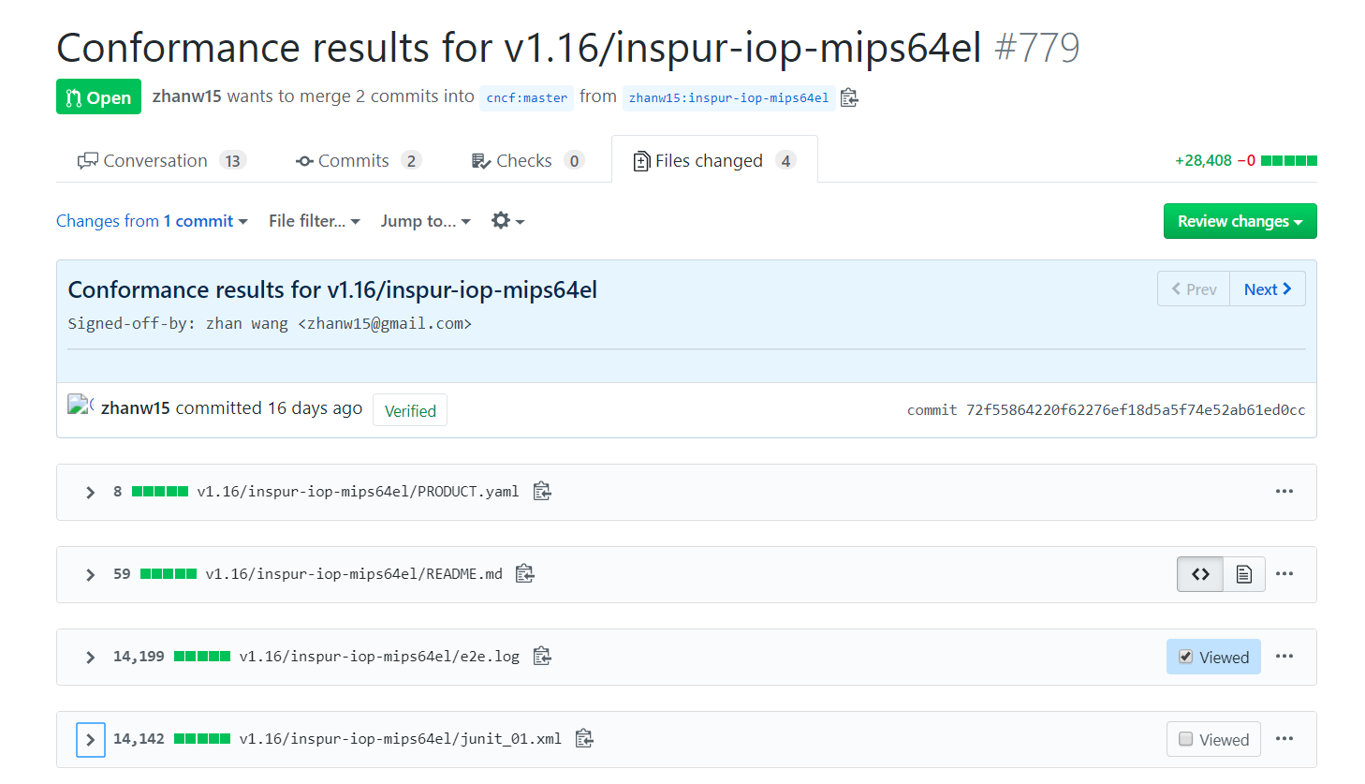
图五 一致性测试结果的 PR
后续计划
我们手动构建了 K8S-MIPS 组件以及执行了 E2E 测试,验证了 Kubernetes on MIPS 的可行性,极大的增强了我们对于推进 Kubernetes 支持 MIPS 架构的信心。
后续,我们将积极地向社区贡献我们的工作经验以及成果,提交 PR 以及 Patch For MIPS 等, 希望能够有更多的来自社区的力量加入进来,共同推进 Kubernetes for MIPS 的进程。
后续开源贡献计划:
- 贡献构建 E2E 测试镜像代码
- 贡献构建 MIPS 版本 hyperkube 代码
- 贡献构建 MIPS 版本 kubeadm 等集群部署工具
Kubernetes 1.17:稳定
我们高兴的宣布Kubernetes 1.17版本的交付,它是我们2019年的第四个也是最后一个发布版本。Kubernetes v1.17包含22个增强功能:有14个增强已经逐步稳定(stable),4个增强功能已经进入公开测试版(beta),4个增强功能刚刚进入内部测试版(alpha)。
主要的主题
云服务提供商标签基本可用
作为公开测试版特性添加到 v1.2 ,v1.17 中可以看到云提供商标签达到基本可用。
卷快照进入公开测试版
在 v1.17 中,Kubernetes卷快照特性是公开测试版。这个特性是在 v1.12 中以内部测试版引入的,第二个有重大变化的内部测试版是 v1.13 。
容器存储接口迁移公开测试版
在 v1.17 中,Kubernetes树内存储插件到容器存储接口(CSI)的迁移基础架构是公开测试版。容器存储接口迁移最初是在Kubernetes v1.14 中以内部测试版引入的。
云服务提供商标签基本可用
当节点和卷被创建,会基于基础云提供商的Kubernetes集群打上一系列标准标签。节点会获得一个实例类型标签。节点和卷都会得到两个描述资源在云提供商拓扑的位置标签,通常是以区域和地区的方式组织。
Kubernetes组件使用标准标签来支持一些特性。例如,调度者会保证pods和它们所声明的卷放置在相同的区域;当调度部署的pods时,调度器会优先将它们分布在不同的区域。你还可以在自己的pods标准中利用标签来配置,如节点亲和性,之类的事。标准标签使得你写的pod规范在不同的云提供商之间是可移植的。
在这个版本中,标签已经达到基本可用。Kubernetes组件都已经更新,可以填充基本可用和公开测试版标签,并对两者做出反应。然而,如果你的pod规范或自定义的控制器正在使用公开测试版标签,如节点亲和性,我们建议你可以将它们迁移到新的基本可用标签中。你可以从如下地方找到新标签的文档:
卷快照进入公开测试版
在 v1.17 中,Kubernetes卷快照是是公开测试版。最初是在 v1.12 中以内部测试版引入的,第二个有重大变化的内部测试版是 v1.13 。这篇文章总结它在公开版本中的变化。
卷快照是什么?
许多的存储系统(如谷歌云持久化磁盘,亚马逊弹性块存储和许多的内部存储系统)支持为持久卷创建快照。快照代表卷在一个时间点的复制。它可用于配置新卷(使用快照数据提前填充)或恢复卷到一个之前的状态(用快照表示)。
为什么给Kubernetes加入卷快照?
Kubernetes卷插件系统已经提供了功能强大的抽象用于自动配置、附加和挂载块文件系统。
支持所有这些特性是Kubernets负载可移植的目标:Kubernetes旨在分布式系统应用和底层集群之间创建一个抽象层,使得应用可以不感知其运行集群的具体信息并且部署也不需特定集群的知识。
Kubernetes存储特别兴趣组(SIG)将快照操作确定为对很多有状态负载的关键功能。如数据库管理员希望在操作数据库前保存数据库卷快照。
在Kubernetes接口中提供一种标准的方式触发快照操作,Kubernetes用户可以处理这种用户场景,而不必使用Kubernetes API(并手动执行存储系统的具体操作)。
取而代之的是,Kubernetes用户现在被授权以与集群无关的方式将快照操作放进他们的工具和策略中,并且确信它将对任意的Kubernetes集群有效,而与底层存储无关。
此外,Kubernetes 快照原语作为基础构建能力解锁了为Kubernetes开发高级、企业级、存储管理特性的能力:包括应用或集群级别的备份方案。
你可以阅读更多关于发布容器存储接口卷快照公开测试版
容器存储接口迁移公测版
为什么我们迁移内建树插件到容器存储接口?
在容器存储接口之前,Kubernetes提供功能强大的卷插件系统。这些卷插件是树内的意味着它们的代码是核心Kubernetes代码的一部分并附带在核心Kubernetes二进制中。然而,为Kubernetes添加插件支持新卷是非常有挑战的。希望在Kubernetes上为自己存储系统添加支持(或修复现有卷插件的bug)的供应商被迫与Kubernetes发行进程对齐。此外,第三方存储代码在核心Kubernetes二进制中会造成可靠性和安全问题,并且这些代码对于Kubernetes的维护者来说是难以(一些场景是不可能)测试和维护的。在Kubernetes上采用容器存储接口可以解决大部分问题。
随着更多容器存储接口驱动变成生产环境可用,我们希望所有的Kubernetes用户从容器存储接口模型中获益。然而,我们不希望强制用户以破坏现有基本可用的存储接口的方式去改变负载和配置。道路很明确,我们将不得不用CSI替换树内插件接口。什么是容器存储接口迁移?
在容器存储接口迁移上所做的努力使得替换现有的树内存储插件,如kubernetes.io/gce-pd或kubernetes.io/aws-ebs,为相应的容器存储接口驱动成为可能。如果容器存储接口迁移正常工作,Kubernetes终端用户不会注意到任何差别。迁移过后,Kubernetes用户可以继续使用现有接口来依赖树内存储插件的功能。
当Kubernetes集群管理者更新集群使得CSI迁移可用,现有的有状态部署和工作负载照常工作;然而,在幕后Kubernetes将存储管理操作交给了(以前是交给树内驱动)CSI驱动。
Kubernetes组非常努力地保证存储接口的稳定性和平滑升级体验的承诺。这需要细致的考虑现有特性和行为来确保后向兼容和接口稳定性。你可以想像成在加速行驶的直线上给赛车换轮胎。
你可以在这篇博客中阅读更多关于容器存储接口迁移成为公开测试版.
其它更新
稳定💯
- 按条件污染节点
- 可配置的Pod进程共享命名空间
- 采用kube-scheduler调度DaemonSet Pods
- 动态卷最大值
- Kubernetes容器存储接口支持拓扑
- 在SubPath挂载提供环境变量扩展
- 为Custom Resources提供默认值
- 从频繁的Kublet心跳到租约接口
- 拆分Kubernetes测试Tarball
- 添加Watch书签支持
- 行为驱动一致性测试
- 服务负载均衡终结保护
- 避免每一个Watcher独立序列化相同的对象
主要变化
其它显著特性
可用性
Kubernetes 1.17 可以在GitHub下载。开始使用Kubernetes,看看这些交互教学。你可以非常容易使用kubeadm安装1.17。
发布团队
正是因为有上千人参与技术或非技术内容的贡献才使这个版本成为可能。特别感谢由Guinevere Saenger领导的发布团队。发布团队的35名成员在发布版本的多方面进行了协调,从文档到测试,校验和特性的完善。
随着Kubernetes社区的成长,我们的发布流程是在开源软件协作方面惊人的示例。Kubernetes快速并持续获得新用户。这一成长产生了良性的反馈循环,更多的贡献者贡献代码创造了更加活跃的生态。Kubernetes已经有超过39000位贡献者和一个超过66000人的活跃社区。
网络研讨会
2020年1月7号,加入Kubernetes 1.17发布团队,学习关于这次发布的主要特性。这里注册。
参与其中
最简单的参与Kubernetes的方式是加入其中一个与你兴趣相同的特别兴趣组(SIGs)。有什么想要广播到Kubernetes社区吗?通过如下的频道,在每周的社区会议分享你的声音。感谢你的贡献和支持。
- 在Twitter上关注我们@Kubernetesio获取最新的更新
- 在Discuss参与社区的讨论
- 在Slack加入社区
- 在Stack Overflow发布问题(或回答问题)
- 分享你的Kubernetes故事
使用 Java 开发一个 Kubernetes controller
作者: Min Kim (蚂蚁金服), Tony Ado (蚂蚁金服)
Kubernetes Java SDK 官方项目最近发布了他们的最新工作,为 Java Kubernetes 开发人员提供一个便捷的 Kubernetes 控制器-构建器 SDK,它有助于轻松开发高级工作负载或系统。
综述
Java 无疑是世界上最流行的编程语言之一,但由于社区中缺少库资源,一段时间以来,那些非 Golang 开发人员很难构建他们定制的 controller/operator。在 Golang 的世界里,已经有一些很好的 controller 框架了,例如,controller runtime,operator SDK。这些现有的 Golang 框架依赖于 Kubernetes Golang SDK 提供的各种实用工具,这些工具经过多年证明是稳定的。受进一步集成到 Kubernetes 平台的需求驱动,我们不仅将 Golang SDK 中的许多基本工具移植到 kubernetes Java SDK 中,包括 informers、work-queues、leader-elections 等,也开发了一个控制器构建 SDK,它可以将所有东西连接到一个可运行的控制器中,而不会产生任何问题。
背景
为什么要使用 Java 实现 kubernetes 工具?选择 Java 的原因可能是:
-
集成遗留的企业级 Java 系统:许多公司的遗留系统或框架都是用 Java 编写的,用以支持稳定性。我们不能轻易把所有东西搬到 Golang。
-
更多开源社区的资源:Java 是成熟的,并且在过去几十年中累计了丰富的开源库,尽管 Golang 对于开发人员来说越来越具有吸引力,越来越流行。此外,现在开发人员能够在 SQL 存储上开发他们的聚合-apiserver,而 Java 在 SQL 上有更好的支持。
如何去使用
以 maven 项目为例,将以下依赖项添加到您的依赖中:
<dependency>
<groupId>io.kubernetes</groupId>
<artifactId>client-java-extended</artifactId>
<version>6.0.1</version>
</dependency>
然后我们可以使用提供的生成器库来编写自己的控制器。例如,下面是一个简单的控制,它打印出关于监视通知的节点信息,请看完整的例子:
...
Reconciler reconciler = new Reconciler() {
@Override
public Result reconcile(Request request) {
V1Node node = nodeLister.get(request.getName());
System.out.println("triggered reconciling " + node.getMetadata().getName());
return new Result(false);
}
};
Controller controller =
ControllerBuilder.defaultBuilder(informerFactory)
.watch(
(workQueue) -> ControllerBuilder.controllerWatchBuilder(V1Node.class, workQueue).build())
.withReconciler(nodeReconciler) // required, set the actual reconciler
.withName("node-printing-controller") // optional, set name for controller for logging, thread-tracing
.withWorkerCount(4) // optional, set worker thread count
.withReadyFunc( nodeInformer::hasSynced) // optional, only starts controller when the cache has synced up
.build();
如果您留意,新的 Java 控制器框架很多地方借鉴于 controller-runtime 的设计,它成功地将控制器内部的复杂组件封装到几个干净的接口中。在 Java 泛型的帮助下,我们甚至更进一步,以更好的方式简化了封装。
我们可以将多个控制器封装到一个 controller-manager 或 leader-electing controller 中,这有助于在 HA 设置中进行部署。
未来计划
Kubernetes Java SDK 项目背后的社区将专注于为希望编写云原生 Java 应用程序来扩展 Kubernetes 的开发人员提供更有用的实用程序。如果您对更详细的信息感兴趣,请查看我们的仓库 kubernetes-client/java。请通过问题或 Slack 与我们分享您的反馈。
使用 Microk8s 在 Linux 上本地运行 Kubernetes
作者: Ihor Dvoretskyi,开发支持者,云原生计算基金会;Carmine Rimi
本文是关于 Linux 上的本地部署选项系列的第二篇,涵盖了 MicroK8s。Microk8s 是本地部署 Kubernetes 集群的 'click-and-run' 方案,最初由 Ubuntu 的发布者 Canonical 开发。
虽然 Minikube 通常为 Kubernetes 集群创建一个本地虚拟机(VM),但是 MicroK8s 不需要 VM。它使用snap 包,这是一种应用程序打包和隔离技术。
这种差异有其优点和缺点。在这里,我们将讨论一些有趣的区别,并且基于 VM 的方法和非 VM 方法的好处。第一个因素是跨平台的移植性。虽然 Minikube VM 可以跨操作系统移植——它不仅支持 Linux,还支持 Windows、macOS、甚至 FreeBSD,但 Microk8s 需要 Linux,而且只在那些支持 snaps 的发行版上。支持大多数流行的 Linux 发行版。
另一个考虑到的因素是资源消耗。虽然 VM 设备为您提供了更好的可移植性,但它确实意味着您将消耗更多资源来运行 VM,这主要是因为 VM 提供了一个完整的操作系统,并且运行在管理程序之上。当 VM 处于休眠时你将消耗更多的磁盘空间。当它运行时,你将会消耗更多的 RAM 和 CPU。因为 Microk8s 不需要创建虚拟机,你将会有更多的资源去运行你的工作负载和其他设备。考虑到所占用的空间更小,MicroK8s 是物联网设备的理想选择-你甚至可以在 Paspberry Pi 和设备上使用它!
最后,项目似乎遵循了不同的发布节奏和策略。Microk8s 和 snaps 通常提供渠道允许你使用测试版和发布 KUbernetes 新版本的候选版本,同样也提供先前稳定版本。Microk8s 通常几乎立刻发布 Kubernetes 上游的稳定版本。
但是等等,还有更多!Minikube 和 Microk8s 都是作为单节点集群启动的。本质上来说,它们允许你用单个工作节点创建 Kubernetes 集群。这种情况即将改变 - MicroK8s 早期的 alpha 版本包括集群。有了这个能力,你可以创建正如你希望多的工作节点的 KUbernetes 集群。对于创建集群来说,这是一个没有主见的选项 - 开发者在节点之间创建网络连接和集成了其他所需要的基础设施,比如一个外部的负载均衡。总的来说,MicroK8s 提供了一种快速简易的方法,使得少量的计算机和虚拟机变成一个多节点的 Kubernetes 集群。以后我们将撰写更多这种体系结构的文章。
免责声明
这不是 MicroK8s 官方介绍文档。你可以在它的官方网页查询运行和使用 MicroK8s 的详情信息,其中覆盖了不同的用例,操作系统,环境等。相反,这篇文章的意图是提供在 Linux 上运行 MicroK8s 清晰易懂的指南。
前提条件
一个支持 snaps 的 Linux 发行版是被需要的。这篇指南,我们将会用支持 snaps 且即开即用的 Ubuntu 18.04 LTS。如果你对运行在 Windows 或者 Mac 上的 MicroK8s 感兴趣,你应该检查多通道,安装一个快速的 Ubuntu VM,作为在你的系统上运行虚拟机 Ubuntu 的官方方式。
MicroK8s 安装
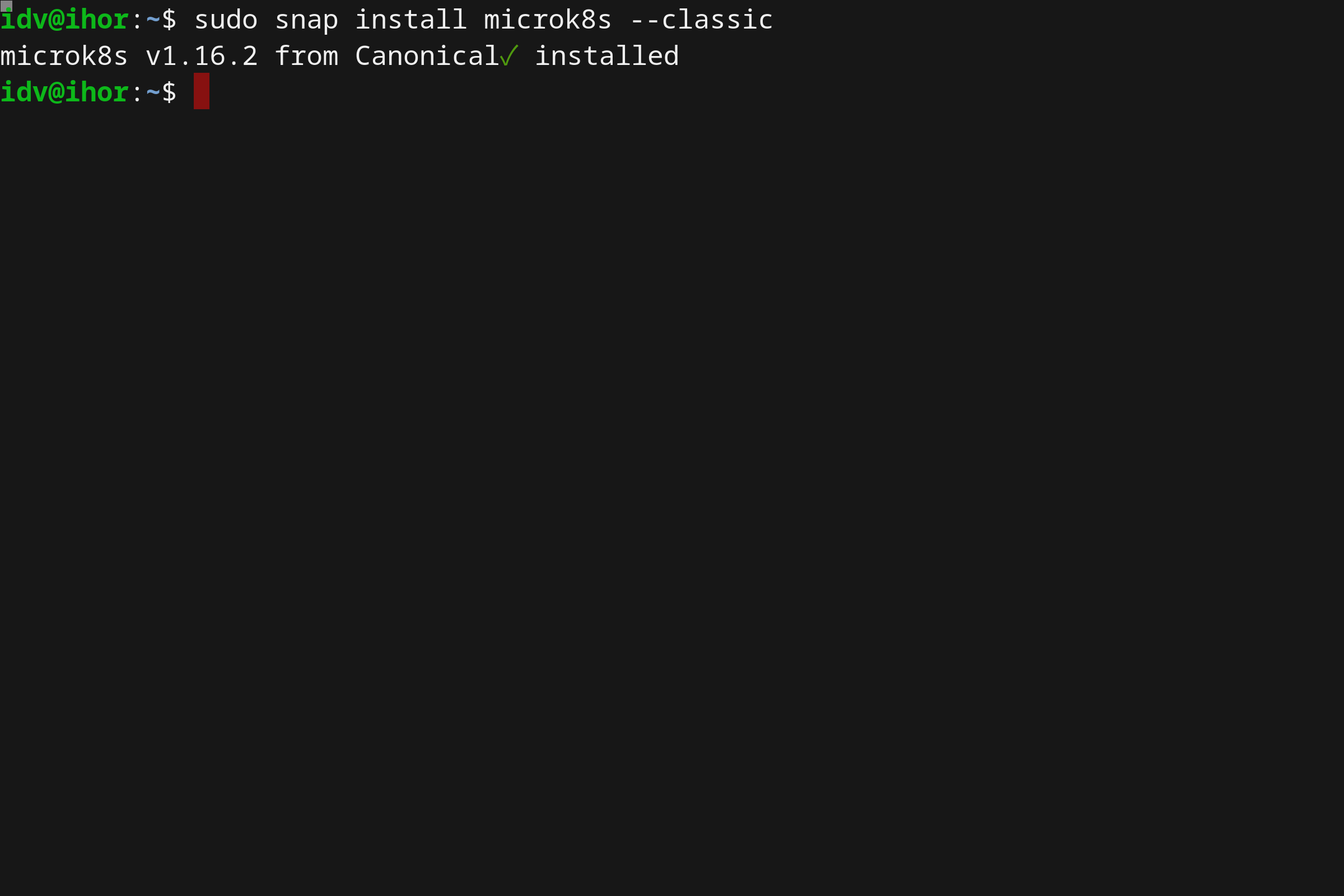
简洁的 MicroK8s 安装:
sudo snap install microk8s --classic
使用 microk8s
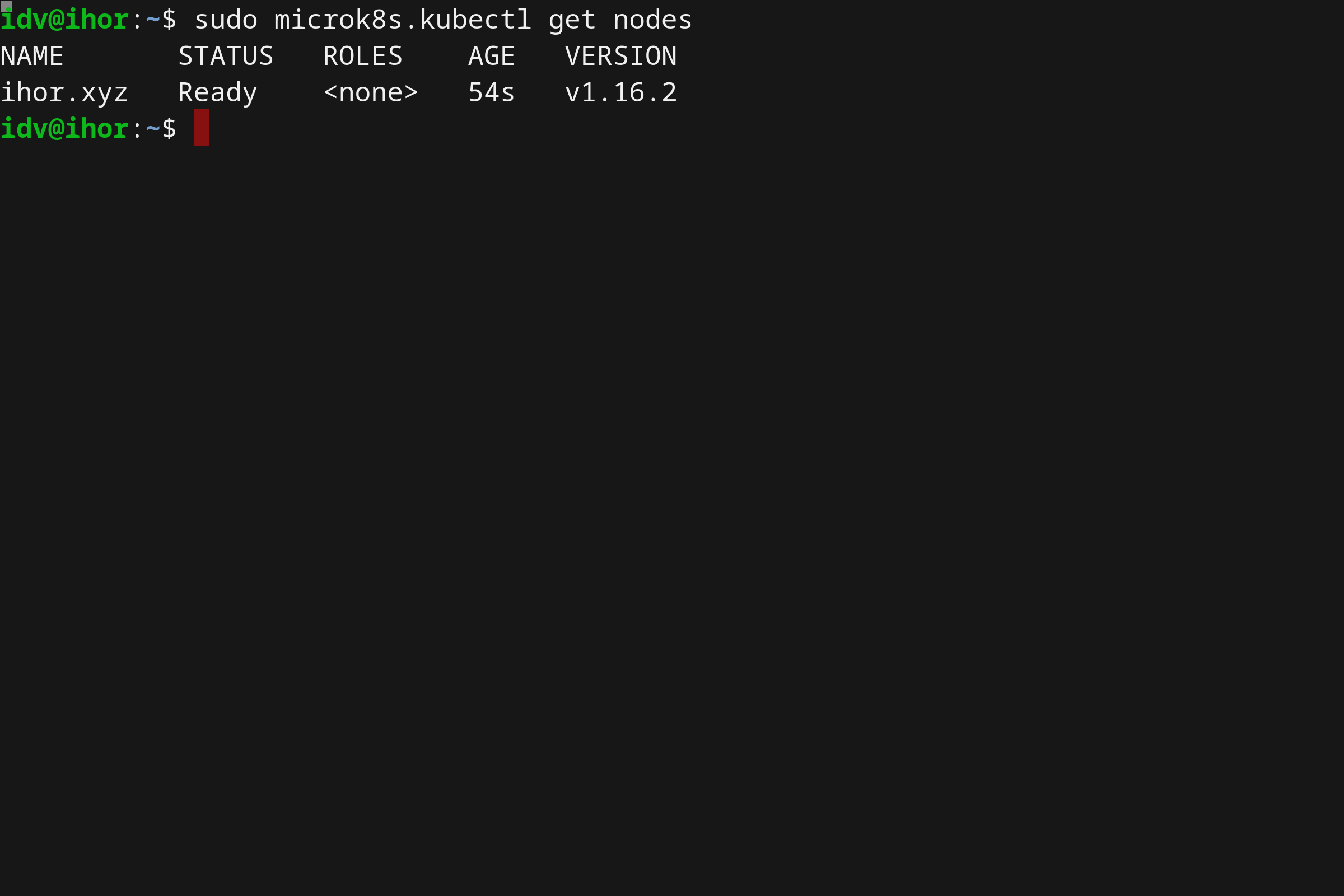
使用 MicrosK8s 就像和安装它一样便捷。MicroK8s 本身包括一个 kubectl 库,该库可以通过执行 microk8s.kubectl 命令去访问。例如:
microk8s.kubectl get nodes
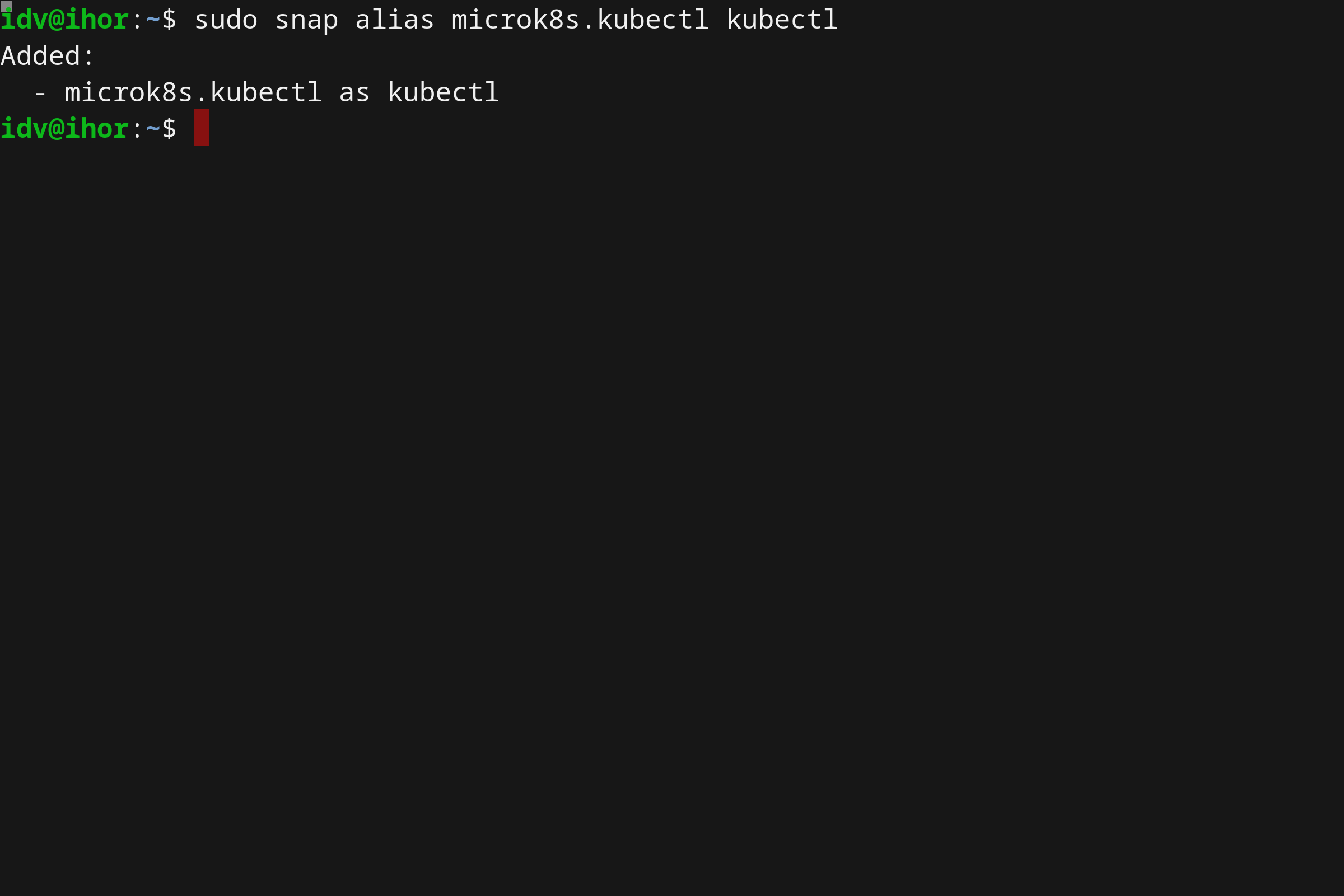
当使用前缀 microk8s.kubectl 时,允许在没有影响的情况下并行地安装另一个系统级的 kubectl,你可以便捷地使用 snap alias 命令摆脱它:
sudo snap alias microk8s.kubectl kubectl
这将允许你以后便捷地使用 kubectl,你可以用 snap unalias命令恢复这个改变。
kubectl get nodes
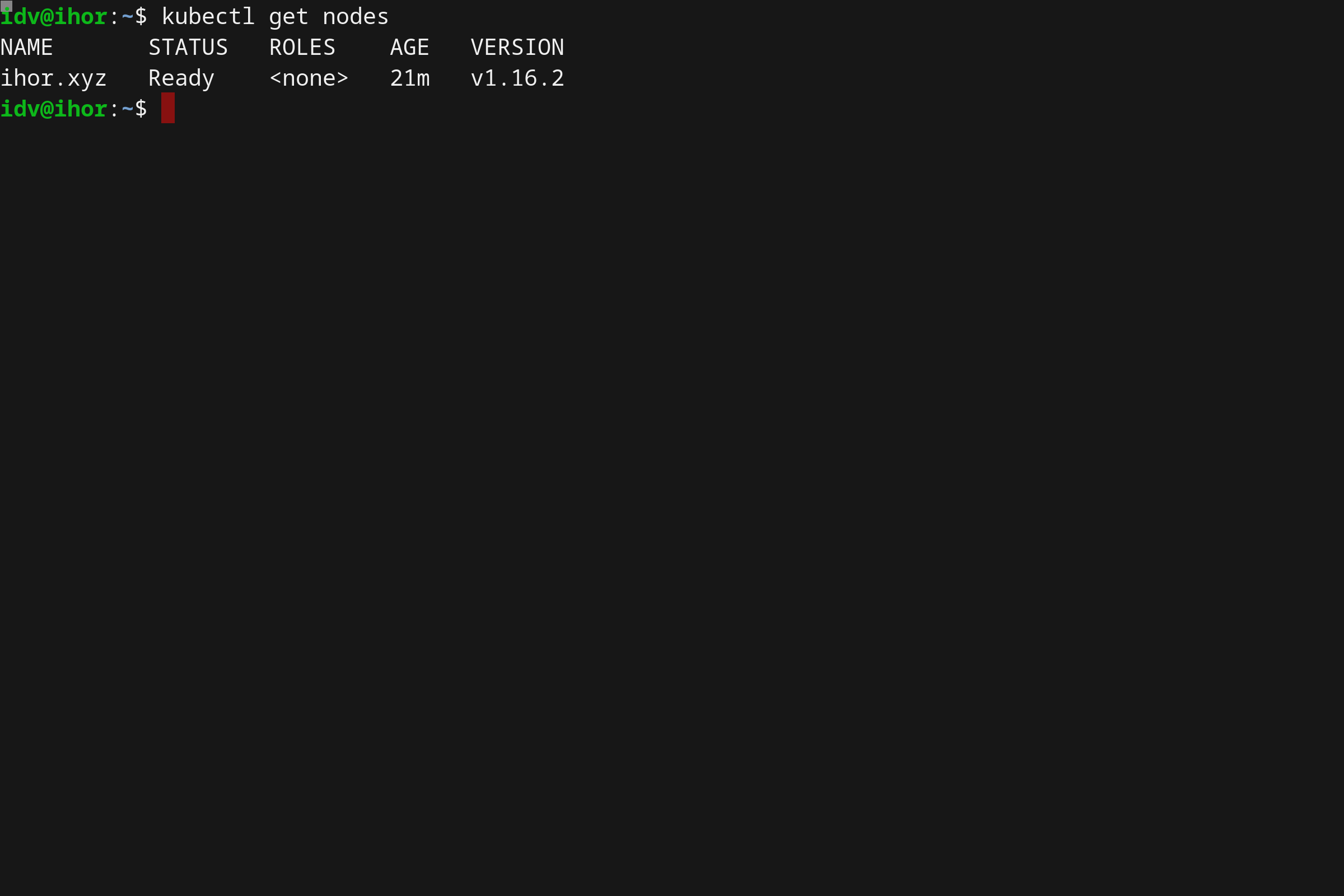
MicroK8s 插件
使用 MicroK8s 其中最大的好处之一事实上是也支持各种各样的插件和扩展。更重要的是它们是开箱即用的,用户仅仅需要启动它们。通过运行 microk8s.status 命令检查出扩展的完整列表。
sudo microk8s.status
截至到写这篇文章为止,MicroK8s 已支持以下插件:
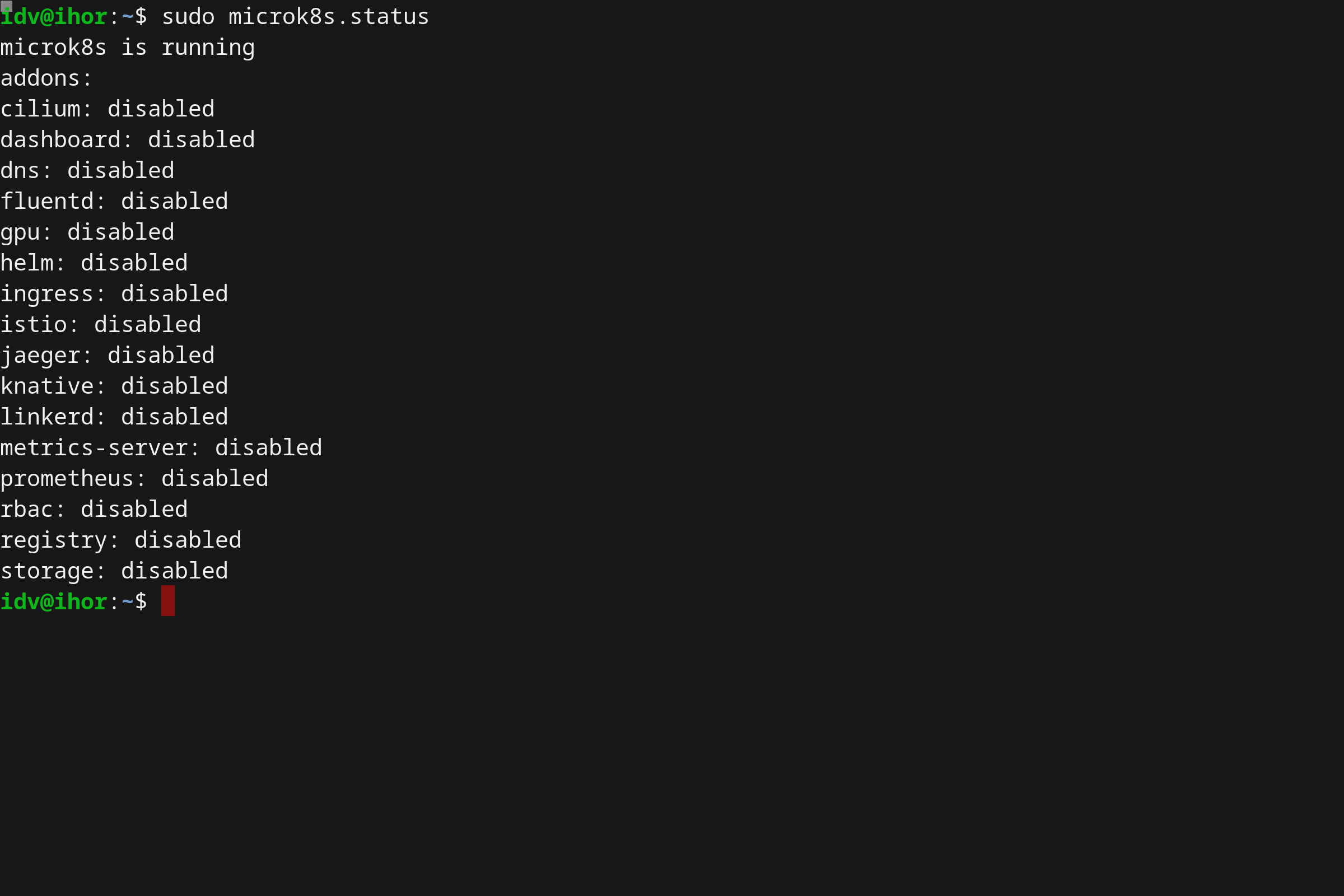
社区创建和贡献了越来越多的插件,经常检查他们是十分有帮助的。
发布渠道
sudo snap info microk8s
安装简单的应用
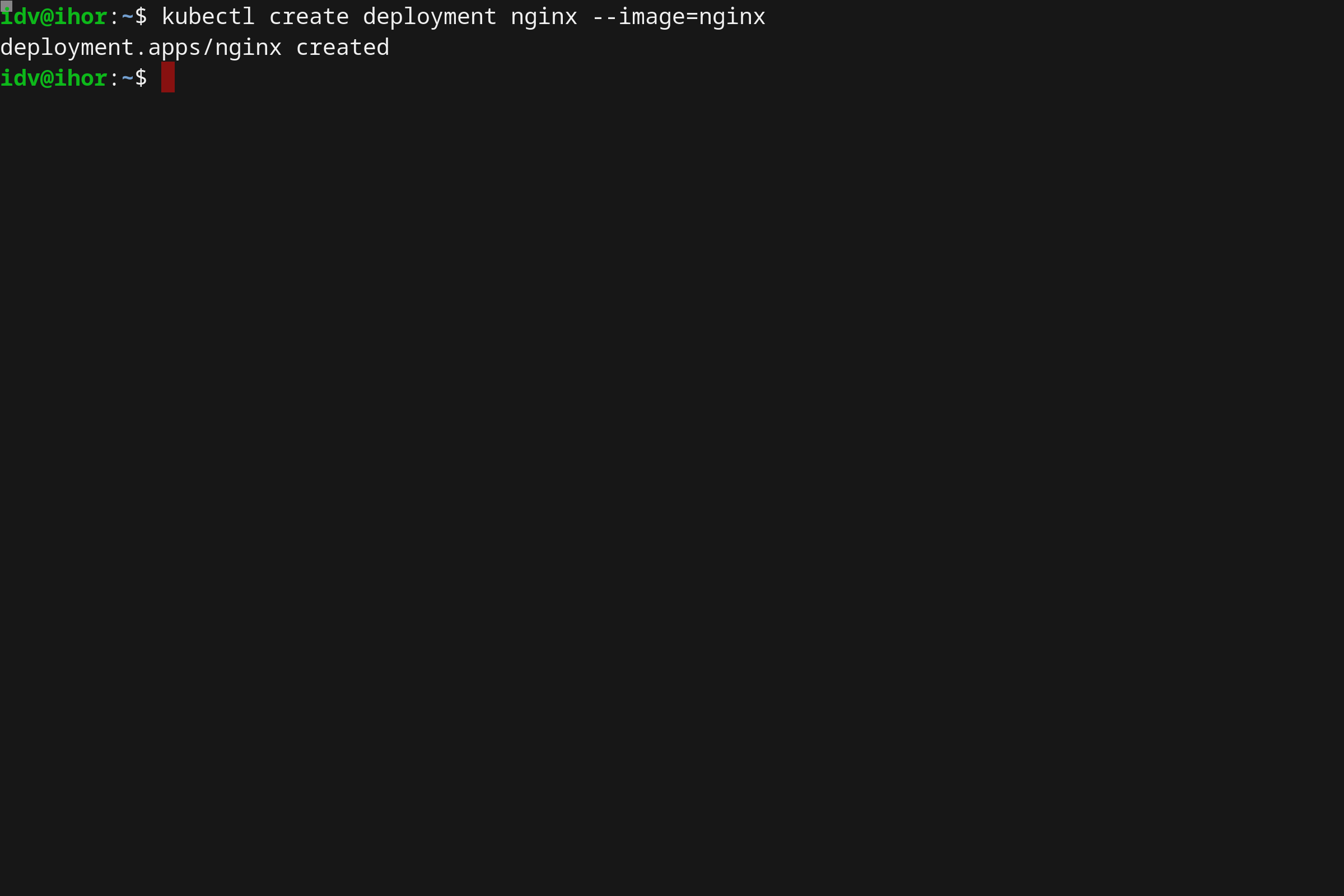
在这篇指南中我将会用 NGINX 作为一个示例应用程序(官方 Docker Hub 镜像)。
kubectl create deployment nginx --image=nginx
为了检查安装,让我们运行以下命令:
kubectl get deployments
kubectl get pods
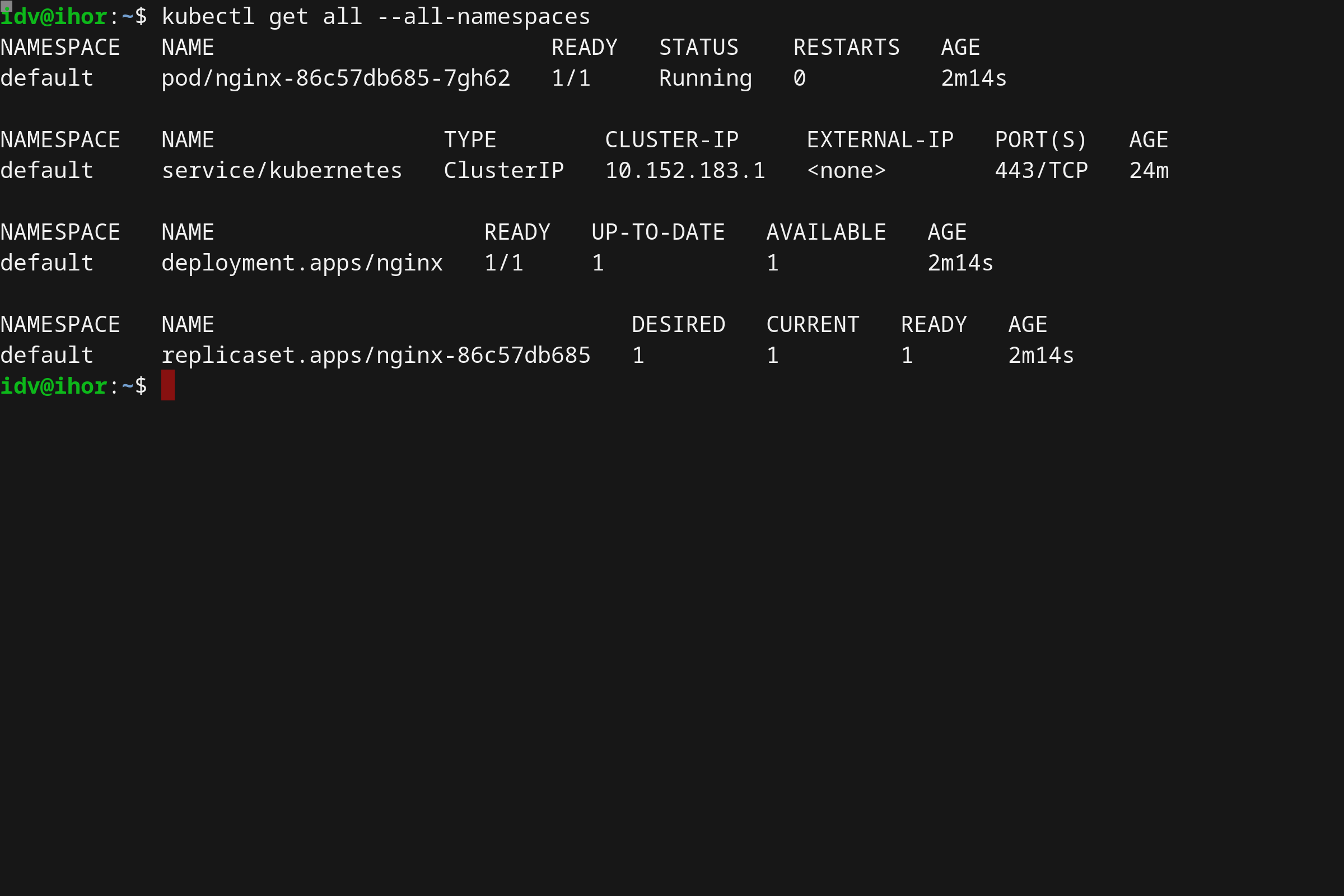
我们也可以检索出 Kubernetes 集群中所有可用对象的完整输出。
kubectl get all --all-namespaces
卸载 MircroK8s
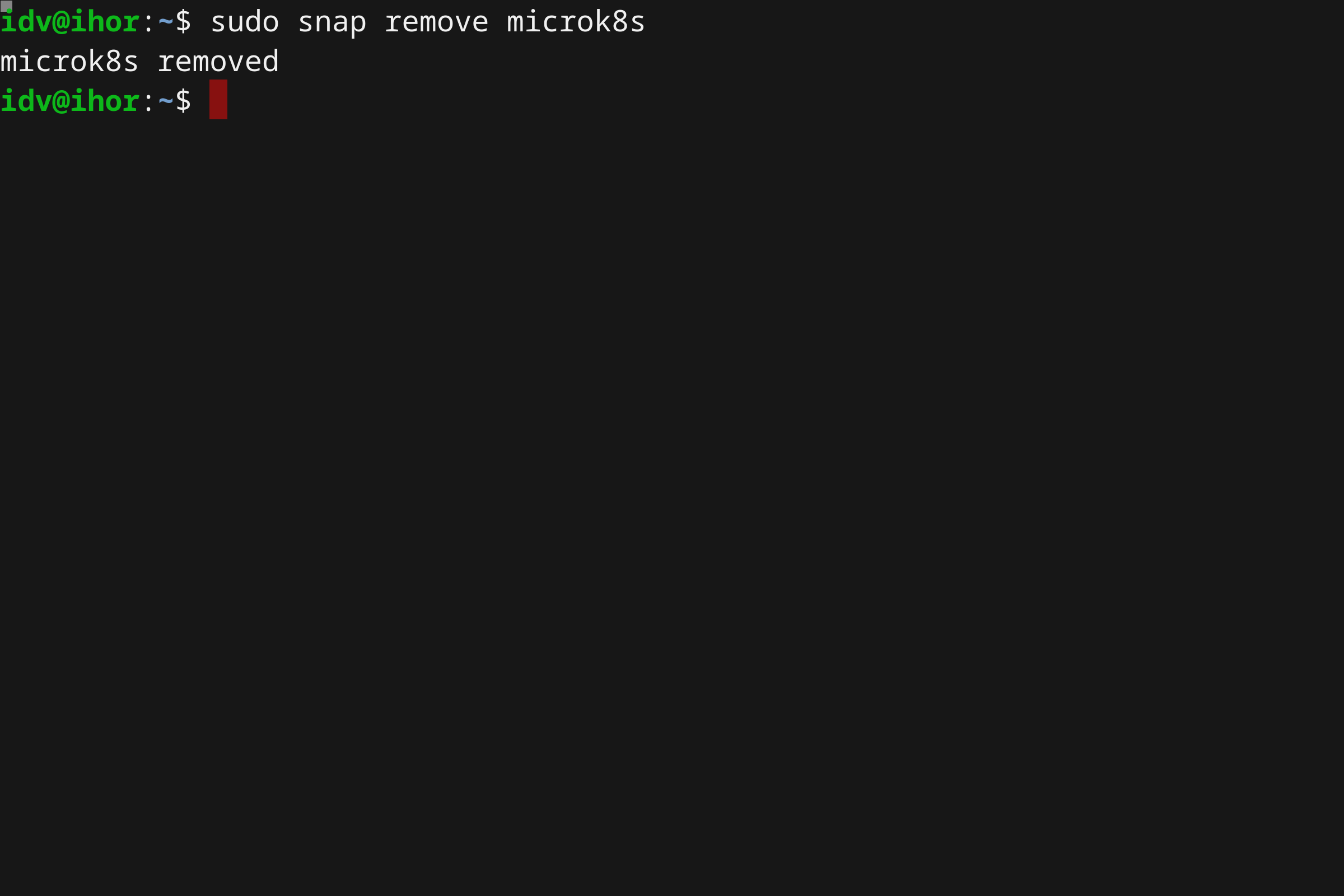
卸载您的 microk8s 集群与卸载 Snap 同样便捷。
sudo snap remove microk8s
截屏视频

Kubernetes 文档最终用户调研
Author: Aimee Ukasick and SIG Docs
9月,SIG Docs 进行了第一次关于 Kubernetes 文档的用户调研。我们要感谢 CNCF 的 Kim McMahon 帮助我们创建调查并获取结果。
主要收获
受访者希望能在概念、任务和参考部分得到更多示例代码、更详细的内容和更多图表。
74% 的受访者希望教程部分包含高级内容。
69.70% 的受访者认为 Kubernetes 文档是他们首要寻找关于 Kubernetes 资料的地方。
调查方法和受访者
我们用英语进行了调查。由于时间限制,调查的有效期只有 4 天。 我们在 Kubernetes 邮件列表、Kubernetes Slack 频道、Twitter、Kube Weekly 上发布了我们的调查问卷。 这份调查有 23 个问题, 受访者平均用 4 分钟完成这个调查。
关于受访者的简要情况
- 48.48% 是经验丰富的 Kubernetes 用户,26.26% 是专家,25.25% 是初学者
- 57.58% 的人同时使用 Kubernetes 作为管理员和开发人员
- 64.65% 的人使用 Kubernetes 文档超过 12 个月
- 95.96% 的人阅读英文文档
问题和回答要点
人们为什么访问 Kubernetes 文档
大多数受访者表示,他们访问文档是为了了解概念。
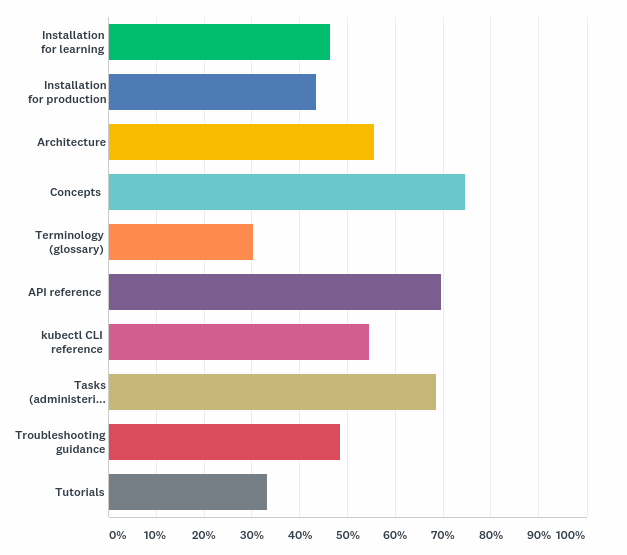
这与我们在 Google Analytics 上看到的略有不同:在今年浏览量最多的10个页面中,第一是在参考部分的 kubectl 的备忘单,其次是概念部分的页面。
对文档的满意程度
我们要求受访者从概念、任务、参考和教程部分记录他们对细节的满意度:
- 概念:47.96% 中等满意
- 任务:50.54% 中等满意
- 参考:40.86% 非常满意
- 教程:47.25% 中等满意
SIG Docs 如何改进文档的各个部分
我们询问如何改进每个部分,为受访者提供可选答案以及文本输入框。绝大多数人想要更多 示例代码、更详细的内容、更多图表和更高级的教程:
- 就个人而言,希望看到更多的类比,以帮助进一步理解。
- 如果代码的相应部分也能解释一下就好了
- 通过扩展概念把它们融合在一起 - 它们现在宛如在一桶水内朝各个方向游动的一条条鳗鱼。
- 更多的图表,更多的示例代码
受访者使用“其他”文本框记录引发阻碍的区域:
- 使概念保持最新和准确
- 保持任务主题的最新性和准确性。亲身试验。
- 彻底检查示例。很多时候显示的命令输出不是实际情况。
- 我从来都不知道如何导航或解释参考部分
- 使教程保持最新,或将其删除
SIG Docs 如何全面改进文档
我们询问受访者如何从整体上改进 Kubernetes 文档。一些人抓住这次机会告诉我们我们正在做一个很棒的 工作:
- 对我而言,这是我见过的文档最好的开源项目。
- 继续努力!
- 我觉得文档很好。
- 你们做得真好。真的。
其它受访者提供关于内容的反馈:
- ...但既然我们谈论的是文档,多多益善。更多的高级配置示例对我来说将是最好的选择。比如每个配置主题的用例页面,
从初学者到高级示例场景。像这样的东西真的是令人惊叹......
- 更深入的例子和用例将是很好的。我经常感觉 Kubernetes 文档只是触及了一个主题的表面,这可能对新用户很好,
但是它没有让更有经验的用户获取多少关于如何实现某些东西的“官方”指导。
- 资源节(特别是 secrets)希望有更多类似于产品的示例或指向类似产品的示例的链接
- 如果能像很多其它技术项目那样有非常清晰的“快速启动” 逐步教学完成搭建就更好了。现有的快速入门内容屈指可数,
也没有统一的指南。结果是信息泛滥。
少数受访者提供的技术建议:
- 使用 ReactJS 或者 Angular component 使表的列可排序和可筛选。
- 对于大多数人来说,我认为用 Hugo - 一个静态站点生成系统 - 创建文档是不合适的。有更好的系统来记录大型软件项目。
具体来说,我希望看到 k8s 切换到 Sphinx 来获取文档。Sphinx 有一个很好的内置搜索。如果你了解 markdown,学习起来也很容易。
Sphinx 被其他项目广泛采用(例如,在 readthedocs.io、linux kernel、docs.python.org 等等)。
总体而言,受访者提供了建设性的批评,其关注点是高级用例以及更深入的示例、指南和演练。
哪里可以看到更多
调查结果摘要、图表和原始数据可在 kubernetes/community sig-docs
survey
目录下。
圣迭戈贡献者峰会日程公布!
作者:Josh Berkus (Red Hat), Paris Pittman (Google), Jonas Rosland (VMware)
一周前,我们宣布贡献者峰会开放注册,现在我们已经完成了整个贡献者峰会的日程安排!趁现在还有票,马上抢占你的位置。这里有一个新贡献者研讨会的等待名单。 (点击这里注册!)
除了新贡献者研讨会之外,贡献者峰会还安排了许多精彩的会议,这些会议分布在当前五个贡献者内容的会议室中。由于这是一个上游贡献者峰会,并且我们不经常见面,所以作为一个全球分布的团队,这些会议大多是讨论或动手实践,而不仅仅是演示。我们希望大家互相学习,并于他们的开源代码队友玩的开心。
像去年一样,非组织会议将重新开始,会议将在周一上午进行选择。对于最新的热门话题和贡献者想要进行的特定讨论,这是理想的选择。在过去的几年中,我们涵盖了不稳定的测试,集群生命周期,KEP(Kubernetes增强建议),指导,安全性等等。

尽管在每个时间间隙日程安排都包含困难的决定,但我们选择了以下几点,让您体验一下您将在峰会上听到、看到和参与的内容:
- 预见: SIG组织将分享他们对于明年和以后Kubernetes开发发展方向的认识。
- 安全: Tim Allclair和CJ Cullen将介绍Kubernetes安全的当前情况。在另一个安全性演讲中,Vallery Lancey将主持有关使我们的平台默认情况下安全的讨论。
- Prow: 有兴趣与Prow合作并为Test-Infra做贡献,但不确定从哪里开始? Rob Keilty将帮助您在笔记本电脑上运行Prow测试环境
- Git: GitHub的员工将与Christoph Blecker合作,为Kubernetes贡献者分享实用的Git技巧。
- 审阅: 蒂姆·霍金(Tim Hockin)将分享成为一名出色的代码审阅者的秘密,而乔丹·利吉特(Jordan Liggitt)将进行实时API审阅,以便您可以进行一次或至少了解一次审阅。
- 终端用户: 应Cheryl Hung邀请,来自CNCF合作伙伴生态的数个终端用户,将回答贡献者的问题,以加强我们的反馈循环。
- 文档: 与往常一样,SIG-Docs将举办一个为时三个小时的文档撰写研讨会。
我们还将向在2019年杰出的贡献者颁发奖项,周一星期一结束时将有一个巨大的见面会,供新的贡献者找到他们的SIG(以及现有的贡献者询问他们的PR)。
希望能够在峰会上见到您,并且确保您已经提前注册!
2019 指导委员会选举结果
作者:Bob Killen (University of Michigan), Jorge Castro (VMware), Brian Grant (Google), and Ihor Dvoretskyi (CNCF)
2019 指导委员会选举 是 Kubernetes 项目的重要里程碑。最初的自助委员会正逐步退休,现在该委员会已缩减到最后分配的 7 个席位。指导委员会的所有成员现在都由 Kubernetes 社区选举产生。
接下来的选举将选出 3 到 4 名委员,任期两年。
选举结果
Kubernetes 指导委员会选举现已完成,以下候选人提前获得立即开始的两年任期 (按 GitHub handle 的字母顺序排列) :
- Christoph Blecker (@cblecker), Red Hat
- Derek Carr (@derekwaynecarr), Red Hat
- Nikhita Raghunath (@nikhita), Loodse
- Paris Pittman (@parispittman), Google
他们加入了 Aaron Crickenberger (@spiffxp), Google;Davanum Srinivas (@dims),VMware; and Timothy St. Clair (@timothysc), VMware,使得委员会更圆满。Aaron、Davanum 和 Timothy 占据的这些席位将会在明年的这个时候进行选举。
诚挚的感谢!
- 感谢最初的引导委员会创立了最初项目的管理并监督了多年的过渡期:
- Joe Beda (@jbeda), VMware
- Brendan Burns (@brendandburns), Microsoft
- Clayton Coleman (@smarterclayton), Red Hat
- Brian Grant (@bgrant0607), Google
- Tim Hockin (@thockin), Google
- Sarah Novotny (@sarahnovotny), Microsoft
- Brandon Philips (@philips), Red Hat
- 同样感谢其他的已退休指导委员会成员。社区对你们先前的服务表示赞赏:
- Quinton Hoole (@quinton-hoole), Huawei
- Michelle Noorali (@michelleN), Microsoft
- Phillip Wittrock (@pwittrock), Google
- 感谢参选的候选人。 愿在每次选举中,我们都能拥有一群像您一样推动社区向前发展的人。
- 感谢所有投票的377位选民。
- 最后,感谢康奈尔大学举办的 CIVS!
参与指导委员会
你可以跟进指导委员会的 代办事项,通过提出问题或者向 仓库 提交一个 pr 。他们每两周一次,在 UTC 时间周三晚上 8 点 会面,并定期与我们的贡献者见面。也可以通过他们的公共邮件列表 steering@kubernetes.io 联系他们。
指导委员会会议:
San Diego 贡献者峰会开放注册!
作者:Paris Pittman (Google), Jeffrey Sica (Red Hat), Jonas Rosland (VMware)
2019 San Diego 贡献者峰会活动页面 注册已经开放,并且在创纪录的时间内,新贡献者研讨会 活动已满员!候补名单已经开放。
11月17日,星期日
晚间贡献者庆典:
QuartYard*
地址: 1301 Market Street, San Diego, CA 92101
时间: 下午6:00 - 下午9:00
11月18日,星期一
全天贡献者峰会:
Marriott Marquis San Diego Marina
地址: 333 W Harbor Dr, San Diego, CA 92101
时间: 上午9:00 - 下午5:00
虽然 Kubernetes 项目只有五年的历史,但是在 KubeCon + CloudNativeCon 之前,今年11月在圣迭戈时我们举办的第九届贡献者峰会了。快速增长的原因是在我们之前所做的北美活动中增加了欧洲和亚洲贡献者峰会。我们将继续在全球举办贡献者峰会,因为重要的是,我们的贡献者要以各种形式的多样性地成长。
Kubernetes 拥有一个庞大的分布式远程贡献团队,由来自世界各地的 个人和组织 组成。贡献者峰会每年为社区提供三次聚会的机会,围绕社区主题开展工作,并有互相了解的时间。即将举行的 San Diego 峰会预计将吸引 450 多名与会者,并将包含多个方向,适合所有人。重点将围绕贡献者的增长和可持续性。我们将在这里停留,为举行未来峰会做准备;我们希望这次活动为个人和项目提供价值。我们已经从峰会与会者的反馈中得知,完成工作、学习和与人们面对面交流是当务之急。通过限制参加人数并在更多地方提供贡献者聚会,将有助于我们实现这些目标。
这次峰会是独一无二的,因为我们在贡献者体验活动团队的坚持自我方面已采取了重大举措。从发行团队的手册中摘录,我们添加了其他核心团队和跟随学习角色,使其成为天然的辅导关系(包括监督和实施)。预计跟随学习者将在 2020 年的三项活动中扮演另一个角色,核心团队成员将带头完成。为这个团队做准备,我们开源了 技术手册,指南,最佳做法,并开放了 会议 和 项目委员会。我们的团队组成了 Kubernetes 项目的许多部分,并确保所有声音都得到体现。
您是否已经在 KubeCon + CloudNativeCon 上,但无法参与会议? 在 KubeCon + CloudNativeCon 期间查看 SIG入门和深潜课程 参与问答,并听取每个特殊兴趣小组(SIG)的最新消息。活动结束后,我们还将记录所有贡献者峰会的课题,在讨论中做笔记,并与您分享。
我们希望能在 San Diego 的 Kubernetes 贡献者峰会上与大家见面,确保您直接进入并点击 立即注册! 此活动将关闭 - 特此提醒。 :笑脸:
查看往期博客有关 围绕我们的活动构建角色 和 巴塞罗那峰会故事。
*=QuartYard 有一个巨大的舞台!想要在您的贡献者同行面前做点什么?加入我们吧! community@kubernetes.io
OPA Gatekeeper:Kubernetes 的策略和管理
作者: Rita Zhang (Microsoft), Max Smythe (Google), Craig Hooper (Commonwealth Bank AU), Tim Hinrichs (Styra), Lachie Evenson (Microsoft), Torin Sandall (Styra)
可以从项目 Open Policy Agent Gatekeeper 中获得帮助,在 Kubernetes 环境下实施策略并加强治理。在本文中,我们将逐步介绍该项目的目标,历史和当前状态。
以下是 Kubecon EU 2019 会议的录音,帮助我们更好地开展与 Gatekeeper 合作:
出发点
如果您所在的组织一直在使用 Kubernetes,您可能一直在寻找如何控制终端用户在集群上的行为,以及如何确保集群符合公司政策。这些策略可能需要满足管理和法律要求,或者符合最佳执行方法和组织惯例。使用 Kubernetes,如何在不牺牲开发敏捷性和运营独立性的前提下确保合规性?
例如,您可以执行以下策略:
- 所有镜像必须来自获得批准的存储库
- 所有入口主机名必须是全局唯一的
- 所有 Pod 必须有资源限制
- 所有命名空间都必须具有列出联系的标签
在接收请求被持久化为 Kubernetes 中的对象之前,Kubernetes 允许通过 admission controller webhooks 将策略决策与 API 服务器分离,从而拦截这些请求。Gatekeeper 创建的目的是使用户能够通过配置(而不是代码)自定义控制许可,并使用户了解群集的状态,而不仅仅是针对评估状态的单个对象,在这些对象准许加入的时候。Gatekeeper 是 Kubernetes 的一个可定制的许可 webhook ,它由 Open Policy Agent (OPA) 强制执行, OPA 是 Cloud Native 环境下的策略引擎,由 CNCF 主办。
发展
在深入了解 Gatekeeper 的当前情况之前,让我们看一下 Gatekeeper 项目是如何发展的。
- Gatekeeper v1.0 - 使用 OPA 作为带有 kube-mgmt sidecar 的许可控制器,用来强制执行基于 configmap 的策略。这种方法实现了验证和转换许可控制。贡献方:Styra
- Gatekeeper v2.0 - 使用 Kubernetes 策略控制器作为许可控制器,OPA 和 kube-mgmt sidecar 实施基于 configmap 的策略。这种方法实现了验证和转换准入控制和审核功能。贡献方:Microsoft
- Gatekeeper v3.0 - 准入控制器与 OPA Constraint Framework 集成在一起,用来实施基于 CRD 的策略,并可以可靠地共享已完成声明配置的策略。使用 kubebuilder 进行构建,实现了验证以及最终转换(待完成)为许可控制和审核功能。这样就可以为 Rego 策略创建策略模板,将策略创建为 CRD 并存储审核结果到策略 CRD 上。该项目是 Google,Microsoft,Red Hat 和 Styra 合作完成的。
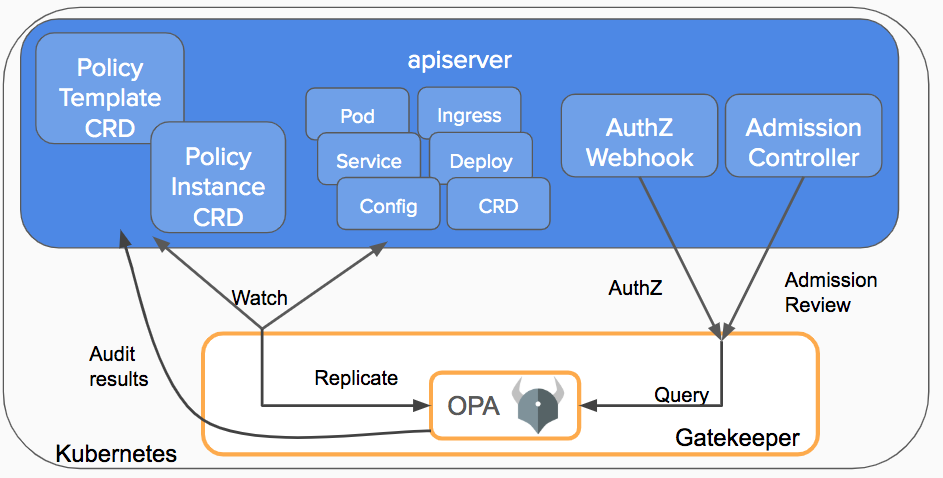
Gatekeeper v3.0 的功能
现在我们详细看一下 Gatekeeper 当前的状态,以及如何利用所有最新的功能。假设一个组织希望确保集群中的所有对象都有 department 信息,这些信息是对象标签的一部分。如何利用 Gatekeeper 完成这项需求?
验证许可控制
在集群中所有 Gatekeeper 组件都 安装 完成之后,只要集群中的资源进行创建、更新或删除,API 服务器将触发 Gatekeeper 准入 webhook 来处理准入请求。
在验证过程中,Gatekeeper 充当 API 服务器和 OPA 之间的桥梁。API 服务器将强制实施 OPA 执行的所有策略。
策略与 Constraint
结合 OPA Constraint Framework,Constraint 是一个声明,表示作者希望系统满足给定的一系列要求。Constraint 都使用 Rego 编写,Rego 是声明性查询语言,OPA 用 Rego 来枚举违背系统预期状态的数据实例。所有 Constraint 都遵循逻辑 AND。假使有一个 Constraint 不满足,那么整个请求都将被拒绝。
在定义 Constraint 之前,您需要创建一个 Constraint Template,允许大家声明新的 Constraint。每个模板都描述了强制执行 Constraint 的 Rego 逻辑和 Constraint 的模式,其中包括 CRD 的模式和传递到 enforces 中的参数,就像函数的参数一样。
例如,以下是一个 Constraint 模板 CRD,它的请求是在任意对象上显示某些标签。
apiVersion: templates.gatekeeper.sh/v1beta1
kind: ConstraintTemplate
metadata:
name: k8srequiredlabels
spec:
crd:
spec:
names:
kind: K8sRequiredLabels
listKind: K8sRequiredLabelsList
plural: k8srequiredlabels
singular: k8srequiredlabels
validation:
# Schema for the `parameters` field
openAPIV3Schema:
properties:
labels:
type: array
items: string
targets:
- target: admission.k8s.gatekeeper.sh
rego: |
package k8srequiredlabels
deny[{"msg": msg, "details": {"missing_labels": missing}}] {
provided := {label | input.review.object.metadata.labels[label]}
required := {label | label := input.parameters.labels[_]}
missing := required - provided
count(missing) > 0
msg := sprintf("you must provide labels: %v", [missing])
}
在集群中部署了 Constraint 模板后,管理员现在可以创建由 Constraint 模板定义的单个 Constraint CRD。例如,这里以下是一个 Constraint CRD,要求标签 hr 出现在所有命名空间上。
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sRequiredLabels
metadata:
name: ns-must-have-hr
spec:
match:
kinds:
- apiGroups: [""]
kinds: ["Namespace"]
parameters:
labels: ["hr"]
类似地,可以从同一个 Constraint 模板轻松地创建另一个 Constraint CRD,该 Constraint CRD 要求所有命名空间上都有 finance 标签。
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sRequiredLabels
metadata:
name: ns-must-have-finance
spec:
match:
kinds:
- apiGroups: [""]
kinds: ["Namespace"]
parameters:
labels: ["finance"]
如您所见,使用 Constraint framework,我们可以通过 Constraint 模板可靠地共享 rego,使用匹配字段定义执行范围,并为 Constraint 提供用户定义的参数,从而为每个 Constraint 创建自定义行为。
审核
根据群集中强制执行的 Constraint,审核功能可定期评估复制的资源,并检测先前存在的错误配置。Gatekeeper 将审核结果存储为 violations,在相关 Constraint 的 status 字段中列出。
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sRequiredLabels
metadata:
name: ns-must-have-hr
spec:
match:
kinds:
- apiGroups: [""]
kinds: ["Namespace"]
parameters:
labels: ["hr"]
status:
auditTimestamp: "2019-08-06T01:46:13Z"
byPod:
- enforced: true
id: gatekeeper-controller-manager-0
violations:
- enforcementAction: deny
kind: Namespace
message: 'you must provide labels: {"hr"}'
name: default
- enforcementAction: deny
kind: Namespace
message: 'you must provide labels: {"hr"}'
name: gatekeeper-system
- enforcementAction: deny
kind: Namespace
message: 'you must provide labels: {"hr"}'
name: kube-public
- enforcementAction: deny
kind: Namespace
message: 'you must provide labels: {"hr"}'
name: kube-system
数据复制
审核要求将 Kubernetes 复制到 OPA 中,然后才能根据强制的 Constraint 对其进行评估。数据复制同样也需要 Constraint,这些 Constraint 需要访问集群中除评估对象之外的对象。例如,一个 Constraint 要强制确定入口主机名的唯一性,就必须有权访问集群中的所有其他入口。
对 Kubernetes 数据进行复制,请使用复制到 OPA 中的资源创建 sync config 资源。例如,下面的配置将所有命名空间和 Pod 资源复制到 OPA。
apiVersion: config.gatekeeper.sh/v1alpha1
kind: Config
metadata:
name: config
namespace: "gatekeeper-system"
spec:
sync:
syncOnly:
- group: ""
version: "v1"
kind: "Namespace"
- group: ""
version: "v1"
kind: "Pod"
未来计划
Gatekeeper 项目背后的社区将专注于提供转换许可控制,可以用来支持转换方案(例如:在创建新资源时使用 department 信息自动注释对象),支持外部数据以将集群外部环境加入到许可决策中,支持试运行以便在执行策略之前了解策略对集群中现有资源的影响,还有更多的审核功能。
如果您有兴趣了解更多有关该项目的信息,请查看 Gatekeeper 存储库。如果您有兴趣帮助确定 Gatekeeper 的方向,请加入 #kubernetes-policy OPA Slack 频道,并加入我们的 周会 一同讨论开发、任务、用例等。
欢迎参加在上海举行的贡献者峰会
Author: Josh Berkus (Red Hat)

连续第二年,我们将在 KubeCon China 之前举行一天的 贡献者峰会。 不管您是否已经是一名 Kubernetes 贡献者,还是想要加入社区队伍,贡献一份力量,都请考虑注册参加这次活动。 这次峰会将于六月 24 号,在上海世博中心(和 KubeCon 的举办地点相同)举行, 一天的活动将包含“现有贡献者活动”,以及“新贡献者工作坊”和“文档小组活动”。
现有贡献者活动
去年的贡献者节之后,我们的团队收到了很多反馈意见,很多亚洲和大洋洲的贡献者也想要针对当前贡献者的峰会内容。 有鉴于此,我们在今年的安排中加入了当前贡献者的主题。
尽管我们还没有一个完整的时间安排,下面是当前贡献者主题所会包含的话题:
- 如何撰写 Kubernetes 改进议案 (KEP)
- 代码库研习
- 本地构建以及测试调试
- 不写代码的贡献机会
- SIG-Azure 面对面交流
- SIG-Scheduling 面对面交流
- 其他兴趣小组的面对面机会
整个计划安排将会在完全确定之后,整理放在社区页面上。
如果您的 SIG 想要在 Kubecon Shanghai 上进行面对面的交流,请联系 Josh Berkus。
新贡献者工作坊
参与过去年新贡献者工作坊(NCW)的学生觉得这项活动非常的有价值, 这项活动也帮助、引导了很多亚洲和大洋洲的开发者更多地参与到 Kubernetes 社区之中。
“这次活动可以让人一次快速熟悉社区。”其中的一位参与者提到。
如果您之前从没有参与过 Kubernetes 的贡献,或者只是做过一次或两次贡献,都请考虑注册参加新贡献者工作坊。
“熟悉了从 CLA 到 PR 的整个流程,也认识结交了很多贡献者。”另一位开发者提到。
文档小组活动
文档小组的新老贡献者都会聚首一天,讨论如何提升文档质量,以及将文档翻译成更多的语言。 如果您对翻译文档,将这些知识和信息翻译成中文和其他语言感兴趣的话,请在这里注册,报名参加文档小组活动。
参与之前
不论您参与的是哪一项活动,所有人都需要在到达贡献者峰会前签署 Kubernetes CLA。 您也同时需要考虑带一个合适的笔记本电脑,帮助文档写作或是编程开发。
壮大我们的贡献者研讨会
作者: Guinevere Saenger (GitHub) 和 Paris Pittman (Google)(谷歌)
tl;dr - 与我们一起了解贡献者社区,并获得你的第一份 PR ! 我们在[巴塞罗那][欧洲]有空位(登记 在5月15号周三结束,所以抓住这次机会!)并且在[上海][中国]有即将到来的峰会。
巴塞罗那的活动将是我们迄今为止最大的一次,登记的参与者比以往任何时候都多!
你是否曾经想为 Kubernetes 做贡献,但不知道从哪里开始?你有没有曾经看过我们社区的许多代码库并认为需要改进的地方?我们为你准备了一个工作室!
KubeCon + CloudNativeCon 巴塞罗那的研讨会新贡献者研讨会将是第四个这样的研讨会,我们真的很期待!
这个研讨会去年在哥本哈根的 KubeConEU 启动,到目前为止,我们已经把它带到了上海和西雅图,现在是巴塞罗那,以及一些非 KubeConEU 的地方。
我们根据以往课程的反馈,不断更新和改进研讨会的内容。
这一次,我们将根据参与者对开源和 Kubernetes 的经验和适应程度来进行划分。
作为101课程的一部分,我们将为完全不熟悉开源和 Kubernetes 的人提供开发人员设置和项目工作流支持,并希望为每个参与者开展他们自己的第一期工作。
在201课程中,我们将为那些在开源方面有更多经验但可能不熟悉我们社区开发工具的人进行代码库演练和本地开发和测试演示。
对于这两门课程,你将有机会亲自动手并体会到其中的乐趣。因为不是每个贡献者都使用代码,也不是每项贡献都是技术性的,所以我们将在研讨会开始时学习如何构建和组织项目,以及如何进行找到合适的人,以及遇到困难时在哪里寻求帮助。
辅导机会
我们还将回归 SIG Meet-and-Greet,在这里新入门的菜鸟贡献者将有机会与当值的贡献者交流,这也许会让他们找到他们梦想的 SIG,了解他们可以帮助哪些激动人心的领域,获得导师,结交朋友。
PS - 5月23日星期四,在 KubeCon+CloudNativeCon 会议期间会有两次导师会议。[在这里注册][导师]。在西雅图活动期间,60% 的与会者会向贡献者提问。
曾经与会者的故事 - Vallery Lancy,Lyft 的工程师
在一系列采访中,我们与一些过去的参与者进行了交谈,这些采访将在今年全年公布。
在我们的前两个片段中,我们会提到 Vallery Lancy,Lyft 公司的工程师,也是我们最近西雅图版研讨会的75名与会者之一。她在社区里闲逛了一段时间,想看看能不能投身到某个领域当中。
在这里观看 Vallery 讲述她的经历:
Vallery 和那些对研讨会感兴趣的人或者参加巴塞罗那会议的人说了些什么?
想变得和 Vallery 还有数百名参与之前的新贡献者研讨会的与会者一样的话:在巴塞罗那(或者上海-或者圣地亚哥!)加入我们!你会有一个与众不同的体验,而不再是死读我们的文档!
Have the opportunity to meet with the experts and go step by step into your journey with your peers around you. We’re looking forward to seeing you there! Register here --> 你将有机会与专家见面,并与周围的同龄人一步步走上属于你的道路。我们期待着在那里与你见面! 在这里注册
如何参与 Kubernetes 文档的本地化工作
作者: Zach Corleissen(Linux 基金会)
去年我们对 Kubernetes 网站进行了优化,加入了多语言内容的支持。贡献者们踊跃响应,加入了多种新的本地化内容:截至 2019 年 4 月,Kubernetes 文档有了 9 个不同语言的未完成版本,其中有 6 个是 2019 年加入的。在每个 Kubernetes 文档页面的上方,读者都可以看到一个语言选择器,其中列出了所有可用语言。
不论是完成度最高的中文版 v1.12,还是最新加入的葡萄牙文版 v1.14,各语言的本地化内容还未完成,这是一个进行中的项目。如果读者有兴趣对现有本地化工作提供支持,请继续阅读。
什么是本地化
翻译是以词表意的问题。而本地化在此基础之上,还包含了过程和设计方面的工作。
本地化和翻译很像,但是包含更多内容。除了进行翻译之外,本地化还要为编写和发布过程的框架进行优化。例如,Kubernetes.io 多数的站点浏览功能(按钮文字)都保存在单独的文件之中。所以启动新本地化的过程中,需要包含加入对特定文件中字符串进行翻译的工作。
本地化很重要,能够有效的降低 Kubernetes 的采纳和支持门槛。如果能用母语阅读 Kubernetes 文档,就能更轻松的开始使用 Kubernetes,并对其发展作出贡献。
如何启动本地化工作
不同语言的本地化工作都是单独的功能——和其它 Kubernetes 功能一致,贡献者们在一个 SIG 中进行本地化工作,分享出来进行评审,并加入项目。
贡献者们在团队中进行内容的本地化工作。因为自己不能批准自己的 PR,所以一个本地化团队至少应该有两个人——例如意大利文的本地化团队有两个人。这个团队规模可能很大:中文团队有几十个成员。
每个团队都有自己的工作流。有些团队手工完成所有的内容翻译;有些会使用带有翻译插件的编译器,并使用评审机来提供正确性的保障。SIG Docs 专注于输出的标准;这就给了本地化团队采用适合自己工作情况的工作流。这样一来,团队可以根据最佳实践进行协作,并以 Kubernetes 的社区精神进行分享。
为本地化工作添砖加瓦
如果你有兴趣为 Kubernetes 文档加入新语种的本地化内容,Kubernetes contribution guide 中包含了这方面的相关内容。
已经启动的的本地化工作同样需要支持。如果有兴趣为现存项目做出贡献,可以加入本地化团队的 Slack 频道,去做个自我介绍。各团队的成员会帮助你开始工作。
| 语种 | Slack 频道 |
|---|---|
| 中文 | #kubernetes-docs-zh |
| 英文 | #sig-docs |
| 法文 | #kubernetes-docs-fr |
| 德文 | #kubernetes-docs-de |
| 印地 | #kubernetes-docs-hi |
| 印度尼西亚文 | #kubernetes-docs-id |
| 意大利文 | #kubernetes-docs-it |
| 日文 | #kubernetes-docs-ja |
| 韩文 | #kubernetes-docs-ko |
| 葡萄牙文 | #kubernetes-docs-pt |
| 西班牙文 | #kubernetes-docs-es |
下一步?
最新的印地文本地化工作正在启动。为什么不加入你的语言?
身为 SIG Docs 的主席,我甚至希望本地化工作跳出文档范畴,直接为 Kubernetes 组件提供本地化支持。有什么组件是你希望支持不同语言的么?可以提交一个 Kubernetes Enhancement Proposal 来促成这一进步。
Kubernetes 1.14 稳定性改进中的进程ID限制
作者: Derek Carr
你是否见过有人拿走了比属于他们那一份更多的饼干? 一个人走过来,抓起半打新鲜烤制的大块巧克力饼干然后匆匆离去,就像饼干怪兽大喊 “Om nom nom nom”。
在一些罕见的工作负载中,Kubernetes 集群内部也发生了类似的情况。每个 Pod 和 Node 都有有限数量的可能的进程 ID(PID),供所有应用程序共享。尽管很少有进程或 Pod 能够进入并获取所有 PID,但由于这种行为,一些用户会遇到资源匮乏的情况。 因此,在 Kubernetes 1.14 中,我们引入了一项增强功能,以降低单个 Pod 垄断所有可用 PID 的风险。
你能预留一些 PIDs 吗?
在这里,我们谈论的是某些容器的贪婪性。 在理想情况之外,失控进程有时会发生,特别是在测试集群中。 因此,在这些集群中会发生一些混乱的非生产环境准备就绪的事情。
在这种情况下,可能会在节点内部发生类似于 fork 炸弹耗尽 PID 的攻击。随着资源的缓慢腐蚀,被一些不断产生子进程的僵尸般的进程所接管,其他正常的工作负载会因为这些像气球般不断膨胀的浪费的处理能力而开始受到冲击。这可能导致同一 Pod 上的其他进程缺少所需的 PID。这也可能导致有趣的副作用,因为节点可能会发生故障,并且该Pod的副本将安排到新的机器上,至此,该过程将在整个群集中重复进行。
解决问题
因此,在 Kubernetes 1.14 中,我们添加了一个特性,允许通过配置 kubelet,限制给定 Pod 可以消耗的 PID 数量。如果该机器支持 32768 个 PIDs 和 100 个 Pod,则可以为每个 Pod 提供 300 个 PIDs 的预算,以防止 PIDs 完全耗尽。如果管理员想要像 CPU 或内存那样过度使用 PIDs,那么他们也可以配置超额使用,但是这样会有一些额外风险。不管怎样,没有一个Pod能搞坏整个机器。这通常会防止简单的分叉函数炸弹接管你的集群。
此更改允许管理员保护一个 Pod 不受另一个 Pod 的影响,但不能确保计算机上的所有 Pod 都能保护节点和节点代理本身不受影响。因此,我们在这个版本中以 Alpha 的形式引入了这个一个特性,它提供了 PIDs 在节点代理( kubelet、runtime 等)与 Pod 上的最终用户工作负载的分离。管理员可以预定特定数量的 pid(类似于今天如何预定 CPU 或内存),并确保它们不会被该计算机上的 pod 消耗。一旦从 Alpha 进入到 Beta,然后在将来的 Kubernetes 版本中稳定下来,我们就可以使用这个特性防止 Linux 资源耗尽。
开始使用 Kubernetes 1.14。
##参与其中
如果您对此特性有反馈或有兴趣参与其设计与开发,请加入[节点特别兴趣小组](https://github.com/kubernetes/community/tree/master/sig Node)。
###关于作者: Derek Carr 是 Red Hat 高级首席软件工程师。他也是 Kubernetes 的贡献者和 Kubernetes 社区指导委员会的成员。
Raw Block Volume 支持进入 Beta
作者: Ben Swartzlander (NetApp), Saad Ali (Google)
Kubernetes v1.13 中对原生数据块卷(Raw Block Volume)的支持进入 Beta 阶段。此功能允许将持久卷作为块设备而不是作为已挂载的文件系统暴露在容器内部。
什么是块设备?
块设备允许对固定大小的块中的数据进行随机访问。硬盘驱动器、SSD 和 CD-ROM 驱动器都是块设备的例子。
通常,持久性性存储是在通过在块设备(例如磁盘或 SSD)之上构造文件系统(例如 ext4)的分层方式实现的。这样应用程序就可以读写文件而不是操作数据块进。操作系统负责使用指定的文件系统将文件读写转换为对底层设备的数据块读写。
值得注意的是,整个磁盘都是块设备,磁盘分区也是如此,存储区域网络(SAN)设备中的 LUN 也是一样的。
为什么要将 raw block volume 添加到 kubernetes?
有些特殊的应用程序需要直接访问块设备,原因例如,文件系统层会引入不必要的开销。最常见的情况是数据库,通常会直接在底层存储上组织数据。原生的块设备(Raw Block Devices)还通常由能自己实现某种存储服务的软件(软件定义的存储系统)使用。
从程序员的角度来看,块设备是一个非常大的字节数组,具有某种最小读写粒度,通常为 512 个字节,大部分情况为 4K 或更大。
随着在 Kubernetes 中运行数据库软件和存储基础架构软件变得越来越普遍,在 Kubernetes 中支持原生块设备的需求变得越来越重要。
哪些卷插件支持 raw block?
在发布此博客时,以下 in-tree 卷类型支持原生块设备:
- AWS EBS
- Azure Disk
- Cinder
- Fibre Channel
- GCE PD
- iSCSI
- Local volumes
- RBD (Ceph)
- Vsphere
Out-of-tree CSI 卷驱动程序 可能也支持原生数据块卷。Kubernetes CSI 对原生数据块卷的支持目前为 alpha 阶段。参考 这篇 文档。
Kubernetes raw block volume 的 API
原生数据块卷与普通存储卷有很多共同点。两者都通过创建与 PersistentVolume 对象绑定的 PersistentVolumeClaim 对象发起请求,并通过将它们加入到 PodSpec 的 volumes 数组中来连接到 Kubernetes 中的 Pod。
但是有两个重要的区别。首先,要请求原生数据块设备的 PersistentVolumeClaim 必须在 PersistentVolumeClaimSpec 中设置 volumeMode = "Block"。volumeMode 为空时与传统设置方式中的指定 volumeMode = "Filesystem" 是一样的。PersistentVolumes 在其 PersistentVolumeSpec 中也有一个 volumeMode 字段,"Block" 类型的 PVC 只能绑定到 "Block" 类型的 PV 上,而"Filesystem" 类型的 PVC 只能绑定到 "Filesystem" PV 上。
其次,在 Pod 中使用原生数据块卷时,必须在 PodSpec 的 Container 部分指定一个 VolumeDevice,而不是 VolumeMount。VolumeDevices 具备 devicePaths 而不是 mountPaths,在容器中,应用程序将看到位于该路径的设备,而不是挂载了的文件系统。
应用程序打开、读取和写入容器内的设备节点,就像它们在非容器化或虚拟环境中与系统上的任何块设备交互一样。
创建一个新的原生块设备 PVC
首先,请确保与您选择的存储类关联的驱动支持原生块设备。然后创建 PVC。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteMany
volumeMode: Block
storageClassName: my-sc
resources:
requests:
storage: 1Gi
使用原生块 PVC
在 Pod 定义中使用 PVC 时,需要选择块设备的设备路径,而不是文件系统的安装路径。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: busybox
command:
- sleep
- “3600”
volumeDevices:
- devicePath: /dev/block
name: my-volume
imagePullPolicy: IfNotPresent
volumes:
- name: my-volume
persistentVolumeClaim:
claimName: my-pvc
作为存储供应商,我如何在 CSI 插件中添加对原生块设备的支持?
CSI 插件的原生块支持仍然是 alpha 版本,但是现在可以改进了。CSI 规范 详细说明了如何处理具有 BlockVolume 能力而不是 MountVolume 能力的卷的请求。CSI 插件可以支持两种类型的卷,也可以支持其中一种或另一种。更多详细信息,请查看 这个文档。
问题/陷阱
由于块设备实质上还是设备,因此可以从容器内部对其进行底层操作,而文件系统的卷则无法执行这些操作。例如,实际上是块设备的 SCSI 磁盘支持使用 Linux ioctl 向设备发送 SCSI 命令。
默认情况下,Linux 不允许容器将 SCSI 命令从容器内部发送到磁盘。为此,必须向容器安全层级认证 SYS_RAWIO 功能实现这种行为。请参阅 这篇 文档。
另外,尽管 Kubernetes 保证可以将块设备交付到容器中,但不能保证它实际上是 SCSI 磁盘或任何其他类型的磁盘。用户必须确保所需的磁盘类型与 Pod 一起使用,或只部署可以处理各种块设备类型的应用程序。
如何学习更多?
在此处查看有关 snapshot 功能的其他文档:Raw Block Volume 支持
如何参与进来?
加入 Kubernetes 存储 SIG 和 CSI 社区,帮助我们添加更多出色的功能并改进现有功能,就像 raw block 存储一样!
https://github.com/kubernetes/community/tree/master/sig-storage https://github.com/container-storage-interface/community/blob/master/README.md
特别感谢所有为 Kubernetes 增加 block volume 支持的贡献者,包括:
- Ben Swartzlander (https://github.com/bswartz)
- Brad Childs (https://github.com/childsb)
- Erin Boyd (https://github.com/erinboyd)
- Masaki Kimura (https://github.com/mkimuram)
- Matthew Wong (https://github.com/wongma7)
- Michelle Au (https://github.com/msau42)
- Mitsuhiro Tanino (https://github.com/mtanino)
- Saad Ali (https://github.com/saad-ali)
新贡献者工作坊上海站
作者: Josh Berkus (红帽), Yang Li (The Plant), Puja Abbassi (Giant Swarm), XiangPeng Zhao (中兴通讯)

KubeCon 上海站新贡献者峰会与会者,摄影:Jerry Zhang
最近,在中国的首次 KubeCon 上,我们完成了在中国的首次新贡献者峰会。看到所有中国和亚洲的开发者(以及来自世界各地的一些人)有兴趣成为贡献者,这令人非常兴奋。在长达一天的课程中,他们了解了如何、为什么以及在何处为 Kubernetes 作出贡献,创建了 PR,参加了贡献者圆桌讨论,并签署了他们的 CLA。
这是我们的第二届新贡献者工作坊(NCW),它由前一次贡献者体验 SIG 成员创建和领导的哥本哈根研讨会延伸而来。根据受众情况,本次活动采用了中英文两种语言,充分利用了 CNCF 赞助的一流的同声传译服务。同样,NCW 团队由社区成员组成,既有说英语的,也有说汉语的:Yang Li、XiangPeng Zhao、Puja Abbassi、Noah Abrahams、Tim Pepper、Zach Corleissen、Sen Lu 和 Josh Berkus。除了演讲和帮助学员外,团队的双语成员还将所有幻灯片翻译成了中文。共有五十一名学员参加。

Noah Abrahams 讲解 Kubernetes 沟通渠道。摄影:Jerry Zhang
NCW 让参与者完成了为 Kubernetes 作出贡献的各个阶段,从决定在哪里作出贡献开始,接着介绍了 SIG 系统和我们的代码仓库结构。我们还有来自文档和测试基础设施领域的「客座讲者」,他们负责讲解有关的贡献。最后,我们在创建 issue、提交并批准 PR 的实践练习后,结束了工作坊。
这些实践练习使用一个名为贡献者游乐场的代码仓库,由贡献者体验 SIG 创建,让新贡献者尝试在一个 Kubernetes 仓库中执行各种操作。它修改了 Prow 和 Tide 自动化,使用与真实代码仓库类似的 Owners 文件。这可以让学员了解为我们的仓库做出贡献的有关机制,同时又不妨碍正常的开发流程。

Yang Li 讲到如何让你的 PR 通过评审。摄影:Josh Berkus
「防火长城」和语言障碍都使得在中国为 Kubernetes 作出贡献变得困难。而且,中国的开源商业模式并不成熟,员工在开源项目上工作的时间有限。
中国工程师渴望参与 Kubernetes 的研发,但他们中的许多人不知道从何处开始,因为 Kubernetes 是一个如此庞大的项目。通过本次工作坊,我们希望帮助那些想要参与贡献的人,不论他们希望修复他们遇到的一些错误、改进或本地化文档,或者他们需要在工作中用到 Kubernetes。我们很高兴看到越来越多的中国贡献者在过去几年里加入社区,我们也希望将来可以看到更多。
「我已经参与了 Kubernetes 社区大约三年」,XiangPeng Zhao 说,「在社区,我注意到越来越多的中国开发者表现出对 Kubernetes 贡献的兴趣。但是,开始为这样一个项目做贡献并不容易。我尽力帮助那些我在社区遇到的人,但是,我认为可能仍有一些新的贡献者离开社区,因为他们在遇到麻烦时不知道从哪里获得帮助。幸运的是,社区在 KubeCon 哥本哈根站发起了 NCW,并在 KubeCon 上海站举办了第二届。我很高兴受到 Josh Berkus 的邀请,帮助组织这个工作坊。在工作坊期间,我当面见到了社区里的朋友,在练习中指导了与会者,等等。所有这些对我来说都是难忘的经历。作为有着多年贡献者经验的我,也学习到了很多。我希望几年前我开始为 Kubernetes 做贡献时参加过这样的工作坊」。

贡献者圆桌讨论。摄影:Jerry Zhang
工作坊以现有贡献者圆桌讨论结束,嘉宾包括 Lucas Käldström、Janet Kuo、Da Ma、Pengfei Ni、Zefeng Wang 和 Chao Xu。这场圆桌讨论旨在让新的和现有的贡献者了解一些最活跃的贡献者和维护者的幕后日常工作,不论他们来自中国还是世界各地。嘉宾们讨论了从哪里开始贡献者的旅程,以及如何与评审者和维护者进行互动。他们进一步探讨了在中国参与贡献的主要问题,并向与会者预告了在 Kubernetes 的未来版本中可以期待的令人兴奋的功能。
工作坊结束后,XiangPeng Zhao 和一些与会者就他们的经历在微信和 Twitter 上进行了交谈。他们很高兴参加了 NCW,并就改进工作坊提出了一些建议。一位名叫 Mohammad 的与会者说:「我在工作坊上玩得很开心,学习了参与 k8s 贡献的整个过程。」另一位与会者 Jie Jia 说:「工作坊非常精彩。它系统地解释了如何为 Kubernetes 做出贡献。即使参与者之前对此一无所知,他(她)也可以理解这个过程。对于那些已经是贡献者的人,他们也可以学习到新东西。此外,我还可以在工作坊上结识来自国内外的新朋友。真是棒极了!」
贡献者体验 SIG 将继续在未来的 KubeCon 上举办新贡献者工作坊,包括西雅图站、巴塞罗那站,然后在 2019 年六月回到上海。如果你今年未能参加,请在未来的 KubeCon 上注册。并且,如果你遇到工作坊的与会者,请务必欢迎他们加入社区。
链接:
- 中文版幻灯片:PDF
- 英文版幻灯片:PDF 或 带有演讲者笔记的 Google Docs
- 贡献者游乐场
Kubernetes 文档更新,国际版
作者:Zach Corleissen (Linux 基金会)
作为文档特别兴趣小组(SIG Docs)的联合主席,我很高兴能与大家分享 Kubernetes 文档在本地化(l10n)方面所拥有的一个完全成熟的工作流。
丰富的缩写
L10n 是 localization 的缩写。
I18n 是 internationalization 的缩写。
I18n 定义了做什么 能让 l10n 更容易。而 L10n 更全面,相比翻译( t9n )具备更完善的流程。
为什么本地化很重要
SIG Docs 的目标是让 Kubernetes 更容易为尽可能多的人使用。
一年前,我们研究了是否有可能由一个独立翻译 Kubernetes 文档的中国团队来主持文档输出。经过多次交谈(包括 OpenStack l10n 的专家),多次转变,以及重新致力于更轻松的本地化,我们意识到,开源文档就像开源软件一样,是在可能的边缘不断进行实践。
整合工作流程、语言标签和团队级所有权可能看起来像是十分简单的改进,但是这些功能使 l10n 可以扩展到规模越来越大的 l10n 团队。随着 SIG Docs 不断改进,我们已经在单一工作流程中偿还了大量技术债务并简化了 l10n。这对未来和现在都很有益。
整合的工作流程
现在,本地化已整合到 kubernetes/website 存储库。我们已经配置了 Kubernetes CI/CD 系统,Prow 来处理自动语言标签分配以及团队级 PR 审查和批准。
语言标签
Prow 根据文件路径自动添加语言标签。感谢 SIG Docs 贡献者 June Yi,他让人们还可以在 pull request(PR)注释中手动分配语言标签。例如,当为 issue 或 PR 留下下述注释时,将为之分配标签 language/ko(Korean)。
/language ko
这些存储库标签允许审阅者按语言过滤 PR 和 issue。例如,您现在可以过滤 kubernetes/website 面板中具有中文内容的 PR。
团队审核
L10n 团队现在可以审查和批准他们自己的 PR。例如,英语的审核和批准权限在位于用于显示英语内容的顶级子文件夹中的 OWNERS 文件中指定。
将 OWNERS 文件添加到子目录可以让本地化团队审查和批准更改,而无需由可能并不擅长该门语言的审阅者进行批准。
下一步是什么
我们期待着上海的 doc sprint 能作为中国 l10n 团队的资源。
我们很高兴继续支持正在取得良好进展的日本和韩国 l10n 队伍。
如果您有兴趣将 Kubernetes 本地化为您自己的语言或地区,请查看我们的本地化 Kubernetes 文档指南,并联系 SIG Docs 主席团获取支持。
加入SIG Docs
如果您对 Kubernetes 文档感兴趣,请参加 SIG Docs 每周会议,或在 Kubernetes Slack 加入 #sig-docs。
Kubernetes 2018 年北美贡献者峰会
作者:
Bob Killen(密歇根大学) Sahdev Zala(IBM), Ihor Dvoretskyi(CNCF)
2018 年北美 Kubernetes 贡献者峰会将在西雅图 KubeCon + CloudNativeCon 会议之前举办,这将是迄今为止规模最大的一次盛会。
这是一个将新老贡献者聚集在一起,面对面交流和分享的活动;并为现有的贡献者提供一个机会,帮助塑造社区发展的未来。它为新的社区成员提供了一个学习、探索和实践贡献工作流程的良好空间。
与之前的贡献者峰会不同,本次活动为期两天,有一个更为轻松的行程安排,一般贡献者将于 12 月 9 日(周日)下午 5 点至 8 点在距离会议中心仅几步远的 Garage Lounge and Gaming Hall 举办峰会。在那里,贡献者也可以进行台球、保龄球等娱乐活动,而且还有各种食品和饮料。
接下来的一天,也就是 10 号星期一,有三个独立的会议你可以选择参与:
新贡献者研讨会:
为期半天的研讨会旨在让新贡献者加入社区,并营造一个良好的 Kubernetes 社区工作环境。 请在开会期间保持在场,该讨论会不允许随意进出。
当前贡献者追踪:
保留给那些积极参与项目开发的贡献者;目前的贡献者追踪包括讲座、研讨会、聚会、Unconferences 会议、指导委员会会议等等! 请留意 GitHub 中的时间表,因为内容经常更新。
Docs 冲刺:
SIG-Docs 将在活动日期临近的时候列出一个需要处理的问题和挑战列表。
注册:
要注册贡献者峰会,请参阅 Git Hub 上的活动详情注册部分。请注意报名正在审核中。 如果您选择了 “当前贡献者追踪”,而您却不是一个活跃的贡献者,您将被要求参加新贡献者研讨会,或者被要求进入候补名单。 成千上万的贡献者只有 300 个位置,我们需要确保正确的人被安排席位。
如果您有任何问题或疑虑,请随时通过 community@kubernetes.io 联系贡献者峰会组织团队。
期待在那里看到每个人!
2018 年督导委员会选举结果
作者: Jorge Castro (Heptio), Ihor Dvoretskyi (CNCF), Paris Pittman (Google)
结果
Kubernetes 督导委员会选举现已完成,以下候选人获得了立即开始的两年任期:
- Aaron Crickenberger, Google, @spiffxp
- Davanum Srinivas, Huawei, @dims
- Tim St. Clair, Heptio, @timothysc
十分感谢!
- 督导委员会荣誉退休成员 Quinton Hoole,表扬他在过去一年为社区所作的贡献。我们期待着
- 参加竞选的候选人。愿我们永远拥有一群强大的人,他们希望在每一次选举中都能像你们一样推动社区向前发展。
- 共计 307 名选民参与投票。
- 本次选举由康奈尔大学主办 CIVS!
加入督导委员会
你可以关注督导委员会的任务清单,并通过向他们的代码仓库提交 issue 或 PR 的方式来参与。他们也会在UTC 时间每周三晚 8 点举行会议,并定期与我们的贡献者见面。
督导委员会会议:
与我们的贡献者会面:
Kubernetes 中的拓扑感知数据卷供应
作者: Michelle Au(谷歌)
通过提供拓扑感知动态卷供应功能,具有持久卷的多区域集群体验在 Kubernetes 1.12 中得到了改进。此功能使得 Kubernetes 在动态供应卷时能做出明智的决策,方法是从调度器获得为 Pod 提供数据卷的最佳位置。在多区域集群环境,这意味着数据卷能够在满足你的 Pod 运行需要的合适的区域被供应,从而允许您跨故障域轻松部署和扩展有状态工作负载,从而提供高可用性和容错能力。
以前的挑战
在此功能被提供之前,在多区域集群中使用区域化的持久磁盘(例如 AWS ElasticBlockStore,Azure Disk,GCE PersistentDisk)运行有状态工作负载存在许多挑战。动态供应独立于 Pod 调度处理,这意味着只要您创建了一个 PersistentVolumeClaim(PVC),一个卷就会被供应。这也意味着供应者不知道哪些 Pod 正在使用该卷,也不清楚任何可能影响调度的 Pod 约束。
这导致了不可调度的 Pod,因为在以下区域中配置了卷:
- 没有足够的 CPU 或内存资源来运行 Pod
- 与节点选择器、Pod 亲和或反亲和策略冲突
- 由于污点(taint)不能运行 Pod
另一个常见问题是,使用多个持久卷的非有状态 Pod 可能会在不同的区域中配置每个卷,从而导致一个不可调度的 Pod。
次优的解决方法包括节点超配,或在正确的区域中手动创建卷,但这会造成难以动态部署和扩展有状态工作负载的问题。
拓扑感知动态供应功能解决了上述所有问题。
支持的卷类型
在 1.12 中,以下驱动程序支持拓扑感知动态供应:
- AWS EBS
- Azure Disk
- GCE PD (包括 Regional PD)
- CSI(alpha) - 目前只有 GCE PD CSI 驱动实现了拓扑支持
设计原则
虽然最初支持的插件集都是基于区域的,但我们设计此功能时遵循 Kubernetes 跨环境可移植性的原则。 拓扑规范是通用的,并使用类似于基于标签的规范,如 Pod nodeSelectors 和 nodeAffinity。 该机制允许您定义自己的拓扑边界,例如内部部署集群中的机架,而无需修改调度程序以了解这些自定义拓扑。
此外,拓扑信息是从 Pod 规范中抽象出来的,因此 Pod 不需要了解底层存储系统的拓扑特征。 这意味着您可以在多个集群、环境和存储系统中使用相同的 Pod 规范。
入门
要启用此功能,您需要做的就是创建一个将 volumeBindingMode 设置为 WaitForFirstConsumer 的 StorageClass:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: topology-aware-standard
provisioner: kubernetes.io/gce-pd
volumeBindingMode: WaitForFirstConsumer
parameters:
type: pd-standard
这个新设置表明卷配置器不立即创建卷,而是等待使用关联的 PVC 的 Pod 通过调度运行。
请注意,不再需要指定以前的 StorageClass zone 和 zones 参数,因为现在在哪个区域中配置卷由 Pod 策略决定。
接下来,使用此 StorageClass 创建一个 Pod 和 PVC。 此过程与之前相同,但在 PVC 中指定了不同的 StorageClass。 以下是一个假设示例,通过指定许多 Pod 约束和调度策略来演示新功能特性:
- 一个 Pod 多个 PVC
- 跨子区域的节点亲和
- 同一区域 Pod 反亲和
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- us-central1-a
- us-central1-f
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: failure-domain.beta.kubernetes.io/zone
containers:
- name: nginx
image: gcr.io/google_containers/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
- name: logs
mountPath: /logs
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: topology-aware-standard
resources:
requests:
storage: 10Gi
- metadata:
name: logs
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: topology-aware-standard
resources:
requests:
storage: 1Gi
之后,您可以看到根据 Pod 设置的策略在区域中配置卷:
$ kubectl get pv -o=jsonpath='{range .items[*]}{.spec.claimRef.name}{"\t"}{.metadata.labels.failure\-domain\.beta\.kubernetes\.io/zone}{"\n"}{end}'
www-web-0 us-central1-f
logs-web-0 us-central1-f
www-web-1 us-central1-a
logs-web-1 us-central1-a
我怎样才能了解更多?
有关拓扑感知动态供应功能的官方文档可在此处获取:https://kubernetes.io/docs/concepts/storage/storage-classes/#volume-binding-mode
有关 CSI 驱动程序的文档,请访问:https://kubernetes-csi.github.io/docs/
下一步是什么?
我们正积极致力于改进此功能以支持:
- 更多卷类型,包括本地卷的动态供应
- 动态容量可附加计数和每个节点的容量限制
我如何参与?
如果您对此功能有反馈意见或有兴趣参与设计和开发,请加入 Kubernetes 存储特别兴趣小组(SIG)。我们正在快速成长,并始终欢迎新的贡献者。
特别感谢帮助推出此功能的所有贡献者,包括 Cheng Xing (verult)、Chuqiang Li (lichuqiang)、David Zhu (davidz627)、Deep Debroy (ddebroy)、Jan Šafránek (jsafrane)、Jordan Liggitt (liggitt)、Michelle Au (msau42)、Pengfei Ni (feiskyer)、Saad Ali (saad-ali)、Tim Hockin (thockin),以及 Yecheng Fu (cofyc)。
Kubernetes v1.12: RuntimeClass 简介
作者: Tim Allclair (Google)
Kubernetes 最初是为了支持在 Linux 主机上运行本机应用程序的 Docker 容器而创建的。 从 Kubernetes 1.3中的 rkt 开始,更多的运行时间开始涌现, 这导致了容器运行时接口(Container Runtime Interface)(CRI)的开发。 从那时起,备用运行时集合越来越大: 为了加强工作负载隔离,Kata Containers 和 gVisor 等项目被发起, 并且 Kubernetes 对 Windows 的支持正在 稳步发展 。
由于存在诸多针对不同用例的运行时,集群对混合运行时的需求变得明晰起来。 但是,所有这些不同的容器运行方式都带来了一系列新问题要处理:
- 用户如何知道哪些运行时可用,并为其工作负荷选择运行时?
- 我们如何确保将 Pod 被调度到支持所需运行时的节点上?
- 哪些运行时支持哪些功能,以及我们如何向用户显示不兼容性?
- 我们如何考虑运行时的各种资源开销?
RuntimeClass 旨在解决这些问题。
Kubernetes 1.12 中的 RuntimeClass
最近,RuntimeClass 在 Kubernetes 1.12 中作为 alpha 功能引入。 最初的实现侧重于提供运行时选择 API ,并为解决其他未解决的问题铺平道路。
RuntimeClass 资源代表 Kubernetes 集群中支持的容器运行时。 集群制备组件安装、配置和定义支持 RuntimeClass 的具体运行时。 在 RuntimeClassSpec 的当前形式中,只有一个字段,即 RuntimeHandler。 RuntimeHandler 由在节点上运行的 CRI 实现解释,并映射到实际的运行时配置。 同时,PodSpec 被扩展添加了一个新字段 RuntimeClassName,命名应该用于运行 Pod 的 RuntimeClass。
为什么 RuntimeClass 是 Pod 级别的概念? Kubernetes 资源模型期望 Pod 中的容器之间可以共享某些资源。 如果 Pod 由具有不同资源模型的不同容器组成,支持必要水平的资源共享变得非常具有挑战性。 例如,要跨 VM 边界支持本地回路(localhost)接口非常困难,但这是 Pod 中两个容器之间通信的通用模型。
下一步是什么?
RuntimeClass 资源是将运行时属性显示到控制平面的重要基础。 例如,要对具有支持不同运行时间的异构节点的群集实施调度程序支持,我们可以在 RuntimeClass 定义中添加 NodeAffinity条件。 另一个需要解决的领域是管理可变资源需求以运行不同运行时的 Pod。 Pod Overhead 提案 是一项较早的尝试,与 RuntimeClass 设计非常吻合,并且可能会进一步推广。
人们还提出了许多其他 RuntimeClass 扩展,随着功能的不断发展和成熟,我们会重新讨论这些提议。 正在考虑的其他扩展包括:
- 提供运行时支持的可选功能,并更好地查看由不兼容功能导致的错误。
- 自动运行时或功能发现,支持无需手动配置的调度决策。
- 标准化或一致的 RuntimeClass 名称,用于定义一组具有相同名称的 RuntimeClass 的集群应支持的属性。
- 动态注册附加的运行时,因此用户可以在不停机的情况下在现有群集上安装新的运行时。
- 根据 Pod 的要求“匹配” RuntimeClass。 例如,指定运行时属性并使系统与适当的 RuntimeClass 匹配,而不是通过名称显式分配 RuntimeClass。
至少要到2019年,RuntimeClass 才会得到积极的开发,我们很高兴看到从 Kubernetes 1.12 中的 RuntimeClass alpha 开始,此功能得以形成。
学到更多
- 试试吧! 作为Alpha功能,还有一些其他设置步骤可以使用RuntimeClass。 有关如何使其运行,请参考 RuntimeClass文档 。
- 查看 RuntimeClass Kubernetes 增强建议 以获取更多细节设计细节。
- 沙盒隔离级别决策 记录了最初使 RuntimeClass 成为 Pod 级别选项的思考过程。
- 加入讨论,并通过 SIG-Node社区 帮助塑造 RuntimeClass 的未来。
KubeDirector:在 Kubernetes 上运行复杂状态应用程序的简单方法
作者:Thomas Phelan(BlueData)
KubeDirector 是一个开源项目,旨在简化在 Kubernetes 上运行复杂的有状态扩展应用程序集群。KubeDirector 使用自定义资源定义(CRD) 框架构建,并利用了本地 Kubernetes API 扩展和设计哲学。这支持与 Kubernetes 用户/资源 管理以及现有客户端和工具的透明集成。
我们最近介绍了 KubeDirector 项目,作为我们称为 BlueK8s 的更广泛的 Kubernetes 开源项目的一部分。我很高兴地宣布 KubeDirector 的 pre-alpha 代码现在已经可用。在这篇博客文章中,我将展示它是如何工作的。
KubeDirector 提供以下功能:
- 无需修改代码即可在 Kubernetes 上运行非云原生有状态应用程序。换句话说,不需要分解这些现有的应用程序来适应微服务设计模式。
- 本机支持保存特定于应用程序的配置和状态。
- 与应用程序无关的部署模式,最大限度地减少将新的有状态应用程序装载到 Kubernetes 的时间。
KubeDirector 使熟悉数据密集型分布式应用程序(如 Hadoop、Spark、Cassandra、TensorFlow、Caffe2 等)的数据科学家能够在 Kubernetes 上运行这些应用程序 -- 只需极少的学习曲线,无需编写 GO 代码。由 KubeDirector 控制的应用程序由一些基本元数据和相关的配置工件包定义。应用程序元数据称为 KubeDirectorApp 资源。
要了解 KubeDirector 的组件,请使用类似于以下的命令在 GitHub 上克隆存储库:
git clone http://<userid>@github.com/bluek8s/kubedirector.
Spark 2.2.1 应用程序的 KubeDirectorApp 定义位于文件 kubedirector/deploy/example_catalog/cr-app-spark221e2.json 中。
~> cat kubedirector/deploy/example_catalog/cr-app-spark221e2.json
{
"apiVersion": "kubedirector.bluedata.io/v1alpha1",
"kind": "KubeDirectorApp",
"metadata": {
"name" : "spark221e2"
},
"spec" : {
"systemctlMounts": true,
"config": {
"node_services": [
{
"service_ids": [
"ssh",
"spark",
"spark_master",
"spark_worker"
],
…
应用程序集群的配置称为 KubeDirectorCluster 资源。示例 Spark 2.2.1 集群的 KubeDirectorCluster 定义位于文件
kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml 中。
~> cat kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml
apiVersion: "kubedirector.bluedata.io/v1alpha1"
kind: "KubeDirectorCluster"
metadata:
name: "spark221e2"
spec:
app: spark221e2
roles:
- name: controller
replicas: 1
resources:
requests:
memory: "4Gi"
cpu: "2"
limits:
memory: "4Gi"
cpu: "2"
- name: worker
replicas: 2
resources:
requests:
memory: "4Gi"
cpu: "2"
limits:
memory: "4Gi"
cpu: "2"
- name: jupyter
…
使用 KubeDirector 在 Kubernetes 上运行 Spark
使用 KubeDirector,可以轻松在 Kubernetes 上运行 Spark 集群。
首先,使用命令 kubectl version 验证 Kubernetes(版本 1.9 或更高)是否正在运行
~> kubectl version
Client Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T18:02:47Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T17:53:03Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
使用以下命令部署 KubeDirector 服务和示例 KubeDirectorApp 资源定义:
cd kubedirector
make deploy
这些将启动 KubeDirector pod:
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
kubedirector-58cf59869-qd9hb 1/1 Running 0 1m
kubectl get KubeDirectorApp 列出中已安装的 KubeDirector 应用程序
~> kubectl get KubeDirectorApp
NAME AGE
cassandra311 30m
spark211up 30m
spark221e2 30m
现在,您可以使用示例 KubeDirectorCluster 文件和 kubectl create -f deploy/example_clusters/cr-cluster-spark211up.yaml 命令
启动 Spark 2.2.1 集群。验证 Spark 集群已经启动:
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
kubedirector-58cf59869-djdwl 1/1 Running 0 19m
spark221e2-controller-zbg4d-0 1/1 Running 0 23m
spark221e2-jupyter-2km7q-0 1/1 Running 0 23m
spark221e2-worker-4gzbz-0 1/1 Running 0 23m
spark221e2-worker-4gzbz-1 1/1 Running 0 23m
现在运行的服务包括 Spark 服务:
~> kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d
svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 21s
svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 20s
svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 20s
svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 20s
svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 20s
将浏览器指向端口 31533 连接到 Spark 主节点 UI:
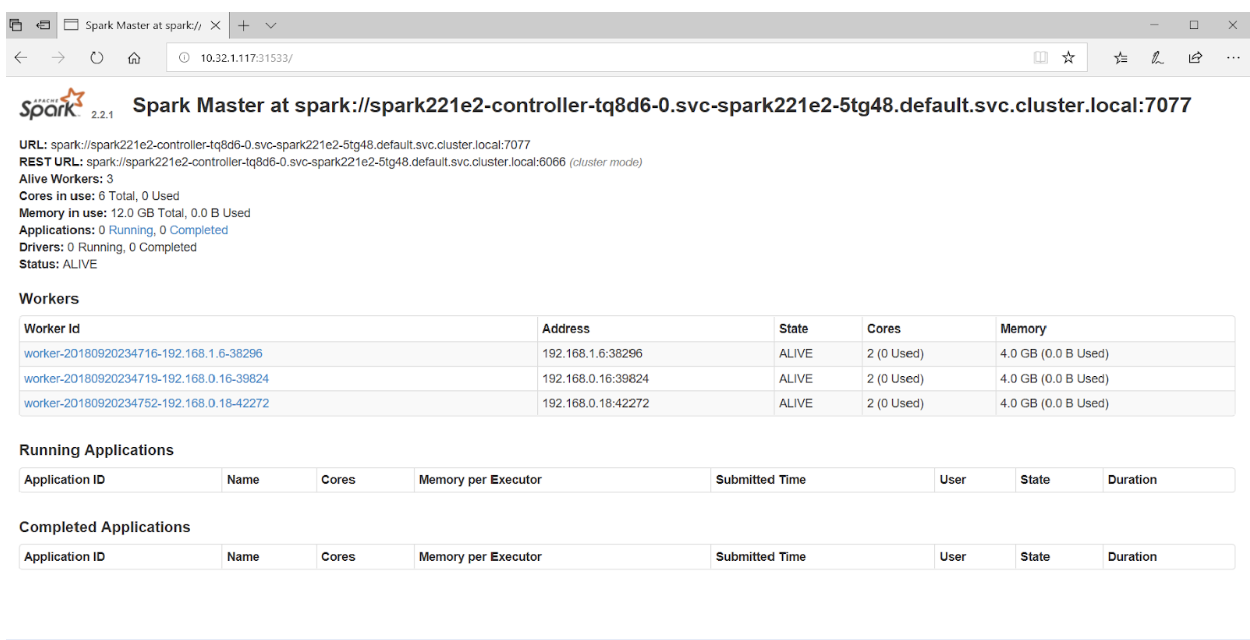
就是这样! 事实上,在上面的例子中,我们还部署了一个 Jupyter notebook 和 Spark 集群。
要启动另一个应用程序(例如 Cassandra),只需指定另一个 KubeDirectorApp 文件:
kubectl create -f deploy/example_clusters/cr-cluster-cassandra311.yaml
查看正在运行的 Cassandra 集群:
~> kubectl get pods
NAME READY STATUS RESTARTS AGE
cassandra311-seed-v24r6-0 1/1 Running 0 1m
cassandra311-seed-v24r6-1 1/1 Running 0 1m
cassandra311-worker-rqrhl-0 1/1 Running 0 1m
cassandra311-worker-rqrhl-1 1/1 Running 0 1m
kubedirector-58cf59869-djdwl 1/1 Running 0 1d
spark221e2-controller-tq8d6-0 1/1 Running 0 22m
spark221e2-jupyter-6989v-0 1/1 Running 0 22m
spark221e2-worker-d9892-0 1/1 Running 0 22m
spark221e2-worker-d9892-1 1/1 Running 0 22m
现在,您有一个 Spark 集群(带有 Jupyter notebook )和一个运行在 Kubernetes 上的 Cassandra 集群。
使用 kubectl get service 查看服务集。
~> kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d
svc-cassandra311-seed-v24r6-0 NodePort 10.96.94.204 <none> 22:31131/TCP,9042:30739/TCP 3m
svc-cassandra311-seed-v24r6-1 NodePort 10.106.144.52 <none> 22:30373/TCP,9042:32662/TCP 3m
svc-cassandra311-vhh29 ClusterIP None <none> 8888/TCP 3m
svc-cassandra311-worker-rqrhl-0 NodePort 10.109.61.194 <none> 22:31832/TCP,9042:31962/TCP 3m
svc-cassandra311-worker-rqrhl-1 NodePort 10.97.147.131 <none> 22:31454/TCP,9042:31170/TCP 3m
svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 24m
svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 24m
svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 24m
svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 24m
svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 24m
参与其中
KubeDirector 是一个完全开放源码的 Apache v2 授权项目 – 在我们称为 BlueK8s 的更广泛的计划中,它是多个开放源码项目中的第一个。 KubeDirector 的 pre-alpha 代码刚刚发布,我们希望您加入到不断增长的开发人员、贡献者和使用者社区。 在 Twitter 上关注 @BlueK8s,并通过以下渠道参与:
在 Kubernetes 上对 gRPC 服务器进行健康检查
作者: Ahmet Alp Balkan (Google)
gRPC 将成为本地云微服务间进行通信的通用语言。如果您现在将 gRPC 应用程序部署到 Kubernetes,您可能会想要了解配置健康检查的最佳方法。在本文中,我们将介绍 grpc-health-probe,这是 Kubernetes 原生的健康检查 gRPC 应用程序的方法。
如果您不熟悉,Kubernetes的 健康检查(存活探针和就绪探针)可以使您的应用程序在睡眠时保持可用状态。当检测到没有回应的 Pod 时,会将其标记为不健康,并使这些 Pod 重新启动或重新安排。
Kubernetes 原本 不支持 gRPC 健康检查。gRPC 的开发人员在 Kubernetes 中部署时可以采用以下三种方法:
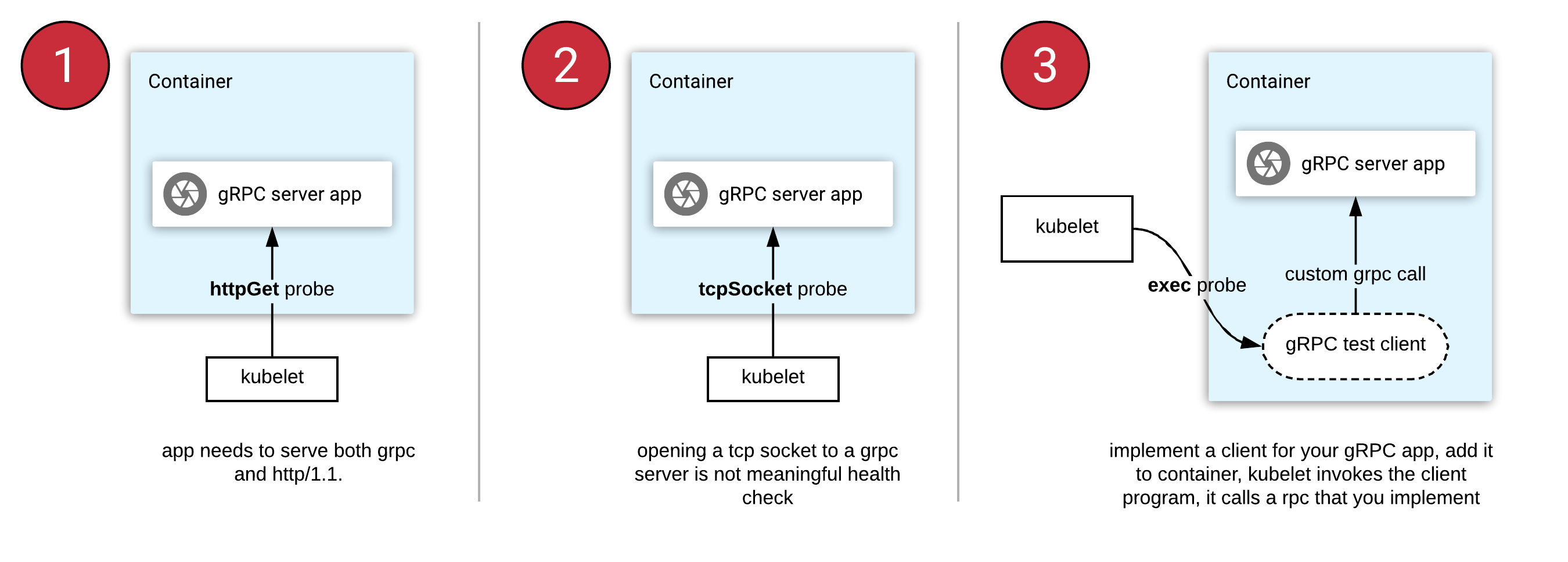
- httpGet prob: 不能与 gRPC 一起使用。您需要重构您的应用程序,必须同时支持 gRPC 和 HTTP/1.1 协议(在不同的端口号上)。
- tcpSocket probe: 打开 gRPC 服务器的 Socket 是没有意义的,因为它无法读取响应主体。
- exec probe: 将定期调用容器生态系统中的程序。对于 gRPC,这意味着您要自己实现健康 RPC,然后使用容器编写并交付客户端工具。
我们可以做得更好吗?这是肯定的。
介绍 “grpc-health-probe”
为了使上述 "exec probe" 方法标准化,我们需要:
- 可以在任何 gRPC 服务器中轻松实现的 标准 健康检查 "协议" 。
- 一种 标准 健康检查 "工具" ,可以轻松查询健康协议。
幸运的是,gRPC 具有 标准的健康检查协议。可以用任何语言轻松调用它。几乎所有实现 gRPC 的语言都附带了生成的代码和用于设置健康状态的实用程序。
如果您在 gRPC 应用程序中 实现 此健康检查协议,那么可以使用标准或通用工具调用 Check() 方法来确定服务器状态。
接下来您需要的是 "标准工具" grpc-health-probe。

使用此工具,您可以在所有 gRPC 应用程序中使用相同的健康检查配置。这种方法有以下要求:
- 用您喜欢的语言找到 gRPC 的 "健康" 模块并开始使用它(例如 Go 库)。
- 将二进制文件 grpc_health_probe 送到容器中。
- 配置 Kubernetes 的 "exec" 检查模块来调用容器中的 "grpc_health_probe" 工具。
在这种情况下,执行 "grpc_health_probe" 将通过 localhost 调用您的 gRPC 服务器,因为它们位于同一个容器中。
下一步工作
grpc-health-probe 项目仍处于初期阶段,需要您的反馈。它支持多种功能,例如与 TLS 服务器通信和配置延时连接/RPC。
如果您最近要在 Kubernetes 上运行 gRPC 服务器,请尝试使用 gRPC Health Protocol,并在您的 Deployment 中尝试 grpc-health-probe,然后 进行反馈。
更多内容
The Machines Can Do the Work, a Story of Kubernetes Testing, CI, and Automating the Contributor Experience
layout: blog title: '机器可以完成这项工作,一个关于 kubernetes 测试、CI 和自动化贡献者体验的故事' date: 2019-08-29
作者:Aaron Crickenberger(谷歌)和 Benjamin Elder(谷歌)
”大型项目有很多不那么令人兴奋,但却很辛苦的工作。比起辛苦工作,我们更重视把时间花在自动化重复性工作上,如果这项工作无法实现自动化,我们的文化就是承认并奖励所有类型的贡献。然而,英雄主义是不可持续的。“ - Kubernetes Community Values
像许多开源项目一样,Kubernetes 托管在 GitHub 上。 如果项目位于在开发人员已经工作的地方,使用的开发人员已经知道的工具和流程,那么参与的障碍将是最低的。 因此,该项目完全接受了这项服务:它是我们工作流程,问题跟踪,文档,博客平台,团队结构等的基础。
这个策略奏效了。 它运作良好,以至于该项目迅速超越了其贡献者的人类能力。 接下来是一次令人难以置信的自动化和创新之旅。 我们不仅需要在飞行途中重建我们的飞机而不会崩溃,我们需要将其转换为火箭飞船并发射到轨道。 我们需要机器来完成这项工作。
## 工作
最初,我们关注的事实是,我们需要支持复杂的分布式系统(如 Kubernetes)所要求的大量测试。 真实世界中的故障场景必须通过端到端(e2e)测试来执行,确保正确的功能。 不幸的是,e2e 测试容易受到薄片(随机故障)的影响,并且需要花费一个小时到一天才能完成。
进一步的经验揭示了机器可以为我们工作的其他领域:
- Pull Request 工作流程
- 贡献者是否签署了我们的 CLA?
- Pull Request 通过测试吗?
- Pull Request 可以合并吗?
- 合并提交是否通过了测试?
- 鉴别分类
- 谁应该审查 Pull Request?
- 是否有足够的信息将问题发送给合适的人?
- 问题是否依旧存在?
- 项目健康
- 项目中发生了什么?
- 我们应该注意什么?
当我们开发自动化来改善我们的情况时,我们遵循了以下几个指导原则:
- 遵循适用于 Kubernetes 的推送/拉取控制循环模式
- 首选无状态松散耦合服务
- 更倾向于授权整个社区权利,而不是赋予少数核心贡献者权力
- 做好自己的事,而不要重新造轮子
了解 Prow
这促使我们创建 Prow 作为我们自动化的核心组件。 Prow有点像 If This, Then That 用于 GitHub 事件, 内置 commands, plugins, 和实用程序。 我们在 Kubernetes 之上建立了 Prow,让我们不必担心资源管理和日程安排,并确保更愉快的运营体验。
Prow 让我们做以下事情:
- 允许我们的社区通过评论诸如“/priority critical-urgent”,“/assign mary”或“/close”之类的命令对 issues/Pull Requests 进行分类
- 根据用户更改的代码数量或创建的文件自动标记 Pull Requests
- 标出长时间保持不活动状态 issues/Pull Requests
- 自动合并符合我们PR工作流程要求的 Pull Requests
- 运行定义为Knative Builds的 Kubernetes Pods或 Jenkins jobs的 CI 作业
- 实施组织范围和重构 GitHub 仓库策略,如Knative Builds和GitHub labels
Prow最初由构建 Google Kubernetes Engine 的工程效率团队开发,并由 Kubernetes SIG Testing 的多个成员积极贡献。 Prow 已被其他几个开源项目采用,包括 Istio,JetStack,Knative 和 OpenShift。 Getting started with Prow需要一个 Kubernetes 集群和 kubectl apply starter.yaml(在 Kubernetes 集群上运行 pod)。
一旦我们安装了 Prow,我们就开始遇到其他的问题,因此需要额外的工具以支持 Kubernetes 所需的规模测试,包括:
- Boskos: 管理池中的作业资源(例如 GCP 项目),检查它们是否有工作并自动清理它们 (with monitoring)
- ghProxy: 优化用于 GitHub API 的反向代理 HTTP 缓存,以确保我们的令牌使用不会达到 API 限制 (with monitoring)
- Greenhouse: 允许我们使用远程 bazel 缓存为 Pull requests 提供更快的构建和测试结果 (with monitoring)
- Splice: 允许我们批量测试和合并 Pull requests,确保我们的合并速度不仅限于我们的测试速度
- Tide: 允许我们合并通过 GitHub 查询选择的 Pull requests,而不是在队列中排序,允许显着更高合并速度与拼接一起
## 关注项目健康状况
随着工作流自动化的实施,我们将注意力转向了项目健康。我们选择使用 Google Cloud Storage (GCS)作为所有测试数据的真实来源,允许我们依赖已建立的基础设施,并允许社区贡献结果。然后,我们构建了各种工具来帮助个人和整个项目理解这些数据,包括:
- Gubernator: 显示给定 Pull Request 的结果和测试历史
- Kettle: 将数据从 GCS 传输到可公开访问的 bigquery 数据集
- PR dashboard: 一个工作流程识别仪表板,允许参与者了解哪些 Pull Request 需要注意以及为什么
- Triage: 识别所有作业和测试中发生的常见故障
- Testgrid: 显示所有运行中给定作业的测试结果,汇总各组作业的测试结果
我们与云计算本地计算基金会(CNCF)联系,开发 DevStats,以便从我们的 GitHub 活动中收集见解,例如:
- Which prow commands are people most actively using
- PR reviews by contributor over time
- Time spent in each phase of our PR workflow
Into the Beyond
今天,Kubernetes 项目跨越了5个组织125个仓库。有31个特殊利益集团和10个工作组在项目内协调发展。在过去的一年里,该项目有 来自13800多名独立开发人员的参与。
在任何给定的工作日,我们的 Prow 实例运行超过10,000个 CI 工作; 从2017年3月到2018年3月,它有430万个工作岗位。 这些工作中的大多数涉及建立整个 Kubernetes 集群,并使用真实场景来实施它。 它们使我们能够确保所有受支持的 Kubernetes 版本跨云提供商,容器引擎和网络插件工作。 他们确保最新版本的 Kubernetes 能够启用各种可选功能,安全升级,满足性能要求,并跨架构工作。
今天来自CNCF的公告 - 注意到 Google Cloud 有开始将 Kubernetes 项目的云资源的所有权和管理权转让给 CNCF 社区贡献者,我们很高兴能够开始另一个旅程。 允许项目基础设施由贡献者社区拥有和运营,遵循对项目其余部分有效的相同开放治理模型。 听起来令人兴奋。 请来 kubernetes.slack.com 上的 #sig-testing on kubernetes.slack.com 与我们联系。
想了解更多? 快来看看这些资源:
使用 CSI 和 Kubernetes 实现卷的动态扩容
作者:Orain Xiong(联合创始人, WoquTech)
Kubernetes 本身有一个非常强大的存储子系统,涵盖了相当广泛的用例。而当我们计划使用 Kubernetes 构建产品级关系型数据库平台时,我们面临一个巨大的挑战:提供存储。本文介绍了如何扩展最新的 Container Storage Interface 0.2.0 和与 Kubernetes 集成,并演示了卷动态扩容的基本方面。
介绍
当我们专注于客户时,尤其是在金融领域,采用容器编排技术的情况大大增加。
他们期待着能用开源解决方案重新设计已经存在的整体应用程序,这些应用程序已经在虚拟化基础架构或裸机上运行了几年。
考虑到可扩展性和技术成熟程度,Kubernetes 和 Docker 排在我们选择列表的首位。但是将整体应用程序迁移到类似于 Kubernetes 之类的分布式容器编排平台上很具有挑战性,其中关系数据库对于迁移来说至关重要。
关于关系数据库,我们应该注意存储。Kubernetes 本身内部有一个非常强大的存储子系统。它非常有用,涵盖了相当广泛的用例。当我们计划在生产环境中使用 Kubernetes 运行关系型数据库时,我们面临一个巨大挑战:提供存储。目前,仍有一些基本功能尚未实现。特别是,卷的动态扩容。这听起来很无聊,但在除创建,删除,安装和卸载之类的操作外,它是非常必要的。
目前,扩展卷仅适用于这些存储供应商:
- gcePersistentDisk
- awsElasticBlockStore
- OpenStack Cinder
- glusterfs
- rbd
为了启用此功能,我们应该将特性开关 ExpandPersistentVolumes 设置为 true 并打开 PersistentVolumeClaimResize 准入插件。 一旦启用了 PersistentVolumeClaimResize,则其对应的 allowVolumeExpansion 字段设置为 true 的存储类将允许调整大小。
不幸的是,即使基础存储提供者具有此功能,也无法通过容器存储接口(CSI)和 Kubernetes 动态扩展卷。
本文将给出 CSI 的简化视图,然后逐步介绍如何在现有 CSI 和 Kubernetes 上引入新的扩展卷功能。最后,本文将演示如何动态扩展卷容量。
容器存储接口(CSI)
为了更好地了解我们将要做什么,我们首先需要知道什么是容器存储接口。当前,Kubernetes 中已经存在的存储子系统仍然存在一些问题。 存储驱动程序代码在 Kubernetes 核心存储库中维护,这很难测试。 但是除此之外,Kubernetes 还需要授予存储供应商许可,以将代码签入 Kubernetes 核心存储库。 理想情况下,这些应在外部实施。
CSI 旨在定义行业标准,该标准将使支持 CSI 的存储提供商能够在支持 CSI 的容器编排系统中使用。
该图描述了一种与 CSI 集成的高级 Kubernetes 原型:
- 引入了三个新的外部组件以解耦 Kubernetes 和存储提供程序逻辑
- 蓝色箭头表示针对 API 服务器进行调用的常规方法
- 红色箭头显示 gRPC 以针对 Volume Driver 进行调用
更多详细信息,请访问:https://github.com/container-storage-interface/spec/blob/master/spec.md
扩展 CSI 和 Kubernetes
为了实现在 Kubernetes 上扩展卷的功能,我们应该扩展几个组件,包括 CSI 规范,“in-tree” 卷插件,external-provisioner 和 external-attacher。
扩展CSI规范
最新的 CSI 0.2.0 仍未定义扩展卷的功能。应该引入新的3个 RPC,包括 RequiresFSResize, ControllerResizeVolume 和 NodeResizeVolume。
service Controller {
rpc CreateVolume (CreateVolumeRequest)
returns (CreateVolumeResponse) {}
……
rpc RequiresFSResize (RequiresFSResizeRequest)
returns (RequiresFSResizeResponse) {}
rpc ControllerResizeVolume (ControllerResizeVolumeRequest)
returns (ControllerResizeVolumeResponse) {}
}
service Node {
rpc NodeStageVolume (NodeStageVolumeRequest)
returns (NodeStageVolumeResponse) {}
……
rpc NodeResizeVolume (NodeResizeVolumeRequest)
returns (NodeResizeVolumeResponse) {}
}
扩展 “In-Tree” 卷插件
除了扩展的 CSI 规范之外,Kubernetes 中的 csiPlugin 接口还应该实现 expandablePlugin。csiPlugin 接口将扩展代表 ExpanderController 的 PersistentVolumeClaim。
type ExpandableVolumePlugin interface {
VolumePlugin
ExpandVolumeDevice(spec Spec, newSize resource.Quantity, oldSize resource.Quantity) (resource.Quantity, error)
RequiresFSResize() bool
}
实现卷驱动程序
最后,为了抽象化实现的复杂性,我们应该将单独的存储提供程序管理逻辑硬编码为以下功能,这些功能在 CSI 规范中已明确定义:
- CreateVolume
- DeleteVolume
- ControllerPublishVolume
- ControllerUnpublishVolume
- ValidateVolumeCapabilities
- ListVolumes
- GetCapacity
- ControllerGetCapabilities
- RequiresFSResize
- ControllerResizeVolume
展示
让我们以具体的用户案例来演示此功能。
- 为 CSI 存储供应商创建存储类
allowVolumeExpansion: true
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: csi-qcfs
parameters:
csiProvisionerSecretName: orain-test
csiProvisionerSecretNamespace: default
provisioner: csi-qcfsplugin
reclaimPolicy: Delete
volumeBindingMode: Immediate
-
在 Kubernetes 集群上部署包括存储供应商
csi-qcfsplugin在内的 CSI 卷驱动 -
创建 PVC
qcfs-pvc,它将由存储类csi-qcfs动态配置
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: qcfs-pvc
namespace: default
....
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 300Gi
storageClassName: csi-qcfs
- 创建 MySQL 5.7 实例以使用 PVC
qcfs-pvc - 为了反映完全相同的生产级别方案,实际上有两种不同类型的工作负载,包括: * 批量插入使 MySQL 消耗更多的文件系统容量 * 浪涌查询请求
- 通过编辑 pvc
qcfs-pvc配置动态扩展卷容量
Prometheus 和 Grafana 的集成使我们可以可视化相应的关键指标。
我们注意到中间的读数显示在批量插入期间 MySQL 数据文件的大小缓慢增加。 同时,底部读数显示文件系统在大约20分钟内扩展了两次,从 300 GiB 扩展到 400 GiB,然后扩展到 500 GiB。 同时,上半部分显示,扩展卷的整个过程立即完成,几乎不会影响 MySQL QPS。
结论
不管运行什么基础结构应用程序,数据库始终是关键资源。拥有更高级的存储子系统以完全支持数据库需求至关重要。这将有助于推动云原生技术的更广泛采用。
动态 Kubelet 配置
作者: Michael Taufen (Google)
编者注:这篇文章是一系列深度文章 的一部分,这个系列介绍了 Kubernetes 1.11 中的新增功能
为什么要进行动态 Kubelet 配置?
Kubernetes 提供了以 API 为中心的工具,可显着改善用于管理应用程序和基础架构的工作流程。 但是,在大多数的 Kubernetes 安装中,kubelet 在每个主机上作为本机进程运行,因此 未被标准 Kubernetes API 覆盖。
过去,这意味着集群管理员和服务提供商无法依靠 Kubernetes API 在活动集群中重新配置 Kubelets。 实际上,这要求操作员要 SSH 登录到计算机以执行手动重新配置,要么使用第三方配置管理自动化工具, 或创建已经安装了所需配置的新 VM,然后将工作迁移到新计算机上。 这些方法是特定于环境的,并且可能很耗时费力。
动态 Kubelet 配置使集群管理员和服务提供商能够通过 Kubernetes API 在活动集群中重新配置 Kubelet。
什么是动态 Kubelet 配置?
Kubernetes v1.10 使得可以通过 Beta 版本的配置文件 API 配置 kubelet。 Kubernetes 已经提供了用于在 API 服务器中存储任意文件数据的 ConfigMap 抽象。
动态 Kubelet 配置扩展了 Node 对象,以便 Node 可以引用包含相同类型配置文件的 ConfigMap。 当节点更新为引用新的 ConfigMap 时,关联的 Kubelet 将尝试使用新的配置。
它是如何工作的?
动态 Kubelet 配置提供以下核心功能:
- Kubelet 尝试使用动态分配的配置。
- Kubelet 将其配置已检查点的形式保存到本地磁盘,无需 API 服务器访问即可重新启动。
- Kubelet 在 Node 状态中报告已指定的、活跃的和最近已知良好的配置源。
- 当动态分配了无效的配置时,Kubelet 会自动退回到最后一次正确的配置,并在 Node 状态中报告错误。
要使用动态 Kubelet 配置功能,群集管理员或服务提供商将首先发布包含所需配置的 ConfigMap, 然后设置每个 Node.Spec.ConfigSource.ConfigMap 引用以指向新的 ConfigMap。 运营商可以以他们喜欢的速率更新这些参考,从而使他们能够执行新配置的受控部署。
每个 Kubelet 都会监视其关联的 Node 对象的更改。 更新 Node.Spec.ConfigSource.ConfigMap 引用后, Kubelet 将通过将其包含的文件通过检查点机制写入本地磁盘保存新的 ConfigMap。 然后,Kubelet 将退出,而操作系统级进程管理器将重新启动它。 请注意,如果未设置 Node.Spec.ConfigSource.ConfigMap 引用, 则 Kubelet 将使用其正在运行的计算机本地的一组标志和配置文件。
重新启动后,Kubelet 将尝试使用来自新检查点的配置。 如果新配置通过了 Kubelet 的内部验证,则 Kubelet 将更新 Node.Status.Config 用以反映它正在使用新配置。 如果新配置无效,则 Kubelet 将退回到其最后一个正确的配置,并在 Node.Status.Config 中报告错误。
请注意,默认的最后一次正确配置是 Kubelet 命令行标志与 Kubelet 的本地配置文件的组合。 与配置文件重叠的命令行标志始终优先于本地配置文件和动态配置,以实现向后兼容。
有关单个节点的配置更新的高级概述,请参见下图:
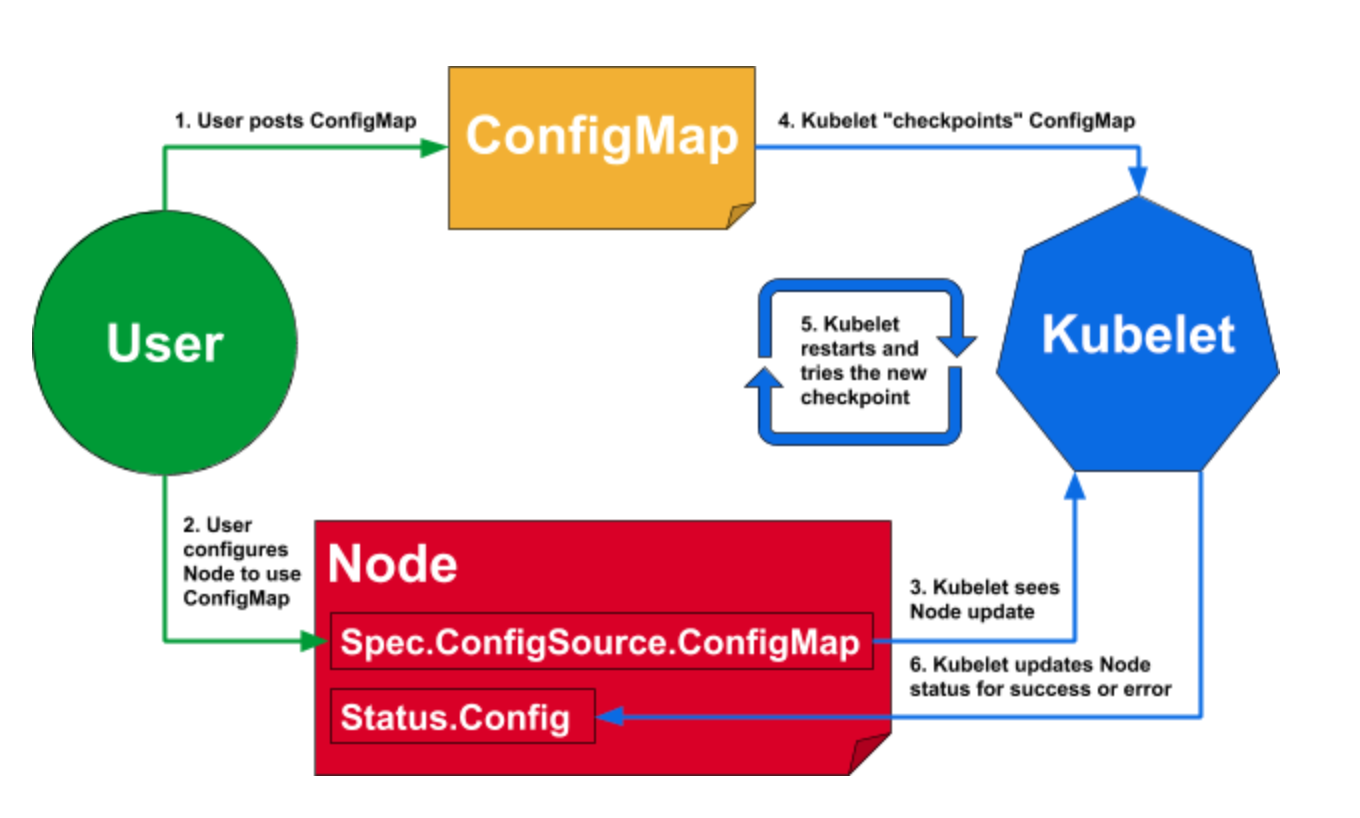
我如何了解更多?
请参阅/docs/tasks/administer-cluster/reconfigure-kubelet/上的官方教程, 其中包含有关用户工作流,某配置如何成为“最新的正确的”配置,Kubelet 如何对配置执行“检查点”操作等, 更多详细信息,以及可能的故障模式。
用于 Kubernetes 集群 DNS 的 CoreDNS GA 正式发布
作者:John Belamaric (Infoblox)
**编者注:这篇文章是 系列深度文章 中的一篇,介绍了 Kubernetes 1.11 新增的功能
介绍
在 Kubernetes 1.11 中,CoreDNS 已经达到基于 DNS 服务发现的 General Availability (GA),可以替代 kube-dns 插件。这意味着 CoreDNS 会作为即将发布的安装工具的选项之一上线。实际上,从 Kubernetes 1.11 开始,kubeadm 团队选择将它设为默认选项。
很久以来, kube-dns 集群插件一直是 Kubernetes 的一部分,用来实现基于 DNS 的服务发现。 通常,此插件运行平稳,但对于实现的可靠性、灵活性和安全性仍存在一些疑虑。
CoreDNS 是通用的、权威的 DNS 服务器,提供与 Kubernetes 向后兼容但可扩展的集成。它解决了 kube-dns 遇到的问题,并提供了许多独特的功能,可以解决各种用例。
在本文中,您将了解 kube-dns 和 CoreDNS 的实现有何差异,以及 CoreDNS 提供的一些非常有用的扩展。
实现差异
在 kube-dns 中,一个 Pod 中使用多个 容器:kubedns、dnsmasq、和 sidecar。kubedns 容器监视 Kubernetes API 并根据 Kubernetes DNS 规范 提供 DNS 记录,dnsmasq 提供缓存和存根域支持,sidecar 提供指标和健康检查。
随着时间的推移,此设置会导致一些问题。一方面,以往 dnsmasq 中的安全漏洞需要通过发布 Kubernetes 的安全补丁来解决。但是,由于 dnsmasq 处理存根域,而 kubedns 处理外部服务,因此您不能在外部服务中使用存根域,导致这个功能具有局限性(请参阅 dns#131)。
在 CoreDNS 中,所有这些功能都是在一个容器中完成的,该容器运行用 Go 编写的进程。所启用的不同插件可复制(并增强)在 kube-dns 中存在的功能。
配置 CoreDNS
在 kube-dns 中,您可以 修改 ConfigMap 来更改服务发现的行为。用户可以添加诸如为存根域提供服务、修改上游名称服务器以及启用联盟之类的功能。
在 CoreDNS 中,您可以类似地修改 CoreDNS Corefile 的 ConfigMap,以更改服务发现的工作方式。这种 Corefile 配置提供了比 kube-dns 中更多的选项,因为它是 CoreDNS 用于配置所有功能的主要配置文件,即使与 Kubernetes 不相关的功能也可以操作。
使用 kubeadm 将 kube-dns 升级到 CoreDNS 时,现有的 ConfigMap 将被用来为您生成自定义的 Corefile,包括存根域、联盟和上游名称服务器的所有配置。更多详细信息,请参见
使用 CoreDNS 进行服务发现。
错误修复和增强
在 CoreDNS 中解决了 kube-dn 的多个未解决问题,无论是默认配置还是某些自定义配置。
-
dns#55 - kube-dns 的自定义 DNS 条目 可以使用 kubernetes 插件 中的 "fallthrough" 机制,使用 rewrite 插件,或者分区使用不同的插件,例如 file 插件。
-
dns#116 - 对具有相同主机名的、提供无头服务服务的 Pod 仅设置了一个 A 记录。无需任何其他配置即可解决此问题。
-
dns#131 - externalName 未使用 stubDomains 设置。无需任何其他配置即可解决此问题。
-
dns#167 - 允许 skyDNS 为 A/AAAA 记录提供轮换。可以使用 负载均衡插件 配置等效功能。
-
dns#190 - kube-dns 无法以非 root 用户身份运行。今天,通过使用 non-default 镜像解决了此问题,但是在将来的版本中,它将成为默认的 CoreDNS 行为。
-
dns#232 - 在 dns srv 记录中修复 pod hostname 为 podname 是通过下面提到的 "endpoint_pod_names" 功能进行支持的增强功能。
指标
CoreDNS 默认配置的功能性行为与 kube-dns 相同。但是,你需要了解的差别之一是二者发布的指标是不同的。在 kube-dns 中,您将分别获得 dnsmasq 和 kubedns(skydns)的度量值。在 CoreDNS 中,存在一组完全不同的指标,因为它们在同一个进程中。您可以在 CoreDNS Prometheus 插件 页面上找到有关这些指标的更多详细信息。
一些特殊功能
标准的 CoreDNS Kubernetes 配置旨在与以前的 kube-dns 在行为上向后兼容。但是,通过进行一些配置更改,CoreDNS 允许您修改 DNS 服务发现在群集中的工作方式。这些功能中的许多功能仍要符合 Kubernetes DNS规范;它们在增强了功能的同时保持向后兼容。由于 CoreDNS 并非 仅 用于 Kubernetes,而是通用的 DNS 服务器,因此您可以做很多超出该规范的事情。
Pod 验证模式
在 kube-dns 中,Pod 名称记录是 "伪造的"。也就是说,任何 "a-b-c-d.namespace.pod.cluster.local" 查询都将返回 IP 地址 "a.b.c.d"。在某些情况下,这可能会削弱 TLS 提供的身份确认。因此,CoreDNS 提供了一种 "Pod 验证" 的模式,该模式仅在指定名称空间中存在具有该 IP 地址的 Pod 时才返回 IP 地址。
基于 Pod 名称的端点名称
在 kube-dns 中,使用无头服务时,可以使用 SRV 请求获取该服务的所有端点的列表:
dnstools# host -t srv headless
headless.default.svc.cluster.local has SRV record 10 33 0 6234396237313665.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 10 33 0 6662363165353239.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 10 33 0 6338633437303230.headless.default.svc.cluster.local.
dnstools#
但是,端点 DNS 名称(出于实际目的)是随机的。在 CoreDNS 中,默认情况下,您所获得的端点 DNS 名称是基于端点 IP 地址生成的:
dnstools# host -t srv headless
headless.default.svc.cluster.local has SRV record 0 25 443 172-17-0-14.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 0 25 443 172-17-0-18.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 0 25 443 172-17-0-4.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 0 25 443 172-17-0-9.headless.default.svc.cluster.local.
对于某些应用程序,你会希望在这里使用 Pod 名称,而不是 Pod IP 地址(例如,参见 kubernetes#47992 和 coredns#1190)。要在 CoreDNS 中启用此功能,请在 Corefile 中指定 "endpoint_pod_names" 选项,结果如下:
dnstools# host -t srv headless
headless.default.svc.cluster.local has SRV record 0 25 443 headless-65bb4c479f-qv84p.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 0 25 443 headless-65bb4c479f-zc8lx.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 0 25 443 headless-65bb4c479f-q7lf2.headless.default.svc.cluster.local.
headless.default.svc.cluster.local has SRV record 0 25 443 headless-65bb4c479f-566rt.headless.default.svc.cluster.local.
自动路径
CoreDNS 还具有一项特殊功能,可以改善 DNS 中外部名称请求的延迟。在 Kubernetes 中,Pod 的 DNS 搜索路径指定了一长串后缀。这一特点使得你可以针对集群中服务使用短名称 - 例如,上面的 "headless",而不是 "headless.default.svc.cluster.local"。但是,当请求一个外部名称(例如 "infoblox.com")时,客户端会进行几个无效的 DNS 查询,每次都需要从客户端到 kube-dns 往返(实际上是到 dnsmasq,然后到 kubedns),因为 禁用了负缓存)
- infoblox.com.default.svc.cluster.local -> NXDOMAIN
- infoblox.com.svc.cluster.local -> NXDOMAIN
- infoblox.com.cluster.local -> NXDOMAIN
- infoblox.com.your-internal-domain.com -> NXDOMAIN
- infoblox.com -> 返回有效记录
在 CoreDNS 中,可以启用 autopath 的可选功能,该功能使搜索路径在 服务器端 遍历。也就是说,CoreDNS 将基于源 IP 地址判断客户端 Pod 所在的命名空间,并且遍历此搜索列表,直到获得有效答案为止。由于其中的前三个是在 CoreDNS 本身内部解决的,因此它消除了客户端和服务器之间所有的来回通信,从而减少了延迟。
其他一些特定于 Kubernetes 的功能
在 CoreDNS 中,您可以使用标准 DNS 区域传输来导出整个 DNS 记录集。这对于调试服务以及将集群区导入其他 DNS 服务器很有用。
您还可以按名称空间或标签选择器进行过滤。这样,您可以运行特定的 CoreDNS 实例,该实例仅服务与过滤器匹配的记录,从而通过 DNS 公开受限的服务集。
可扩展性
除了上述功能之外,CoreDNS 还可轻松扩展,构建包含您独有的功能的自定义版本的 CoreDNS。例如,这一能力已被用于扩展 CoreDNS 来使用 unbound 插件 进行递归解析、使用 pdsql 插件 直接从数据库提供记录,以及使用 redisc 插件 与多个 CoreDNS 实例共享一个公共的 2 级缓存。
已添加的还有许多其他有趣的扩展,您可以在 CoreDNS 站点的 外部插件 页面上找到这些扩展。Kubernetes 和 Istio 用户真正感兴趣的是 kubernetai 插件,它允许单个 CoreDNS 实例连接到多个 Kubernetes 集群并在所有集群中提供服务发现 。
下一步工作
CoreDNS 是一个独立的项目,许多与 Kubernetes 不直接相关的功能正在开发中。但是,其中许多功能将在 Kubernetes 中具有对应的应用。例如,与策略引擎完成集成后,当请求无头服务时,CoreDNS 能够智能地选择返回哪个端点。这可用于将流量分流到到本地 Pod 或响应更快的 Pod。更多的其他功能正在开发中,当然作为一个开源项目,我们欢迎您提出建议并贡献自己的功能特性!
上述特征和差异是几个示例。CoreDNS 还可以做更多的事情。您可以在 CoreDNS 博客 上找到更多信息。
参与 CoreDNS
CoreDNS 是一个 CNCF 孵化项目。
我们在 Slack(和 GitHub)上最活跃:
- Slack: #coredns on https://slack.cncf.io
- GitHub: https://github.com/coredns/coredns
更多资源请浏览:
- Website: https://coredns.io
- Blog: https://blog.coredns.io
- Twitter: @corednsio
- Mailing list/group: coredns-discuss@googlegroups.com
IPVS-Based In-Cluster Load Balancing Deep Dive
作者: Jun Du(华为), Haibin Xie(华为), Wei Liang(华为)
注意: 这篇文章出自 系列深度文章 介绍 Kubernetes 1.11 的新特性
介绍
根据 Kubernetes 1.11 发布的博客文章, 我们宣布基于 IPVS 的集群内部服务负载均衡已达到一般可用性。 在这篇博客中,我们将带您深入了解该功能。
什么是 IPVS ?
IPVS (IP Virtual Server)是在 Netfilter 上层构建的,并作为 Linux 内核的一部分,实现传输层负载均衡。
IPVS 集成在 LVS(Linux Virtual Server,Linux 虚拟服务器)中,它在主机上运行,并在物理服务器集群前作为负载均衡器。IPVS 可以将基于 TCP 和 UDP 服务的请求定向到真实服务器,并使真实服务器的服务在单个IP地址上显示为虚拟服务。 因此,IPVS 自然支持 Kubernetes 服务。
为什么为 Kubernetes 选择 IPVS ?
随着 Kubernetes 的使用增长,其资源的可扩展性变得越来越重要。特别是,服务的可扩展性对于运行大型工作负载的开发人员/公司采用 Kubernetes 至关重要。
Kube-proxy 是服务路由的构建块,它依赖于经过强化攻击的 iptables 来实现支持核心的服务类型,如 ClusterIP 和 NodePort。 但是,iptables 难以扩展到成千上万的服务,因为它纯粹是为防火墙而设计的,并且基于内核规则列表。
尽管 Kubernetes 在版本v1.6中已经支持5000个节点,但使用 iptables 的 kube-proxy 实际上是将集群扩展到5000个节点的瓶颈。 一个例子是,在5000节点集群中使用 NodePort 服务,如果我们有2000个服务并且每个服务有10个 pod,这将在每个工作节点上至少产生20000个 iptable 记录,这可能使内核非常繁忙。
另一方面,使用基于 IPVS 的集群内服务负载均衡可以为这种情况提供很多帮助。 IPVS 专门用于负载均衡,并使用更高效的数据结构(哈希表),允许几乎无限的规模扩张。
基于 IPVS 的 Kube-proxy
参数更改
参数: --proxy-mode 除了现有的用户空间和 iptables 模式,IPVS 模式通过--proxy-mode = ipvs 进行配置。 它隐式使用 IPVS NAT 模式进行服务端口映射。
参数: --ipvs-scheduler
添加了一个新的 kube-proxy 参数来指定 IPVS 负载均衡算法,参数为 --ipvs-scheduler。 如果未配置,则默认为 round-robin 算法(rr)。
- rr: round-robin
- lc: least connection
- dh: destination hashing
- sh: source hashing
- sed: shortest expected delay
- nq: never queue
将来,我们可以实现特定于服务的调度程序(可能通过注释),该调度程序具有更高的优先级并覆盖该值。
参数: --cleanup-ipvs 类似于 --cleanup-iptables 参数,如果为 true,则清除在 IPVS 模式下创建的 IPVS 配置和 IPTables 规则。
参数: --ipvs-sync-period 刷新 IPVS 规则的最大间隔时间(例如'5s','1m')。 必须大于0。
参数: --ipvs-min-sync-period 刷新 IPVS 规则的最小间隔时间间隔(例如'5s','1m')。 必须大于0。
参数: --ipvs-exclude-cidrs 清除 IPVS 规则时 IPVS 代理不应触及的 CIDR 的逗号分隔列表,因为 IPVS 代理无法区分 kube-proxy 创建的 IPVS 规则和用户原始规则 IPVS 规则。 如果您在环境中使用 IPVS proxier 和您自己的 IPVS 规则,则应指定此参数,否则将清除原始规则。
设计注意事项
IPVS 服务网络拓扑
创建 ClusterIP 类型服务时,IPVS proxier 将执行以下三项操作:
- 确保节点中存在虚拟接口,默认为 kube-ipvs0
- 将服务 IP 地址绑定到虚拟接口
- 分别为每个服务 IP 地址创建 IPVS 虚拟服务器
这是一个例子:
# kubectl describe svc nginx-service
Name: nginx-service
...
Type: ClusterIP
IP: 10.102.128.4
Port: http 3080/TCP
Endpoints: 10.244.0.235:8080,10.244.1.237:8080
Session Affinity: None
# ip addr
...
73: kube-ipvs0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 1a:ce:f5:5f:c1:4d brd ff:ff:ff:ff:ff:ff
inet 10.102.128.4/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.102.128.4:3080 rr
-> 10.244.0.235:8080 Masq 1 0 0
-> 10.244.1.237:8080 Masq 1 0 0
请注意,Kubernetes 服务和 IPVS 虚拟服务器之间的关系是“1:N”。 例如,考虑具有多个 IP 地址的 Kubernetes 服务。 外部 IP 类型服务有两个 IP 地址 - 集群IP和外部 IP。 然后,IPVS 代理将创建2个 IPVS 虚拟服务器 - 一个用于集群 IP,另一个用于外部 IP。 Kubernetes 的 endpoint(每个IP +端口对)与 IPVS 虚拟服务器之间的关系是“1:1”。
删除 Kubernetes 服务将触发删除相应的 IPVS 虚拟服务器,IPVS 物理服务器及其绑定到虚拟接口的 IP 地址。
端口映射
IPVS 中有三种代理模式:NAT(masq),IPIP 和 DR。 只有 NAT 模式支持端口映射。 Kube-proxy 利用 NAT 模式进行端口映射。 以下示例显示 IPVS 服务端口3080到Pod端口8080的映射。
TCP 10.102.128.4:3080 rr
-> 10.244.0.235:8080 Masq 1 0 0
-> 10.244.1.237:8080 Masq 1 0
会话关系
IPVS 支持客户端 IP 会话关联(持久连接)。 当服务指定会话关系时,IPVS 代理将在 IPVS 虚拟服务器中设置超时值(默认为180分钟= 10800秒)。 例如:
# kubectl describe svc nginx-service
Name: nginx-service
...
IP: 10.102.128.4
Port: http 3080/TCP
Session Affinity: ClientIP
# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.102.128.4:3080 rr persistent 10800
IPVS 代理中的 Iptables 和 Ipset
IPVS 用于负载均衡,它无法处理 kube-proxy 中的其他问题,例如 包过滤,数据包欺骗,SNAT 等
IPVS proxier 在上述场景中利用 iptables。 具体来说,ipvs proxier 将在以下4种情况下依赖于 iptables:
- kube-proxy 以 --masquerade-all = true 开头
- 在 kube-proxy 启动中指定集群 CIDR
- 支持 Loadbalancer 类型服务
- 支持 NodePort 类型的服务
但是,我们不想创建太多的 iptables 规则。 所以我们采用 ipset 来减少 iptables 规则。 以下是 IPVS proxier 维护的 ipset 集表:
设置名称 成员 用法 KUBE-CLUSTER-IP 所有服务 IP + 端口 masquerade-all=true 或 clusterCIDR 指定的情况下进行伪装 KUBE-LOOP-BACK 所有服务 IP +端口+ IP 解决数据包欺骗问题 KUBE-EXTERNAL-IP 服务外部 IP +端口 将数据包伪装成外部 IP KUBE-LOAD-BALANCER 负载均衡器入口 IP +端口 将数据包伪装成 Load Balancer 类型的服务 KUBE-LOAD-BALANCER-LOCAL 负载均衡器入口 IP +端口 以及 externalTrafficPolicy=local 接受数据包到 Load Balancer externalTrafficPolicy=local KUBE-LOAD-BALANCER-FW 负载均衡器入口 IP +端口 以及 loadBalancerSourceRanges 使用指定的 loadBalancerSourceRanges 丢弃 Load Balancer类型Service的数据包 KUBE-LOAD-BALANCER-SOURCE-CIDR 负载均衡器入口 IP +端口 + 源 CIDR 接受 Load Balancer 类型 Service 的数据包,并指定loadBalancerSourceRanges KUBE-NODE-PORT-TCP NodePort 类型服务 TCP 将数据包伪装成 NodePort(TCP) KUBE-NODE-PORT-LOCAL-TCP NodePort 类型服务 TCP 端口,带有 externalTrafficPolicy=local 接受数据包到 NodePort 服务 使用 externalTrafficPolicy=local KUBE-NODE-PORT-UDP NodePort 类型服务 UDP 端口 将数据包伪装成 NodePort(UDP) KUBE-NODE-PORT-LOCAL-UDP NodePort 类型服务 UDP 端口 使用 externalTrafficPolicy=local 接受数据包到NodePort服务 使用 externalTrafficPolicy=local
通常,对于 IPVS proxier,无论我们有多少 Service/ Pod,iptables 规则的数量都是静态的。
在 IPVS 模式下运行 kube-proxy
目前,本地脚本,GCE 脚本和 kubeadm 支持通过导出环境变量(KUBE_PROXY_MODE=ipvs)或指定标志(--proxy-mode=ipvs)来切换 IPVS 代理模式。 在运行IPVS 代理之前,请确保已安装 IPVS 所需的内核模块。
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack_ipv4
最后,对于 Kubernetes v1.10,“SupportIPVSProxyMode” 默认设置为 “true”。 对于 Kubernetes v1.11 ,该选项已完全删除。 但是,您需要在v1.10之前为Kubernetes 明确启用 --feature-gates = SupportIPVSProxyMode = true。
参与其中
参与 Kubernetes 的最简单方法是加入众多特别兴趣小组 (SIG)中与您的兴趣一致的小组。 你有什么想要向 Kubernetes 社区广播的吗? 在我们的每周社区会议或通过以下渠道分享您的声音。
感谢您的持续反馈和支持。 在Stack Overflow上发布问题(或回答问题)
加入K8sPort的倡导者社区门户网站
在 Twitter 上关注我们 @Kubernetesio获取最新更新
在Slack上与社区聊天
分享您的 Kubernetes 故事
Airflow在Kubernetes中的使用(第一部分):一种不同的操作器
作者: Daniel Imberman (Bloomberg LP)
介绍
作为Bloomberg [继续致力于开发Kubernetes生态系统]的一部分(https://www.techatbloomberg.com/blog/bloomberg-awarded-first-cncf-end-user-award-contributions-kubernetes/),我们很高兴能够宣布Kubernetes Airflow Operator的发布; Apache Airflow的机制,一种流行的工作流程编排框架,使用Kubernetes API可以在本机启动任意的Kubernetes Pod。
什么是Airflow?
Apache Airflow是DevOps“Configuration As Code”理念的一种实现。 Airflow允许用户使用简单的Python对象DAG(有向无环图)启动多步骤流水线。 您可以在易于阅读的UI中定义依赖关系,以编程方式构建复杂的工作流,并监视调度的作业。
<img src =“/ images / blog / 2018-05-25-Airflow-Kubernetes-Operator / 2018-05-25-airflow_dags.png”width =“85%”alt =“Airflow DAGs”/>
<img src =“/ images / blog / 2018-05-25-Airflow-Kubernetes-Operator / 2018-05-25-airflow.png”width =“85%”alt =“Airflow UI”/>
为什么在Kubernetes上使用Airflow?
自成立以来,Airflow的最大优势在于其灵活性。 Airflow提供广泛的服务集成,包括Spark和HBase,以及各种云提供商的服务。 Airflow还通过其插件框架提供轻松的可扩展性。但是,该项目的一个限制是Airflow用户仅限于执行时Airflow站点上存在的框架和客户端。单个组织可以拥有各种Airflow工作流程,范围从数据科学流到应用程序部署。用例中的这种差异会在依赖关系管理中产生问题,因为两个团队可能会在其工作流程使用截然不同的库。
为了解决这个问题,我们使Kubernetes允许用户启动任意Kubernetes pod和配置。 Airflow用户现在可以在其运行时环境,资源和机密上拥有全部权限,基本上将Airflow转变为“您想要的任何工作”工作流程协调器。
Kubernetes运营商
在进一步讨论之前,我们应该澄清Airflow中的Operator是一个任务定义。 当用户创建DAG时,他们将使用像“SparkSubmitOperator”或“PythonOperator”这样的operator分别提交/监视Spark作业或Python函数。 Airflow附带了Apache Spark,BigQuery,Hive和EMR等框架的内置运算符。 它还提供了一个插件入口点,允许DevOps工程师开发自己的连接器。
Airflow用户一直在寻找更易于管理部署和ETL流的方法。 在增加监控的同时,任何解耦流程的机会都可以减少未来的停机等问题。 以下是Airflow Kubernetes Operator提供的好处:
- 提高部署灵活性:
Airflow的插件API一直为希望在其DAG中测试新功能的工程师提供了重要的福利。 不利的一面是,每当开发人员想要创建一个新的operator时,他们就必须开发一个全新的插件。 现在,任何可以在Docker容器中运行的任务都可以通过完全相同的运算符访问,而无需维护额外的Airflow代码。
- 配置和依赖的灵活性:
对于在静态Airflow工作程序中运行的operator,依赖关系管理可能变得非常困难。 如果开发人员想要运行一个需要SciPy的任务和另一个需要NumPy的任务,开发人员必须维护所有Airflow节点中的依赖关系或将任务卸载到其他计算机(如果外部计算机以未跟踪的方式更改,则可能导致错误)。 自定义Docker镜像允许用户确保任务环境,配置和依赖关系完全是幂等的。
- 使用kubernetes Secret以增加安全性:
处理敏感数据是任何开发工程师的核心职责。 Airflow用户总有机会在严格条款的基础上隔离任何API密钥,数据库密码和登录凭据。 使用Kubernetes运算符,用户可以利用Kubernetes Vault技术存储所有敏感数据。 这意味着Airflow工作人员将永远无法访问此信息,并且可以容易地请求仅使用他们需要的密码信息构建pod。
#架构
<img src =“/ images / blog / 2018-05-25-Airflow-Kubernetes-Operator / 2018-05-25-airflow-architecture.png”width =“85%”alt =“Airflow Architecture”/>
Kubernetes Operator使用Kubernetes Python客户端生成由APIServer处理的请求(1)。 然后,Kubernetes将使用您定义的需求启动您的pod(2)。映像文件中将加载环境变量,Secret和依赖项,执行单个命令。 一旦启动作业,operator只需要监视跟踪日志的状况(3)。 用户可以选择将日志本地收集到调度程序或当前位于其Kubernetes集群中的任何分布式日志记录服务。
#使用Kubernetes Operator
##一个基本的例子
以下DAG可能是我们可以编写的最简单的示例,以显示Kubernetes Operator的工作原理。 这个DAG在Kubernetes上创建了两个pod:一个带有Python的Linux发行版和一个没有它的基本Ubuntu发行版。 Python pod将正确运行Python请求,而没有Python的那个将向用户报告失败。 如果Operator正常工作,则应该完成“passing-task”pod,而“falling-task”pod则向Airflow网络服务器返回失败。
from airflow import DAG
from datetime import datetime, timedelta
from airflow.contrib.operators.kubernetes_pod_operator import KubernetesPodOperator
from airflow.operators.dummy_operator import DummyOperator
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime.utcnow(),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5)
}
dag = DAG(
'kubernetes_sample', default_args=default_args, schedule_interval=timedelta(minutes=10))
start = DummyOperator(task_id='run_this_first', dag=dag)
passing = KubernetesPodOperator(namespace='default',
image="Python:3.6",
cmds=["Python","-c"],
arguments=["print('hello world')"],
labels={"foo": "bar"},
name="passing-test",
task_id="passing-task",
get_logs=True,
dag=dag
)
failing = KubernetesPodOperator(namespace='default',
image="ubuntu:1604",
cmds=["Python","-c"],
arguments=["print('hello world')"],
labels={"foo": "bar"},
name="fail",
task_id="failing-task",
get_logs=True,
dag=dag
)
passing.set_upstream(start)
failing.set_upstream(start)
##但这与我的工作流程有什么关系?
虽然这个例子只使用基本映像,但Docker的神奇之处在于,这个相同的DAG可以用于您想要的任何图像/命令配对。 以下是推荐的CI / CD管道,用于在Airflow DAG上运行生产就绪代码。
1:github中的PR
使用Travis或Jenkins运行单元和集成测试,请您的朋友PR您的代码,并合并到主分支以触发自动CI构建。
2:CI / CD构建Jenkins - > Docker Image
3:Airflow启动任务
最后,更新您的DAG以反映新版本,您应该准备好了!
production_task = KubernetesPodOperator(namespace='default',
# image="my-production-job:release-1.0.1", <-- old release
image="my-production-job:release-1.0.2",
cmds=["Python","-c"],
arguments=["print('hello world')"],
name="fail",
task_id="failing-task",
get_logs=True,
dag=dag
)
#启动测试部署
由于Kubernetes运营商尚未发布,我们尚未发布官方helm 图表或operator(但两者目前都在进行中)。 但是,我们在下面列出了基本部署的说明,并且正在积极寻找测试人员来尝试这一新功能。 要试用此系统,请按以下步骤操作:
##步骤1:将kubeconfig设置为指向kubernetes集群
##步骤2:clone Airflow 仓库:
运行git clone https:// github.com / apache / incubator-airflow.git来clone官方Airflow仓库。
##步骤3:运行
为了运行这个基本Deployment,我们正在选择我们目前用于Kubernetes Executor的集成测试脚本(将在本系列的下一篇文章中对此进行解释)。 要启动此部署,请运行以下三个命令:
sed -ie "s/KubernetesExecutor/LocalExecutor/g" scripts/ci/kubernetes/kube/configmaps.yaml
./scripts/ci/kubernetes/Docker/build.sh
./scripts/ci/kubernetes/kube/deploy.sh
在我们继续之前,让我们讨论这些命令正在做什么:
sed -ie“s / KubernetesExecutor / LocalExecutor / g”scripts / ci / kubernetes / kube / configmaps.yaml
Kubernetes Executor是另一种Airflow功能,允许动态分配任务已解决幂等pod的问题。我们将其切换到LocalExecutor的原因只是一次引入一个功能。如果您想尝试Kubernetes Executor,欢迎您跳过此步骤,但我们将在以后的文章中详细介绍。
./scripts/ci/kubernetes/Docker/build.sh
此脚本将对Airflow主分支代码进行打包,以根据Airflow的发行文件构建Docker容器
./scripts/ci/kubernetes/kube/deploy.sh
最后,我们在您的群集上创建完整的Airflow部署。这包括Airflow配置,postgres后端,webserver +调度程序以及之间的所有必要服务。需要注意的一点是,提供的角色绑定是集群管理员,因此如果您没有该集群的权限级别,可以在scripts / ci / kubernetes / kube / airflow.yaml中进行修改。
##步骤4:登录您的网络服务器
现在您的Airflow实例正在运行,让我们来看看UI!用户界面位于Airflow pod的8080端口,因此只需运行即可
WEB=$(kubectl get pods -o go-template --template '{{range .items}}{{.metadata.name}}{{"\n"}}{{end}}' | grep "airflow" | head -1)
kubectl port-forward $WEB 8080:8080
现在,Airflow UI将存在于http://localhost:8080上。 要登录,只需输入airflow /airflow,您就可以完全访问Airflow Web UI。
##步骤5:上传测试文档
要修改/添加自己的DAG,可以使用kubectl cp将本地文件上传到Airflow调度程序的DAG文件夹中。 然后,Airflow将读取新的DAG并自动将其上传到其系统。 以下命令将任何本地文件上载到正确的目录中:
kubectl cp
##步骤6:使用它!
#那么我什么时候可以使用它?
虽然此功能仍处于早期阶段,但我们希望在未来几个月内发布该功能以进行广泛发布。
#参与其中
此功能只是将Apache Airflow集成到Kubernetes中的多项主要工作的开始。 Kubernetes Operator已合并到Airflow的1.10发布分支(实验模式中的执行模块),以及完整的k8s本地调度程序称为Kubernetes Executor(即将发布文章)。这些功能仍处于早期采用者/贡献者可能对这些功能的未来产生巨大影响的阶段。
对于有兴趣加入这些工作的人,我建议按照以下步骤:
*加入airflow-dev邮件列表dev@airflow.apache.org。
*在[Apache Airflow JIRA]中提出问题(https://issues.apache.org/jira/projects/AIRFLOW/issues/)
*周三上午10点太平洋标准时间加入我们的SIG-BigData会议。
*在kubernetes.slack.com上的#sig-big-data找到我们。
特别感谢Apache Airflow和Kubernetes社区,特别是Grant Nicholas,Ben Goldberg,Anirudh Ramanathan,Fokko Dreisprong和Bolke de Bruin,感谢您对这些功能的巨大帮助以及我们未来的努力。
Kubernetes 内的动态 Ingress
作者: Richard Li (Datawire)
Kubernetes 可以轻松部署由许多微服务组成的应用程序,但这种架构的关键挑战之一是动态地将流量路由到这些服务中的每一个。 一种方法是使用 Ambassador, 一个基于 Envoy Proxy 构建的 Kubernetes 原生开源 API 网关。 Ambassador 专为动态环境而设计,这类环境中的服务可能被频繁添加或删除。
Ambassador 使用 Kubernetes 注解进行配置。 注解用于配置从给定 Kubernetes 服务到特定 URL 的具体映射关系。 每个映射中可以包括多个注解,用于配置路由。 注解的例子有速率限制、协议、跨源请求共享(CORS)、流量影射和路由规则等。
一个简单的 Ambassador 示例
Ambassador 通常作为 Kubernetes Deployment 来安装,也可以作为 Helm Chart 使用。 配置 Ambassador 时,请使用 Ambassador 注解创建 Kubernetes 服务。 下面是一个例子,用来配置 Ambassador,将针对 /httpbin/ 的请求路由到公共的 httpbin.org 服务:
apiVersion: v1
kind: Service
metadata:
name: httpbin
annotations:
getambassador.io/config: |
---
apiVersion: ambassador/v0
kind: Mapping
name: httpbin_mapping
prefix: /httpbin/
service: httpbin.org:80
host_rewrite: httpbin.org
spec:
type: ClusterIP
ports:
- port: 80
例子中创建了一个 Mapping 对象,其 prefix 设置为 /httpbin/,service 名称为 httpbin.org。 其中的 host_rewrite 注解指定 HTTP 的 host 头部字段应设置为 httpbin.org。
Kubeflow
Kubeflow 提供了一种简单的方法,用于在 Kubernetes 上轻松部署机器学习基础设施。 Kubeflow 团队需要一个代理,为 Kubeflow 中所使用的各种服务提供集中化的认证和路由能力;Kubeflow 中许多服务本质上都是生命期很短的。
服务配置
有了 Ambassador,Kubeflow 可以使用分布式模型进行配置。 Ambassador 不使用集中的配置文件,而是允许每个服务通过 Kubernetes 注解在 Ambassador 中配置其路由。 下面是一个简化的配置示例:
---
apiVersion: ambassador/v0
kind: Mapping
name: tfserving-mapping-test-post
prefix: /models/test/
rewrite: /model/test/:predict
method: POST
service: test.kubeflow:8000
示例中,“test” 服务使用 Ambassador 注解来为服务动态配置路由。 所配置的路由仅在 HTTP 方法是 POST 时触发;注解中同时还给出了一条重写规则。
Kubeflow 和 Ambassador
通过 Ambassador,Kubeflow 可以使用 Kubernetes 注解轻松管理路由。
Kubeflow 配置同一个 Ingress 对象,将流量定向到 Ambassador,然后根据需要创建具有 Ambassador 注解的服务,以将流量定向到特定后端。
例如,在部署 TensorFlow 服务时,Kubeflow 会创建 Kubernetes 服务并为其添加注解,
以便用户能够在 https://<ingress主机>/models/<模型名称>/ 处访问到模型本身。
Kubeflow 还可以使用 Envoy Proxy 来进行实际的 L7 路由。
通过 Ambassador,Kubeflow 能够更充分地利用 URL 重写和基于方法的路由等额外的路由配置能力。
如果您对在 Kubeflow 中使用 Ambassador 感兴趣,标准的 Kubeflow 安装会自动安装和配置 Ambassador。
如果您有兴趣将 Ambassador 用作 API 网关或 Kubernetes 的 Ingress 解决方案, 请参阅 Ambassador 入门指南。
Kubernetes 这四年
作者:Joe Beda( Heptio 首席技术官兼创始人) 2014 年 6 月 6 日,我检查了 Kubernetes 公共代码库的第一次 commit 。许多人会认为这是故事开始的地方。这难道不是一切开始的地方吗?但这的确不能把整个过程说清楚。

第一次 commit 涉及的人员众多,自那以后 Kubernetes 的成功归功于更大的开发者阵容。 Kubernetes 建立在过去十年曾经在 Google 的 Borg 集群管理系统中验证过的思路之上。而 Borg 本身也是 Google 和其他公司早期努力的结果。 具体而言,Kubernetes 最初是从 Brendan Burns 的一些原型开始,结合我和 Craig McLuckie 正在进行的工作,以更好地将 Google 内部实践与 Google Cloud 的经验相结合。 Brendan,Craig 和我真的希望人们使用它,所以我们建议将这个原型构建为一个开源项目,将 Borg 的最佳创意带给大家。 在我们所有人同意后,就开始着手构建这个系统了。我们采用了 Brendan 的原型(Java 语言),用 Go 语言重写了它,并且以上述核心思想去构建该系统。到这个时候,团队已经成长为包括 Ville Aikas,Tim Hockin,Brian Grant,Dawn Chen 和 Daniel Smith。一旦我们有了一些工作需求,有人必须承担一些脱敏的工作,以便为公开发布做好准备。这个角色最终由我承担。当时,我不知道这件事情的重要性,我创建了一个新的仓库,把代码搬过来,然后进行了检查。所以在我第一次提交 public commit 之前,就有工作已经启动了。 那时 Kubernetes 的版本只是现在版本的简单雏形。核心概念已经有了,但非常原始。例如,Pods 被称为 Tasks,这在我们推广前一天就被替换。2014年6月10日 Eric Brewe 在第一届 DockerCon 上的演讲中正式发布了 Kubernetes 。您可以在此处观看该视频:
但是,无论多么原始,这小小的一步足以激起一个开始强大而且变得更强大的社区的兴趣。在过去的四年里,Kubernetes 已经超出了我们所有人的期望。我们对 Kubernetes 社区的所有人员表示感谢。该项目所取得的成功不仅基于代码和技术,还基于一群出色的人聚集在一起所做的有意义的事情。Sarah Novotny 策划的一套 Kubernetes 价值观是以上最好的表现形式。 让我们一起期待下一个4年!🎉🎉🎉
Kubernetes 1 11:向 discuss kubernetes 问好
作者: Jorge Castro (Heptio)
就一个超过 35,000 人的全球性社区而言,参与其中时沟通是非常关键的。 跟踪 Kubernetes 社区中的所有内容可能是一项艰巨的任务。 一方面,我们有官方资源,如 Stack Overflow,GitHub 和邮件列表,另一方面,我们有更多瞬时性的资源,如 Slack,你可以加入进去、与某人聊天然后各走各路。
Slack 非常适合随意和及时的对话,并与其他社区成员保持联系,但未来很难轻易引用通信。此外,在35,000名参与者中提问并得到回答很难。邮件列表在有问题尝试联系特定人群并且想要跟踪大家的回应时非常有用,但是对于大量人员来说可能是麻烦的。 Stack Overflow 和 GitHub 非常适合在涉及代码的项目或问题上进行协作,并且如果在将来要进行搜索也很有用,但某些主题如“你最喜欢的 CI/CD 工具是什么”或“Kubectl提示和技巧“在那里是没有意义的。
虽然我们目前的各种沟通渠道对他们自己来说都很有价值,但我们发现电子邮件和实时聊天之间仍然存在差距。在网络的其他部分,许多其他开源项目,如 Docker、Mozilla、Swift、Ghost 和 Chef,已经成功地在Discourse之上构建社区,一个开放的讨论平台。那么,如果我们可以使用这个工具将我们的讨论结合在一个平台下,使用开放的API,或许也不会让我们的大部分信息消失在网络中呢?只有一种方法可以找到:欢迎来到discuss.kubernetes.io
马上,我们有用户可以浏览的类别。检查和发布这些类别允许用户参与他们可能感兴趣的事情,而无需订阅列表。精细的通知控件允许用户只订阅他们想要的类别或标签,并允许通过电子邮件回复主题。
生态系统合作伙伴和开发人员现在有一个地方可以宣布项目,他们正在为用户工作,而不会想知道它是否会在官方列表中脱离主题。我们可以让这个地方不仅仅是关于核心 Kubernetes,而是关于我们社区正在建设的数百个精彩工具。
这个新的社区论坛为人们提供了一个可以讨论 Kubernetes 的地方,也是开发人员在 Kubernetes 周围发布事件的声音板,同时可以搜索并且更容易被更广泛的用户访问。
在 Kubernetes 上开发
作者: Michael Hausenblas (Red Hat), Ilya Dmitrichenko (Weaveworks)
您将如何开发一个 Kubernates 应用?也就是说,您如何编写并测试一个要在 Kubernates 上运行的应用程序?本文将重点介绍在独自开发或者团队协作中,您可能希望了解到的为了成功编写 Kubernetes 应用程序而需面临的挑战,工具和方法。
我们假定您是一位开发人员,有您钟爱的编程语言,编辑器/IDE(集成开发环境),以及可用的测试框架。在针对 Kubernates 开发应用时,最重要的目标是减少对当前工作流程的影响,改变越少越好,尽量做到最小。举个例子,如果您是 Node.js 开发人员,习惯于那种热重载的环境 - 也就是说您在编辑器里一做保存,正在运行的程序就会自动更新 - 那么跟容器、容器镜像或者镜像仓库打交道,又或是跟 Kubernetes 部署、triggers 以及更多头疼东西打交道,不仅会让人难以招架也真的会让开发过程完全失去乐趣。
在下文中,我们将首先讨论 Kubernetes 总体开发环境,然后回顾常用工具,最后进行三个示例性工具的实践演练。这些工具允许针对 Kubernetes 进行本地应用程序的开发和迭代。
您的集群运行在哪里?
作为开发人员,您既需要考虑所针对开发的 Kubernetes 集群运行在哪里,也需要思考开发环境如何配置。概念上,有四种开发模式:
许多工具支持纯 offline 开发,包括 Minikube、Docker(Mac 版/Windows 版)、Minishift 以及下文中我们将详细讨论的几种。有时,比如说在一个微服务系统中,已经有若干微服务在运行,proxied 模式(通过转发把数据流传进传出集群)就非常合适,Telepresence 就是此类工具的一个实例。live 模式,本质上是您基于一个远程集群进行构建和部署。最后,纯 online 模式意味着您的开发环境和运行集群都是远程的,典型的例子是 Eclipse Che 或者 Cloud 9。现在让我们仔细看看离线开发的基础:在本地运行 Kubernetes。
Minikube 在更加喜欢于本地 VM 上运行 Kubernetes 的开发人员中,非常受欢迎。不久前,Docker 的 Mac 版和 Windows 版,都试验性地开始自带 Kubernetes(需要下载 “edge” 安装包)。在两者之间,以下原因也许会促使您选择 Minikube 而不是 Docker 桌面版:
- 您已经安装了 Minikube 并且它运行良好
- 您想等到 Docker 出稳定版本
- 您是 Linux 桌面用户
- 您是 Windows 用户,但是没有配有 Hyper-V 的 Windows 10 Pro
运行一个本地集群,开发人员可以离线工作,不用支付云服务。云服务收费一般不会太高,并且免费的等级也有,但是一些开发人员不喜欢为了使用云服务而必须得到经理的批准,也不愿意支付意想不到的费用,比如说忘了下线而集群在周末也在运转。
有些开发人员却更喜欢远程的 Kubernetes 集群,这样他们通常可以获得更大的计算能力和存储容量,也简化了协同工作流程。您可以更容易的拉上一个同事来帮您调试,或者在团队内共享一个应用的使用。再者,对某些开发人员来说,尽可能的让开发环境类似生产环境至关重要,尤其是您依赖外部厂商的云服务时,如:专有数据库、云对象存储、消息队列、外商的负载均衡器或者邮件投递系统。
总之,无论您选择本地或者远程集群,理由都足够多。这很大程度上取决于您所处的阶段:从早期的原型设计/单人开发到后期面对一批稳定微服务的集成。
既然您已经了解到运行环境的基本选项,那么我们就接着讨论如何迭代式的开发并部署您的应用。
常用工具
我们现在回顾既可以允许您可以在 Kubernetes 上开发应用程序又尽可能最小地改变您现有的工作流程的一些工具。我们致力于提供一份不偏不倚的描述,也会提及使用某个工具将会意味着什么。
请注意这很棘手,因为即使在成熟定型的技术中做选择,比如说在 JSON、YAML、XML、REST、gRPC 或者 SOAP 之间做选择,很大程度也取决于您的背景、喜好以及公司环境。在 Kubernetes 生态系统内比较各种工具就更加困难,因为技术发展太快,几乎每周都有新工具面市;举个例子,仅在准备这篇博客的期间,Gitkube 和 Watchpod 相继出品。为了进一步覆盖到这些新的,以及一些相关的已推出的工具,例如 Weave Flux 和 OpenShift 的 S2I,我们计划再写一篇跟进的博客。
Draft
Draft 旨在帮助您将任何应用程序部署到 Kubernetes。它能够检测到您的应用所使用的编程语言,并且生成一份 Dockerfile 和 Helm 图表。然后它替您启动构建并且依照 Helm 图表把所生产的镜像部署到目标集群。它也可以让您很容易地设置到 localhost 的端口映射。
这意味着:
- 用户可以任意地自定义 Helm 图表和 Dockerfile 模版,或者甚至创建一个 custom pack(使用 Dockerfile、Helm 图表以及其他)以备后用
- 要想理解一个应用应该怎么构建并不容易,在某些情况下,用户也许需要修改 Draft 生成的 Dockerfile 和 Heml 图表
- 如果使用 Draft version 0.12.01 或者更老版本,每一次用户想要测试一个改动,他们需要等 Draft 把代码拷贝到集群,运行构建,推送镜像并且发布更新后的图表;这些步骤可能进行得很快,但是每一次用户的改动都会产生一个镜像(无论是否提交到 git )
- 在 Draft 0.12.0版本,构建是本地进行的
- 用户不能选择 Helm 以外的工具进行部署
- 它可以监控本地的改动并且触发部署,但是这个功能默认是关闭的
- 它允许开发人员使用本地或者远程的 Kubernates 集群
- 如何部署到生产环境取决于用户, Draft 的作者推荐了他们的另一个项目 - Brigade
- 可以代替 Skaffold, 并且可以和 Squash 一起使用
更多信息:
【1】:此处疑为 0.11.0,因为 0.12.0 已经支持本地构建,见下一条
Skaffold
Skaffold 让 CI 集成具有可移植性的,它允许用户采用不同的构建系统,镜像仓库和部署工具。它不同于 Draft,同时也具有一定的可比性。它具有生成系统清单的基本能力,但那不是一个重要功能。Skaffold 易于扩展,允许用户在构建和部署应用的每一步选取相应的工具。
这意味着:
- 模块化设计
- 不依赖于 CI,用户不需要 Docker 或者 Kubernetes 插件
- 没有 CI 也可以工作,也就是说,可以在开发人员的电脑上工作
- 它可以监控本地的改动并且触发部署
- 它允许开发人员使用本地或者远程的 Kubernetes 集群
- 它可以用于部署生产环境,用户可以精确配置,也可以为每一套目标环境提供不同的生产线
- 可以代替 Draft,并且和其他工具一起使用
更多信息:
Squash
Squash 包含一个与 Kubernetes 全面集成的调试服务器,以及一个 IDE 插件。它允许您插入断点和所有的调试操作,就像您所习惯的使用 IDE 调试一个程序一般。它允许您将调试器应用到 Kubernetes 集群中运行的 pod 上,从而让您可以使用 IDE 调试 Kubernetes 集群。
这意味着:
- 不依赖您选择的其它工具
- 需要一组特权 DaemonSet
- 可以和流行 IDE 集成
- 支持 Go、Python、Node.js、Java 和 gdb
- 用户必须确保容器中的应用程序使编译时使用了调试符号
- 可与此处描述的任何其他工具结合使用
- 它可以与本地或远程 Kubernetes 集群一起使用
更多信息:
Telepresence
Telepresence 使用双向代理将开发人员工作站上运行的容器与远程 Kubernetes 集群连接起来,并模拟集群内环境以及提供对配置映射和机密的访问。它消除了将应用部署到集群的需要,并利用本地容器抽象出网络和文件系统接口,以使其看起来应用好像就在集群中运行,从而改进容器应用程序开发的迭代时间。
这意味着:
- 它不依赖于其它您选取的工具
- 可以同 Squash 一起使用,但是 Squash 必须用于调试集群中的 pods,而传统/本地调试器需要用于调试通过 Telepresence 连接到集群的本地容器
- Telepresence 会产生一些网络延迟
- 它通过辅助进程提供连接 - sshuttle,基于SSH的一个工具
- 还提供了使用 LD_PRELOAD/DYLD_INSERT_LIBRARIES 的更具侵入性的依赖注入模式
- 它最常用于远程 Kubernetes 集群,但也可以与本地集群一起使用
更多信息:
- Telepresence: fast, realistic local development for Kubernetes microservices
- Getting Started Guide
- How It Works
Ksync
Ksync 在本地计算机和运行在 Kubernetes 中的容器之间同步应用程序代码(和配置),类似于 oc rsync 在 OpenShift 中的角色。它旨在通过消除构建和部署步骤来缩短应用程序开发的迭代时间。
这意味着:
- 它绕过容器图像构建和修订控制
- 使用编译语言的用户必须在 pod(TBC)内运行构建
- 双向同步 - 远程文件会复制到本地目录
- 每次更新远程文件系统时都会重启容器
- 无安全功能 - 仅限开发
- 使用 Syncthing,一个用于点对点同步的 Go 语言库
- 需要一个在集群中运行的特权 DaemonSet
- Node 必须使用带有 overlayfs2 的 Docker - 在写作本文时,尚不支持其他 CRI 实现
更多信息:
- Getting Started Guide
- How It Works
- Katacoda scenario to try out ksync in your browser
- Syncthing Specification
实践演练
我们接下来用于练习使用工具的应用是一个简单的股市模拟器,包含两个微服务:
stock-gen(股市数据生成器)微服务是用 Go 编写的,随机生成股票数据并通过 HTTP 端点/ stockdata公开- 第二个微服务,
stock-con(股市数据消费者)是一个 Node.js 应用程序,它使用来自stock-gen的股票数据流,并通过 HTTP 端点/average/$SYMBOL提供股价移动平均线,也提供一个健康检查端点/healthz。
总体上,此应用的默认配置如下图所示:
在下文中,我们将选取以上讨论的代表性工具进行实践演练:ksync,具有本地构建的 Minikube 以及 Skaffold。对于每个工具,我们执行以下操作:
- 设置相应的工具,包括部署准备和
stock-con微服务数据的本地读取 - 执行代码更新,即更改
stock-con微服务的/healthz端点的源代码并观察网页刷新
请注意,我们一直使用 Minikube 的本地 Kubernetes 集群,但是您也可以使用 ksync 和 Skaffold 的远程集群跟随练习。
实践演练:ksync
作为准备,安装 ksync,然后执行以下步骤配置开发环境:
$ mkdir -p $(pwd)/ksync
$ kubectl create namespace dok
$ ksync init -n dok
完成基本设置后,我们可以告诉 ksync 的本地客户端监控 Kubernetes 的某个命名空间,然后我们创建一个规范来定义我们想要同步的文件夹(本地的 $(pwd)/ksync 和容器中的 / app )。请注意,目标 pod 是用 selector 参数指定:
$ ksync watch -n dok
$ ksync create -n dok --selector=app=stock-con $(pwd)/ksync /app
$ ksync get -n dok
现在我们部署股价数据生成器和股价数据消费者微服务:
$ kubectl -n=dok apply \
-f https://raw.githubusercontent.com/kubernauts/dok-example-us/master/stock-gen/app.yaml
$ kubectl -n=dok apply \
-f https://raw.githubusercontent.com/kubernauts/dok-example-us/master/stock-con/app.yaml
一旦两个部署建好并且 pod 开始运行,我们转发 stock-con 服务以供本地读取(另开一个终端窗口):
$ kubectl get -n dok po --selector=app=stock-con \
-o=custom-columns=:metadata.name --no-headers | \
xargs -IPOD kubectl -n dok port-forward POD 9898:9898
这样,通过定期查询 healthz 端点,我们就应该能够从本地机器上读取 stock-con 服务,查询命令如下(在一个单独的终端窗口):
$ watch curl localhost:9898/healthz
现在,改动 ksync/stock-con 目录中的代码,例如改动 service.js 中定义的 /healthz 端点代码,在其 JSON 形式的响应中新添一个字段并观察 pod 如何更新以及 curl localhost:9898/healthz 命令的输出发生何种变化。总的来说,您最后应该看到类似的内容:
实践演练:带本地构建的 Minikube
对于以下内容,您需要启动并运行 Minikube,我们将利用 Minikube 自带的 Docker daemon 在本地构建镜像。作为准备,请执行以下操作
$ git clone https://github.com/kubernauts/dok-example-us.git && cd dok-example-us
$ eval $(minikube docker-env)
$ kubectl create namespace dok
现在我们部署股价数据生成器和股价数据消费者微服务:
$ kubectl -n=dok apply -f stock-gen/app.yaml
$ kubectl -n=dok apply -f stock-con/app.yaml
一旦两个部署建好并且 pod 开始运行,我们转发 stock-con 服务以供本地读取(另开一个终端窗口):
$ kubectl get -n dok po --selector=app=stock-con \
-o=custom-columns=:metadata.name --no-headers | \
xargs -IPOD kubectl -n dok port-forward POD 9898:9898 &
$ watch curl localhost:9898/healthz
现在,改一下 ksync/stock-con 目录中的代码,例如修改 service.js 中定义的 /healthz 端点代码,在其 JSON 形式的响应中添加一个字段。在您更新完代码后,最后一步是构建新的容器镜像并启动新部署,如下所示:
$ docker build -t stock-con:dev -f Dockerfile .
$ kubectl -n dok set image deployment/stock-con *=stock-con:dev
总的来说,您最后应该看到类似的内容:
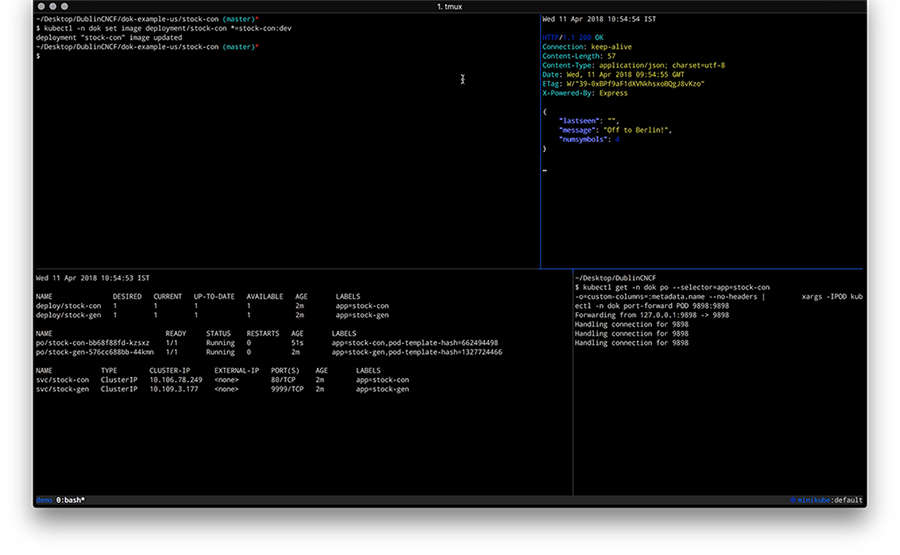
实践演练:Skaffold
要进行此演练,首先需要安装 Skaffold。完成后,您可以执行以下步骤来配置开发环境:
$ git clone https://github.com/kubernauts/dok-example-us.git && cd dok-example-us
$ kubectl create namespace dok
现在我们部署股价数据生成器(但是暂不部署股价数据消费者,此服务将使用 Skaffold 完成):
$ kubectl -n=dok apply -f stock-gen/app.yaml
请注意,最初我们在执行 skaffold dev 时发生身份验证错误,为避免此错误需要安装问题322 中所述的修复。本质上,需要将 〜/.docker/config.json 的内容改为:
{
"auths": {}
}
接下来,我们需要略微改动 stock-con/app.yaml,这样 Skaffold 才能正常使用此文件:
在 stock-con 部署和服务中添加一个 namespace 字段,其值为 dok
将容器规范的 image 字段更改为 quay.io/mhausenblas/stock-con,因为 Skaffold 可以即时管理容器镜像标签。
最终的 stock-con 的 app.yaml 文件看起来如下:
apiVersion: apps/v1beta1
kind: Deployment
metadata:
labels:
app: stock-con
name: stock-con
namespace: dok
spec:
replicas: 1
template:
metadata:
labels:
app: stock-con
spec:
containers:
- name: stock-con
image: quay.io/mhausenblas/stock-con
env:
- name: DOK_STOCKGEN_HOSTNAME
value: stock-gen
- name: DOK_STOCKGEN_PORT
value: "9999"
ports:
- containerPort: 9898
protocol: TCP
livenessProbe:
initialDelaySeconds: 2
periodSeconds: 5
httpGet:
path: /healthz
port: 9898
readinessProbe:
initialDelaySeconds: 2
periodSeconds: 5
httpGet:
path: /healthz
port: 9898
---
apiVersion: v1
kind: Service
metadata:
labels:
app: stock-con
name: stock-con
namespace: dok
spec:
type: ClusterIP
ports:
- name: http
port: 80
protocol: TCP
targetPort: 9898
selector:
app: stock-con
我们能够开始开发之前的最后一步是配置 Skaffold。因此,在 stock-con/ 目录中创建文件 skaffold.yaml,其中包含以下内容:
apiVersion: skaffold/v1alpha2
kind: Config
build:
artifacts:
- imageName: quay.io/mhausenblas/stock-con
workspace: .
docker: {}
local: {}
deploy:
kubectl:
manifests:
- app.yaml
现在我们准备好开始开发了。为此,在 stock-con/ 目录中执行以下命令:
$ skaffold dev
上面的命令将触发 stock-con 图像的构建和部署。一旦 stock-con 部署的 pod 开始运行,我们再次转发 stock-con 服务以供本地读取(在单独的终端窗口中)并检查 healthz 端点的响应:
$ kubectl get -n dok po --selector=app=stock-con \
-o=custom-columns=:metadata.name --no-headers | \
xargs -IPOD kubectl -n dok port-forward POD 9898:9898 &
$ watch curl localhost:9898/healthz
现在,如果您修改一下 stock-con 目录中的代码,例如 service.js 中定义的 /healthz 端点代码,在其 JSON 形式的响应中添加一个字段,您应该看到 Skaffold 可以检测到代码改动并创建新图像以及部署它。您的屏幕看起来应该类似这样:
至此,您应该对不同的工具如何帮您在 Kubernetes 上开发应用程序有了一定的概念,如果您有兴趣了解有关工具和/或方法的更多信息,请查看以下资源:
- Blog post by Shahidh K Muhammed on Draft vs Gitkube vs Helm vs Ksonnet vs Metaparticle vs Skaffold (03/2018)
- Blog post by Gergely Nemeth on Using Kubernetes for Local Development, with a focus on Skaffold (03/2018)
- Blog post by Richard Li on Locally developing Kubernetes services (without waiting for a deploy), with a focus on Telepresence
- Blog post by Abhishek Tiwari on Local Development Environment for Kubernetes using Minikube (09/2017)
- Blog post by Aymen El Amri on Using Kubernetes for Local Development — Minikube (08/2017)
- Blog post by Alexis Richardson on GitOps - Operations by Pull Request (08/2017)
- Slide deck GitOps: Drive operations through git, with a focus on Gitkube by Tirumarai Selvan (03/2018)
- Slide deck Developing apps on Kubernetes, a talk Michael Hausenblas gave at a CNCF Paris meetup (04/2018)
- YouTube videos:
- Raw responses to the Kubernetes Application Survey 2018 by SIG Apps
有了这些,我们这篇关于如何在 Kubernetes 上开发应用程序的博客就可以收尾了,希望您有所收获,如果您有反馈和/或想要指出您认为有用的工具,请通过 Twitter 告诉我们:Ilya 和 Michael
Kubernetes 社区 - 2017 年开源排行榜榜首
对于 Kubernetes 来说,2017 年是丰收的一年,GitHub的最新 Octoverse 报告 说明了该项目获得了多少关注。
Kubernetes 是 用于运行应用程序容器的开源平台,它提供了一个统一的界面,使开发人员和操作团队能够自动执行部署、管理和扩展几乎任何基础架构上的各种应用程序。
Kubernetes 所做的,是通过利用广泛的专业知识和行业经验来解决这些共同的挑战,可以帮助工程师专注于在堆栈的顶部构建自己的产品,而不是不必要地进行重复工作,比如现在已经存在的 “云原生” 工具包的标准部分。
但是,通过临时的集体组织来实现这些收益是它独有的挑战,这使得支持开源,社区驱动的工作变得越来越困难。
继续阅读以了解 Kubernetes 社区如何解决这些挑战,从而在 GitHub 的 2017 Octoverse 报告中位居榜首。
GitHub 上讨论最多的
2017 年讨论最多的两个仓库都是基于 Kubernetes 的:
!讨论最多
在 GitHub 的所有开源存储库中,没有比 kubernetes/kubernetes 收到更多的评论。 OpenShift, CNCF 认证的 Kubernetes 发行版 排名第二。
利用充足时间进行公开讨论来获取社区反馈和审查,有助于建立共享的基础架构并为云原生计算建立新标准。
GitHub 上审阅最多的
成功扩展开放源代码工作的通信通常会带来更好的协调和更高质量的功能交付。Kubernetes 项目的 Special Interest Group(SIG) 结构已使其成为 GitHub 审阅第二多的项目:
!审阅最多
使用 SIG 对社区参与机制进行细分和标准化有助于从资格更高的社区成员中获得更频繁的审阅。
如果得到有效管理,活跃的社区讨论不仅表明代码库存在很大的争议,也可能表明项目包含大量未满足的需求。
扩展项目处理问题和社区互动的能力有助于扩大交流。同时,大型社区具有更多不同的用例和更多的支持问题需要管理。Kubernetes SIG 组织结构 帮助应对大规模复杂通信的挑战。
SIG 会议为不同学科的用户、维护者和专家提供了重点合作的机会,以共同协作来支持社区的工作。这些在组织上的投资有助于创建一个环境,在这样的环境中,可以更轻松地将架构讨论和规划的优先级排到提交速度前面,并使项目能够维持这种规模。
加入我们!
您可能已经在 Kubernetes 上成功使用管理和扩展的解决方案。例如,托管 Kubernetes 上游源代码的 GitHub.com 现在也可以在 Kubernetes 上运行 !
请查看 Kubernetes 贡献者指南 ,以获取有关如何开始作为贡献者的更多信息。
您也可以参加 每周 Kubernetes 的社区会议 并考虑 加入一个或两个 SIG。
“基于容器的应用程序设计原理”
如今,可以将几乎所有应用程序放入容器中并运行它。 但是,创建云原生应用程序(由 Kubernetes 等云原生平台自动有效地编排的容器化应用程序)需要付出额外的努力。 云原生应用程序会预期失败; 它们可以可靠的运行和扩展,即使基础架构出现故障。 为了提供这样的功能,像 Kubernetes 这样的云原生平台对应用程序施加了一系列约定和约束。 这些合同确保运行的应用程序符合某些约束条件,并允许平台自动执行应用程序管理。
我总结了容器化应用要成为彻底的云原生应用所要遵从的七个原则。
| ----- |
| 
| 容器设计原则 |
这七个原则涵盖了构建时间和运行时问题。
建立时间
- 单独关注点: 每个容器都解决了一个单独的关注点,并做到了。
- 自包含: 容器仅依赖于Linux内核的存在。 构建容器时会添加其他库。
- 镜像不可变性: 容器化应用程序是不可变的,并且一旦构建,就不会在不同环境之间发生变化。
运行时
- 高度可观察性: 每个容器都必须实现所有必要的API,以帮助平台以最佳方式观察和管理应用程序。
- 生命周期一致性: 容器必须具有读取来自平台的事件并通过对这些事件做出反应来进行一致性的方式。
- 进程可丢弃: 容器化的应用程序必须尽可能短暂,并随时可以被另一个容器实例替换。
- 运行时可约束 每个容器必须声明其资源需求,并根据所标明的需求限制其资源使用。 构建时间原则可确保容器具有正确的颗粒度,一致性和适当的结构。 运行时原则规定了必须执行哪些功能才能使容器化的应用程序具有云原生功能。 遵循这些原则有助于确保您的应用程序适合Kubernetes中的自动化。
白皮书可以免费下载:
要了解有关为Kubernetes设计云原生应用程序的更多信息,请翻阅我的Kubernetes 模式这本书。
— Bilgin Ibryam,首席架构师,Red Hat
推特:
博客: http://www.ofbizian.com
领英:
Bilgin Ibryam(@bibryam)是 Red Hat 的首席架构师,ASF 的开源提交者,博客,作者和发言人。 他是骆驼设计模式和 Kubernetes 模式书籍的作者。 在日常工作中,Bilgin 乐于指导,培训和领导团队,以使他们在分布式系统,微服务,容器和云原生应用程序方面取得成功。
Kubernetes 1.9 对 Windows Server 容器提供 Beta 版本支持
随着 Kubernetes v1.9 的发布,我们确保所有人在任何地方都能正常运行 Kubernetes 的使命前进了一大步。我们的 Beta 版本对 Windows Server 的支持进行了升级,并且在 Kubernetes 和 Windows 平台上都提供了持续的功能改进。为了在 Kubernetes 上运行许多特定于 Windows 的应用程序和工作负载,SIG-Windows 自2016年3月以来一直在努力,大大扩展了 Kubernetes 的实现场景和企业适用范围。
各种规模的企业都在 .NET 和基于 Windows 的应用程序上进行了大量投资。如今许多企业产品组合都包含 .NET 和 Windows,Gartner 声称 80% 的企业应用都在 Windows 上运行。根据 StackOverflow Insights,40% 的专业开发人员使用 .NET 编程语言(包括 .NET Core)。
但为什么这些信息都很重要?这意味着企业既有传统的,也有新生的云(microservice)应用程序,利用了大量的编程框架。业界正在大力推动将现有/遗留应用程序现代化到容器中,使用类似于“提升和转移”的方法。同时,也能灵活地向其他 Windows 或 Linux 容器引入新功能。容器正在成为打包、部署和管理现有程序和微服务应用程序的业界标准。IT 组织正在寻找一种更简单且一致的方法来跨 Linux 和 Windows 环境进行协调和管理容器。Kubernetes v1.9 现在对 Windows Server 容器提供了 Beta 版本支持,使之成为策划任何类型容器的明确选择。
特点
Kubernetes 中对 Windows Server 容器的 Alpha 支持是非常有用的,尤其是对于概念项目和可视化 Kubernetes 中 Windows 支持的路线图。然而,Alpha 版本有明显的缺点,并且缺少许多特性,特别是在网络方面。SIG Windows、Microsoft、Cloudbase Solutions、Apprenda 和其他社区成员联合创建了一个全面的 Beta 版本,使 Kubernetes 用户能够开始评估和使用 Windows。
Kubernetes 对 Windows 服务器容器的一些关键功能改进包括:
- 改进了对 Pod 的支持!Pod 中多个 Windows Server 容器现在可以使用 Windows Server 中的网络隔离专区共享网络命名空间。此功能中 Pod 的概念相当于基于 Linux 的容器
- 可通过每个 Pod 使用单个网络端点来降低网络复杂性
- 可以使用 Virtual Filtering Platform(VFP)的 Hyper-v Switch Extension(类似于 Linux iptables)达到基于内核的负载平衡
- 具备 Container Runtime Interface(CRI)的 Pod 和 Node 级别的统计信息。可以使用从 Pod 和节点收集的性能指标配置 Windows Server 容器的 Horizontal Pod Autoscaling
- 支持 kubeadm 命令将 Windows Server 的 Node 添加到 Kubernetes 环境。Kubeadm 简化了 Kubernetes 集群的配置,通过对 Windows Server 的支持,您可以在您的基础配置中使用单一的工具部署 Kubernetes
- 支持 ConfigMaps, Secrets, 和 Volumes。这些是非常关键的特性,您可以将容器的配置从实施体系中分离出来,并且在大部分情况下是安全的
然而,kubernetes 1.9 windows 支持的最大亮点是网络增强。随着 Windows 服务器 1709 的发布,微软在操作系统和 Windows Host Networking Service(HNS)中启用了关键的网络功能,这为创造大量与 Kubernetes 中的 Windows 服务器容器一起工作的 CNI 插件铺平了道路。Kubernetes 1.9 支持的第三层路由和网络覆盖插件如下所示:
- 上游 L3 路由 - 上游 ToR 中配置的 IP 路由
- Host-Gateway - 在每个主机上配置的 IP 路由
- 具有 Overlay 的 Open vSwitch(OVS)和 Open Virtual Network(OVN) - 支持 STT 和 Geneve 的 tunneling 类型 您可以阅读更多有关 配置、设置和运行时功能 的信息,以便在 Kubernetes 中为您的网络堆栈做出明智的选择。
如果您需要继续在 Linux 中运行 Kubernetes Control Plane 和 Master Components,现在也可以将 Windows Server 作为 Kubernetes 中的一个节点引入。对一个社区来说,这是一个巨大的里程碑和成就。现在,我们将会在 Kubernetes 中看到 .NET,.NET Core,ASP.NET,IIS,Windows 服务,Windows 可执行文件以及更多基于 Windows 的应用程序。
接下来还会有什么
这个 Beta 版本进行了大量工作,但是社区意识到在将 Windows 支持作为生产工作负载发布为 GA(General Availability)之前,我们需要更多领域的投资。2018年前两个季度的重点关注领域包括:
- 继续在网络领域取得更多进展。其他 CNI 插件正在开发中,并且即将完成
- Overlay - win-Overlay(vxlan 或 IP-in-IP 使用 Flannel 封装)
- Win-l2bridge(host-gateway)
- 使用云网络的 OVN - 不再依赖 Overlay
- 在 ovn-Kubernetes 中支持 Kubernetes 网络策略
- 支持 Hyper-V Isolation
- 支持有状态应用程序的 StatefulSet 功能
- 生成适用于任何基础架构以及跨多公共云提供商(例如 Microsoft Azure,Google Cloud 和 Amazon AWS)的安装工具和文档
- SIG-Windows 的 Continuous Integration/Continuous Delivery(CI/CD)基础结构
- 可伸缩性和性能测试 尽管我们尚未承诺正式版的具体时间线,但估计 SIG-Windows 将于2018年上半年正式发布。
加入我们
随着我们在 Kubernetes 的普遍可用性方向不断取得进展,我们欢迎您参与进来,贡献代码、提供反馈,将 Windows 服务器容器部署到 Kubernetes 集群,或者干脆加入我们的社区。
- 如果你想要开始在 Kubernetes 中部署 Windows Server 容器,请阅读我们的开始导览 /docs/getting-started-guides/windows/
- 我们每隔一个星期二在美国东部标准时间(EST)的12:30在 https://zoom.us/my/sigwindows 开会。所有会议内容都记录在 Youtube 并附上了参考材料 https://www.youtube.com/playlist?list=PL69nYSiGNLP2OH9InCcNkWNu2bl-gmIU4
- 通过 Slack 联系我们 https://kubernetes.slack.com/messages/sig-windows
- 在 Github 上找到我们 https://github.com/kubernetes/community/tree/master/sig-windows
谢谢大家,
Michael Michael (@michmike77)
SIG-Windows 领导人
Apprenda 产品管理高级总监
Kubernetes 中自动缩放
Kubernetes 允许开发人员根据当前的流量和负载自动调整集群大小和 pod 副本的数量。这些调整减少了未使用节点的数量,节省了资金和资源。 在这次演讲中,谷歌的 Marcin Wielgus 将带领您了解 Kubernetes 中 pod 和 node 自动调焦的当前状态:它是如何工作的,以及如何使用它,包括在生产应用程序中部署的最佳实践。
喜欢这个演讲吗? 12 月 6 日至 8 日,在 Austin 参加 KubeCon 关于扩展和自动化您的 Kubernetes 集群的更令人兴奋的会议。现在注册。
一定要查看由 Ron Lipke, Gannet/USA Today Network, 平台即服务高级开发人员,在公共云中自动化和测试产品就绪的 Kubernetes 集群。
Kubernetes 1.8 的五天
Kubernetes 1.8 已经推出,数百名贡献者在这个最新版本中推出了成千上万的提交。
社区已经有超过 66,000 个提交在主仓库,并在主仓库之外继续快速增长,这标志着该项目日益成熟和稳定。仅 v1.7.0 到 v1.8.0,社区就记录了所有仓库的超过 120,000 次提交和 17839 次提交。
在拥有 1400 多名贡献者,并且不断发展壮大的社区的帮助下,我们合并了 3000 多个 PR,并发布了 5000 多个提交,最后的 Kubernetes 1.8 在安全和工作负载方面添加了很多的更新。 这一切都表明稳定性的提高,这是我们整个项目关注成熟流程、形式化架构和加强 Kubernetes 的治理模型的结果。
虽然有很多改进,但我们在下面列出的这一系列深度文章中突出了一些关键特性。跟随并了解存储,安全等方面的新功能和改进功能。
第一天: Kubernetes 1.8 的五天 第二天: kubeadm v1.8 为 Kubernetes 集群引入了简单的升级 第三天: Kubernetes v1.8 回顾:提升一个 Kubernetes 需要一个 Village 第四天: 使用 RBAC,一般在 Kubernetes v1.8 中提供 第五天: 在 Kubernetes 执行网络策略
链接
- 在 Stack Overflow 上发布问题(或回答问题)
- 加入 K8sPort 布道师的社区门户网站
- 在 Twitter @Kubernetesio 关注我们以获取最新更新
- 与 Slack 上的社区联系
- 参与 GitHub 上的 Kubernetes 项目
Kubernetes 社区指导委员会选举结果
自 2015 年 OSCON 发布 Kubernetes 1.0 以来,大家一直在共同努力,在 Kubernetes 社区中共同分享领导力和责任。
在 Brandon Philips、Brendan Burns、Brian Grant、Clayton Coleman、Joe Beda、Sarah Novotny 和 Tim Hockin 组成的自举治理委员会的工作下 - 代表 5 家不同公司的长期领导者,他们对 Kubernetes 生态系统进行了大量的人才投资和努力 - 编写了初始的指导委员会章程,并发起了一次社区选举,以选举 Kubernetes 指导委员会成员。
引用章程 -
_指导委员会的最初职责是实例化 Kubernetes 治理的正式过程。除定义初始治理过程外,指导委员会还坚信提供一种方法来迭代指导委员会定义的方法很重要。我们不相信我们会在第一次或以后把这些做好,也不会一口气完成治理开发工作。指导委员会的作用是成为一个积极响应的机构,可以根据需要进行重构和改造,以适应不断变化的项目和社区。
这是将我们隐式治理结构明确化的最大一步。Kubernetes 的愿景一直是成为一个包容而广泛的社区,用我们的软件带给用户容器的便利性。指导委员会将是一个强有力的引领声音,指导该项目取得成功。
Kubernetes 社区很高兴地宣布 2017 年指导委员会选举的结果。 请祝贺 Aaron Crickenberger、Derek Carr、Michelle Noorali、Phillip Wittrock、Quinton Hoole 和 Timothy St. Clair,他们将成为新成立的 Kubernetes 指导委员会的自举治理委员会成员。Derek、Michelle 和 Phillip 将任职 2 年。Aaron、Quinton、和 Timothy 将任职 1 年。
该小组将定期开会,以阐明和简化项目的结构和运行。早期的工作将包括选举 CNCF 理事会的代表,发展项目流程,完善和记录项目的愿景和范围,以及授权和委派更多主题社区团体。
请参阅完整的指导委员会待办事项列表以获取更多详细信息。
使用 Kubernetes Pet Sets 和 Datera Elastic Data Fabric 的 FlexVolume 扩展有状态的应用程序
编者注:今天的邀请帖子来自 Datera 公司的软件架构师 Shailesh Mittal 和高级产品总监 Ashok Rajagopalan,介绍在 Datera Elastic Data Fabric 上用 Kubernetes 配置状态应用程序。
简介
用户从无状态工作负载转移到运行有状态应用程序,Kubernetes 中的持久卷是基础。虽然 Kubernetes 早已支持有状态的应用程序,比如 MySQL、Kafka、Cassandra 和 Couchbase,但是 Pet Sets 的引入明显改善了情况。特别是,Pet Sets 具有持续扩展和关联的能力,在配置和启动的顺序过程中,可以自动缩放“Pets”(需要连续处理和持久放置的应用程序)。
Datera 是用于云部署的弹性块存储,可以通过 FlexVolume 框架与 Kubernetes 无缝集成。基于容器的基本原则,Datera 允许应用程序的资源配置与底层物理基础架构分离,为有状态的应用程序提供简洁的协议(也就是说,不依赖底层物理基础结构及其相关内容)、声明式格式和最后移植的能力。
Kubernetes 可以通过 yaml 配置来灵活定义底层应用程序基础架构,而 Datera 可以将该配置传递给存储基础结构以提供持久性。通过 Datera AppTemplates 声明,在 Kubernetes 环境中,有状态的应用程序可以自动扩展。
部署永久性存储
永久性存储是通过 Kubernetes 的子系统 PersistentVolume 定义的。PersistentVolumes 是卷插件,它定义的卷的生命周期和使用它的 Pod 相互独立。PersistentVolumes 由 NFS、iSCSI 或云提供商的特定存储系统实现。Datera 开发了用于 PersistentVolumes 的卷插件,可以在 Datera Data Fabric 上为 Kubernetes 的 Pod 配置 iSCSI 块存储。
Datera 卷插件从 minion nodes 上的 kubelet 调用,并通过 REST API 回传到 Datera Data Fabric。以下是带有 Datera 插件的 PersistentVolume 的部署示例:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-datera-0
spec:
capacity:
storage: 100Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
flexVolume:
driver: "datera/iscsi"
fsType: "xfs"
options:
volumeID: "kube-pv-datera-0"
size: “100"
replica: "3"
backstoreServer: "[tlx170.tlx.daterainc.com](http://tlx170.tlx.daterainc.com/):7717”
为 Pod 申请 PersistentVolume,要按照以下清单在 Datera Data Fabric 中配置 100 GB 的 PersistentVolume。
[root@tlx241 /]# kubectl get pv
NAME CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
pv-datera-0 100Gi RWO Available 8s
pv-datera-1 100Gi RWO Available 2s
pv-datera-2 100Gi RWO Available 7s
pv-datera-3 100Gi RWO Available 4s
配置
Datera PersistenceVolume 插件安装在所有 minion node 上。minion node 的声明是绑定到之前设置的永久性存储上的,当 Pod 进入具备有效声明的 minion node 上时,Datera 插件会转发请求,从而在 Datera Data Fabric 上创建卷。根据配置请求,PersistentVolume 清单中所有指定的选项都将发送到插件。
在 Datera Data Fabric 中配置的卷会作为 iSCSI 块设备呈现给 minion node,并且 kubelet 将该设备安装到容器(在 Pod 中)进行访问。

使用永久性存储
Kubernetes PersistentVolumes 与具备 PersistentVolume Claims 的 Pod 一起使用。定义声明后,会被绑定到与声明规范匹配的 PersistentVolume 上。上面提到的定义 PersistentVolume 的典型声明如下所示:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pv-claim-test-petset-0
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
定义这个声明并将其绑定到 PersistentVolume 时,资源与 Pod 规范可以一起使用:
[root@tlx241 /]# kubectl get pv
NAME CAPACITY ACCESSMODES STATUS CLAIM REASON AGE
pv-datera-0 100Gi RWO Bound default/pv-claim-test-petset-0 6m
pv-datera-1 100Gi RWO Bound default/pv-claim-test-petset-1 6m
pv-datera-2 100Gi RWO Available 7s
pv-datera-3 100Gi RWO Available 4s
[root@tlx241 /]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
pv-claim-test-petset-0 Bound pv-datera-0 0 3m
pv-claim-test-petset-1 Bound pv-datera-1 0 3m
Pod 可以使用 PersistentVolume 声明,如下所示:
apiVersion: v1
kind: Pod
metadata:
name: kube-pv-demo
spec:
containers:
- name: data-pv-demo
image: nginx
volumeMounts:
- name: test-kube-pv1
mountPath: /data
ports:
- containerPort: 80
volumes:
- name: test-kube-pv1
persistentVolumeClaim:
claimName: pv-claim-test-petset-0
程序的结果是 Pod 将 PersistentVolume Claim 作为卷。依次将请求发送到 Datera 卷插件,然后在 Datera Data Fabric 中配置存储。
[root@tlx241 /]# kubectl describe pods kube-pv-demo
Name: kube-pv-demo
Namespace: default
Node: tlx243/172.19.1.243
Start Time: Sun, 14 Aug 2016 19:17:31 -0700
Labels: \<none\>
Status: Running
IP: 10.40.0.3
Controllers: \<none\>
Containers:
data-pv-demo:
Container ID: [docker://ae2a50c25e03143d0dd721cafdcc6543fac85a301531110e938a8e0433f74447](about:blank)
Image: nginx
Image ID: [docker://sha256:0d409d33b27e47423b049f7f863faa08655a8c901749c2b25b93ca67d01a470d](about:blank)
Port: 80/TCP
State: Running
Started: Sun, 14 Aug 2016 19:17:34 -0700
Ready: True
Restart Count: 0
Environment Variables: \<none\>
Conditions:
Type Status
Initialized True
Ready True
PodScheduled True
Volumes:
test-kube-pv1:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: pv-claim-test-petset-0
ReadOnly: false
default-token-q3eva:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-q3eva
QoS Tier: BestEffort
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
43s 43s 1 {default-scheduler } Normal Scheduled Successfully assigned kube-pv-demo to tlx243
42s 42s 1 {kubelet tlx243} spec.containers{data-pv-demo} Normal Pulling pulling image "nginx"
40s 40s 1 {kubelet tlx243} spec.containers{data-pv-demo} Normal Pulled Successfully pulled image "nginx"
40s 40s 1 {kubelet tlx243} spec.containers{data-pv-demo} Normal Created Created container with docker id ae2a50c25e03
40s 40s 1 {kubelet tlx243} spec.containers{data-pv-demo} Normal Started Started container with docker id ae2a50c25e03
永久卷在 minion node(在本例中为 tlx243)中显示为 iSCSI 设备:
[root@tlx243 ~]# lsscsi
[0:2:0:0] disk SMC SMC2208 3.24 /dev/sda
[11:0:0:0] disk DATERA IBLOCK 4.0 /dev/sdb
[root@tlx243 datera~iscsi]# mount ``` grep sdb
/dev/sdb on /var/lib/kubelet/pods/6b99bd2a-628e-11e6-8463-0cc47ab41442/volumes/datera~iscsi/pv-datera-0 type xfs (rw,relatime,attr2,inode64,noquota)
在 Pod 中运行的容器按照清单中将设备安装在 /data 上:
[root@tlx241 /]# kubectl exec kube-pv-demo -c data-pv-demo -it bash
root@kube-pv-demo:/# mount ``` grep data
/dev/sdb on /data type xfs (rw,relatime,attr2,inode64,noquota)
使用 Pet Sets
通常,Pod 被视为无状态单元,因此,如果其中之一状态异常或被取代,Kubernetes 会将其丢弃。相反,PetSet 是一组有状态的 Pod,具有更强的身份概念。PetSet 可以将标识分配给应用程序的各个实例,这些应用程序没有与底层物理结构连接,PetSet 可以消除这种依赖性。
每个 PetSet 需要{0..n-1}个 Pet。每个 Pet 都有一个确定的名字、PetSetName-Ordinal 和唯一的身份。每个 Pet 最多有一个 Pod,每个 PetSet 最多包含一个给定身份的 Pet。要确保每个 PetSet 在任何特定时间运行时,具有唯一标识的“pet”的数量都是确定的。Pet 的身份标识包括以下几点:
- 一个稳定的主机名,可以在 DNS 中使用
- 一个序号索引
- 稳定的存储:链接到序号和主机名
使用 PersistentVolume Claim 定义 PetSet 的典型例子如下所示:
# A headless service to create DNS records
apiVersion: v1
kind: Service
metadata:
name: test-service
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1alpha1
kind: PetSet
metadata:
name: test-petset
spec:
serviceName: "test-service"
replicas: 2
template:
metadata:
labels:
app: nginx
annotations:
[pod.alpha.kubernetes.io/initialized:](http://pod.alpha.kubernetes.io/initialized:) "true"
spec:
terminationGracePeriodSeconds: 0
containers:
- name: nginx
image: [gcr.io/google\_containers/nginx-slim:0.8](http://gcr.io/google_containers/nginx-slim:0.8)
ports:
- containerPort: 80
name: web
volumeMounts:
- name: pv-claim
mountPath: /data
volumeClaimTemplates:
- metadata:
name: pv-claim
annotations:
[volume.alpha.kubernetes.io/storage-class:](http://volume.alpha.kubernetes.io/storage-class:) anything
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 100Gi
我们提供以下 PersistentVolume Claim:
[root@tlx241 /]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
pv-claim-test-petset-0 Bound pv-datera-0 0 41m
pv-claim-test-petset-1 Bound pv-datera-1 0 41m
pv-claim-test-petset-2 Bound pv-datera-2 0 5s
pv-claim-test-petset-3 Bound pv-datera-3 0 2s
配置 PetSet 时,将实例化两个 Pod:
[root@tlx241 /]# kubectl get pods
NAMESPACE NAME READY STATUS RESTARTS AGE
default test-petset-0 1/1 Running 0 7s
default test-petset-1 1/1 Running 0 3s
以下是一个 PetSet:test-petset 实例化之前的样子:
[root@tlx241 /]# kubectl describe petset test-petset
Name: test-petset
Namespace: default
Image(s): [gcr.io/google\_containers/nginx-slim:0.8](http://gcr.io/google_containers/nginx-slim:0.8)
Selector: app=nginx
Labels: app=nginx
Replicas: 2 current / 2 desired
Annotations: \<none\>
CreationTimestamp: Sun, 14 Aug 2016 19:46:30 -0700
Pods Status: 2 Running / 0 Waiting / 0 Succeeded / 0 Failed
No volumes.
No events.
一旦实例化 PetSet(例如下面的 test-petset),随着副本数(从 PetSet 的初始 Pod 数量算起)的增加,实例化的 Pod 将变得更多,并且更多的 PersistentVolume Claim 会绑定到新的 Pod 上:
[root@tlx241 /]# kubectl patch petset test-petset -p'{"spec":{"replicas":"3"}}'
"test-petset” patched
[root@tlx241 /]# kubectl describe petset test-petset
Name: test-petset
Namespace: default
Image(s): [gcr.io/google\_containers/nginx-slim:0.8](http://gcr.io/google_containers/nginx-slim:0.8)
Selector: app=nginx
Labels: app=nginx
Replicas: 3 current / 3 desired
Annotations: \<none\>
CreationTimestamp: Sun, 14 Aug 2016 19:46:30 -0700
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
No volumes.
No events.
[root@tlx241 /]# kubectl get pods
NAME READY STATUS RESTARTS AGE
test-petset-0 1/1 Running 0 29m
test-petset-1 1/1 Running 0 28m
test-petset-2 1/1 Running 0 9s
现在,应用修补程序后,PetSet 正在运行3个 Pod。
当上述 PetSet 定义修补完成,会产生另一个副本,PetSet 将在系统中引入另一个 pod。反之,这会导致在 Datera Data Fabric 上配置更多的卷。因此,在 PetSet 进行扩展时,要配置动态卷并将其附加到 Pod 上。
为了平衡持久性和一致性的概念,如果 Pod 从一个 Minion 转移到另一个,卷确实会附加(安装)到新的 minion node 上,并与旧的 Minion 分离(卸载),从而实现对数据的持久访问。
结论
本文展示了具备 Pet Sets 的 Kubernetes 协调有状态和无状态工作负载。当 Kubernetes 社区致力于扩展 FlexVolume 框架的功能时,我们很高兴这个解决方案使 Kubernetes 能够在数据中心广泛运行。
加入我们并作出贡献:Kubernetes Storage SIG.
- 下载 Kubernetes
- 参与 Kubernetes 项目 GitHub
- 发布问题(或者回答问题) Stack Overflow
- 联系社区 k8s Slack
- 在 Twitter 上关注我们 @Kubernetesio for latest updates
Kubernetes 生日快乐。哦,这是你要去的地方!
编者按,今天的嘉宾帖子来自一位独立的 kubernetes 撰稿人 Justin Santa Barbara,分享了他对项目从一开始到未来发展的思考。
亲爱的 K8s,
很难相信你是唯一的一个 - 成长这么快的。在你一岁生日的时候,我想我可以写一个小纸条,告诉你为什么我在你出生的时候那么兴奋,为什么我觉得很幸运能成为抚养你长大的一员,为什么我渴望看到你继续成长!
--Justin
你从一个优秀的基础 - 良好的声明性功能开始,它是围绕一个具有良好定义的模式和机制的坚实的 API 构建的,这样我们就可以向前发展了。果然,在你的第一年里,你增长得如此之快:autoscaling、HTTP load-balancing support (Ingress)、support for persistent workloads including clustered databases (PetSets)。你已经和更多的云交了朋友(欢迎 azure 和 openstack 加入家庭),甚至开始跨越区域和集群(Federation)。这些只是一些最明显的变化 - 在你的大脑里发生了太多的变化!
我觉得你一直保持开放的态度真是太好了 - 你好像把所有的东西都写在 github 上 - 不管是好是坏。我想我们在这方面都学到了很多,比如让工程师做缩放声明的风险,然后在没有完全相同的精确性和严谨性框架的情况下,将这些声明与索赔进行权衡。但我很自豪你选择了不降低你的标准,而是上升到挑战,只是跑得更快 - 这可能不是最现实的办法,但这是唯一的方式能移动山!
然而,不知何故,你已经设法避免了许多其他开源软件陷入的共同死胡同,特别是当那些项目越来越大,开发人员最终要做的比直接使用它更多的时候。你是怎么做到的?有一个很可能是虚构的故事,讲的是 IBM 的一名员工犯了一个巨大的错误,被传唤去见大老板,希望被解雇,却被告知“我们刚刚花了几百万美元培训你。我们为什么要解雇你?“。尽管谷歌对你进行了大量的投资(包括 redhat 和其他公司),但我有时想知道,我们正在避免的错误是否更有价值。有一个非常开放的开发过程,但也有一个“oracle”,它有时会通过告诉我们两年后如果我们做一个特定的设计决策会发生什么来纠正错误。这是你应该听的父母!
所以,尽管你只有一岁,你真的有一个旧灵魂。我只是很多人抚养你中的一员,但对我来说,能够与那些建立了这些令人难以置信的系统并拥有所有这些领域知识的人一起工作是一次极好的学习经历。然而,因为我们是白手起家(而不是采用现有的 Borg 代码),我们处于同一水平,仍然可以就如何培养你进行真正的讨论。好吧,至少和我们的水平一样接近,但值得称赞的是,他们都太好了,从来没提过!
如果我选择两个聪明人做出的明智决定:
- 标签和选择器给我们声明性的“pointers”,所以我们可以说“为什么”我们想要东西,而不是直接列出东西。这是如何扩展到[伟大高度]的秘密(https://kubernetes.io/blog/2016/07/thousand-instances-of-cassandra-using-kubernetes-pet-set);不是命名每一步,而是说“像第一步一样多走一千步”。
- 控制器是状态同步器:我们指定目标,您的控制器将不遗余力地工作,使系统达到该状态。它们工作在强类型 API 基础上,并且贯穿整个代码,因此 Kubernetes 比一个大的程序多一百个小程序。仅仅从技术上扩展到数千个节点是不够的;这个项目还必须扩展到数千个开发人员和特性;控制器帮助我们达到目的。
等等我们就走!我们将取代那些控制器,建立更多,API 基金会让我们构建任何我们可以用这种方式表达的东西 - 大多数东西只是标签或注释远离!但你的思想不会由语言来定义:有了第三方资源,你可以表达任何你选择的东西。现在我们可以不用在 Kubernetes 建造Kubernetes 了,创造出与其他任何东西一样感觉是 Kubernetes 的一部分的东西。最近添加的许多功能,如ingress、DNS integration、autoscaling and network policies ,都已经完成或可以通过这种方式完成。最终,在这些事情发生之前很难想象你会是怎样的一个人,但是明天的标准功能可以从今天开始,没有任何障碍或看门人,甚至对一个听众来说也是这样。
所以我期待着看到越来越多的增长发生在离 Kubernetes 核心越来越远的地方。我们必须通过这些阶段来工作;从需要在 kubernetes 内核中发生的事情开始——比如用部署替换复制控制器。现在我们开始构建不需要核心更改的东西。但我们仍然在讨论基础设施和应用程序。接下来真正有趣的是:当我们开始构建依赖于 kubernetes api 的应用程序时。我们一直有使用 kubernetes api 进行自组装的 cassandra 示例,但我们还没有真正开始更广泛地探讨这个问题。正如 S3 APIs 改变了我们构建记忆事物的方式一样,我认为 k8s APIs 也将改变我们构建思考事物的方式。
所以我很期待你的二岁生日:我可以试着预测你那时的样子,但我知道你会超越我所能想象的最大胆的东西。哦,这是你要去的地方!
-- Justin Santa Barbara, 独立的 Kubernetes 贡献者
Dashboard - Kubernetes 的全功能 Web 界面
编者按:这篇文章是一系列深入的文章 中关于Kubernetes 1.3的新内容的一部分 Kubernetes Dashboard是一个旨在为 Kubernetes 世界带来通用监控和操作 Web 界面的项目。三个月前,我们发布第一个面向生产的版本,从那时起 dashboard 已经做了大量的改进。在一个 UI 中,您可以在不离开浏览器的情况下,与 Kubernetes 集群执行大多数可能的交互。这篇博客文章分解了最新版本中引入的新功能,并概述了未来的路线图。
全功能的 Dashboard
由于社区和项目成员的大量贡献,我们能够为Kubernetes 1.3发行版提供许多新功能。我们一直在认真听取用户的反馈(参见摘要信息图表),并解决了最高优先级的请求和难点。 -->
Dashboard UI 现在处理所有工作负载资源。这意味着无论您运行什么工作负载类型,它都在 web 界面中可见,并且您可以对其进行操作更改。例如,可以使用Pet Sets修改有状态的 mysql 安装,使用部署对 web 服务器进行滚动更新,或使用守护程序安装群集监视。

除了查看资源外,还可以创建、编辑、更新和删除资源。这个特性支持许多用例。例如,您可以杀死一个失败的 pod,对部署进行滚动更新,或者只组织资源。您还可以导出和导入云应用程序的 yaml 配置文件,并将它们存储在版本控制系统中。

这个版本包括一个用于管理和操作用例的集群节点的 beta 视图。UI 列出集群中的所有节点,以便进行总体分析和快速筛选有问题的节点。details 视图显示有关该节点的所有信息以及指向在其上运行的 pod 的链接。

我们随发行版提供的还有许多小范围的新功能,即:支持命名空间资源、国际化、性能改进和许多错误修复(请参阅发行说明中的更多内容)。所有这些改进都会带来更好、更简单的产品用户体验。
Future Work
该团队对跨越多个用例的未来有着雄心勃勃的计划。我们还对所有功能请求开放,您可以在我们的问题跟踪程序上发布这些请求。
以下是我们接下来几个月的重点领域:
- Handle more Kubernetes resources - 显示群集用户可能与之交互的所有资源。一旦完成,dashboard 就可以完全替代cli。
- Monitoring and troubleshooting - 将资源使用统计信息/图表添加到 Dashboard 中显示的对象。这个重点领域将允许对云应用程序进行可操作的调试和故障排除。
- Security, auth and logging in - 使仪表板可从群集外部的网络访问,并使用自定义身份验证系统。
联系我们
我们很乐意与您交谈并听取您的反馈!
- 请在[SIG-UI邮件列表](https://groups.google.com/forum/向我们发送电子邮件!论坛/kubernetes sig ui)
- 在 kubernetes slack 上与我们聊天。#SIG-UI channel
- 参加我们的会议:东部时间下午4点。请参阅SIG-UI日历了解详细信息。
Citrix + Kubernetes = 全垒打
编者按:今天的客座文章来自 Citrix Systems 的产品管理总监 Mikko Disini,他分享了他们在 Kubernetes 集成上的合作经验。 _
技术合作就像体育运动。如果你能像一个团队一样合作,你就能在最后关头取得胜利。这就是我们对谷歌云平台团队的经验。
最近,我们与 Google 云平台(GCP)联系,代表 Citrix 客户以及更广泛的企业市场,希望就工作负载的迁移进行协作。此迁移需要将 [NetScaler Docker 负载均衡器]https://www.citrix.com/blogs/2016/06/20/the-best-docker-load-balancer-at-dockercon-in-seattle-this-week/) CPX 包含到 Kubernetes 节点中,并解决将流量引入 CPX 代理的任何问题。
为什么是 NetScaler 和 Kubernetes
- Citrix 的客户希望他们开始使用 Kubernetes 部署他们的容器和微服务体系结构时,能够像当初迁移到云计算时一样,享有 NetScaler 所提供的第 4 层到第 7 层能力
- Kubernetes 提供了一套经过验证的基础设施,可用来运行容器和虚拟机,并自动交付工作负载;
- NetScaler CPX 提供第 4 层到第 7 层的服务,并为日志和分析平台 NetScaler 管理和分析系统 提供高效的度量数据。
我希望我们所有与技术合作伙伴一起工作的经验都能像与 GCP 一起工作一样好。我们有一个列表,包含支持我们的用例所需要解决的问题。我们能够快速协作形成解决方案。为了解决这些问题,GCP 团队提供了深入的技术支持,与 Citrix 合作,从而使得 NetScaler CPX 能够在每台主机上作为客户端代理启动运行。
接下来,需要在 GCP 入口负载均衡器的数据路径中插入 NetScaler CPX,使 NetScaler CPX 能够将流量分散到前端 web 服务器。NetScaler 团队进行了修改,以便 NetScaler CPX 监听 API 服务器事件,并配置自己来创建 VIP、IP 表规则和服务器规则,以便跨前端应用程序接收流量和负载均衡。谷歌云平台团队提供反馈和帮助,验证为克服技术障碍所做的修改。完成了!
NetScaler CPX 用例在 Kubernetes 1.3 中提供支持。Citrix 的客户和更广泛的企业市场将有机会基于 Kubernetes 享用 NetScaler 服务,从而降低将工作负载转移到云平台的阻力。
您可以在此处了解有关 NetScaler CPX 的更多信息。
_ -- Mikko Disini,Citrix Systems NetScaler 产品管理总监
容器中运行有状态的应用!? Kubernetes 1.3 说 “是!”
编者注: 今天的来宾帖子来自 Diamanti 产品副总裁 Mark Balch,他将分享有关他们对 Kubernetes 所做的贡献的更多信息。
祝贺 Kubernetes 社区发布了另一个有价值的版本。 专注于有状态应用程序和联邦集群是我对 1.3 如此兴奋的两个原因。 Kubernetes 对有状态应用程序(例如 Cassandra、Kafka 和 MongoDB)的支持至关重要。 重要服务依赖于数据库、键值存储、消息队列等。 此外,随着应用程序的发展为全球数百万用户提供服务,仅依靠一个数据中心或容器集群将无法正常工作。 联邦集群允许用户跨多个集群和数据中心部署应用程序,以实现规模和弹性。
您可能之前听过我说过,容器是下一个出色的应用程序平台。 Diamanti 正在加速在生产中使用有状态应用程序的容器-在这方面,性能和易于部署非常重要。
应用程序不仅仅需要牛
除了诸如Web服务器之类的无状态容器(因为它们是可互换的,因此被称为“牛”)之外,用户越来越多地使用容器来部署有状态工作负载,以从“一次构建,随处运行”中受益并提高裸机效率/利用率。 这些“宠物”(之所以称为“宠物”,是因为每个宠物都需要特殊的处理)带来了新的要求,包括更长的生命周期,配置依赖项,有状态故障转移以及性能敏感性。 容器编排必须满足这些需求,才能成功部署和扩展应用程序。
输入 Pet Set,这是 Kubernetes 1.3 中的新对象,用于改进对状态应用程序的支持。 Pet Set 在每个数据库副本的启动阶段进行排序(例如),以确保有序的主/从配置。 Pet Set 还利用普遍存在的 DNS SRV 记录简化了服务发现,DNS SRV 记录是一种广为人知且长期了解的机制。
Diamanti 对 Kubernete s的 FlexVolume 贡献 通过为持久卷提供低延迟存储并保证性能来实现有状态工作负载,包括从容器到媒体的强制服务质量。
联邦主义者
为应用可用性作规划的用户必须应对故障迁移问题并在整个地理区域内扩展。 跨集群联邦服务允许容器化的应用程序轻松跨多个集群进行部署。 联邦服务解决了诸如管理多个容器集群以及协调跨联邦集群的服务部署和发现之类的挑战。
像严格的集中式模型一样,联邦身份验证提供了通用的应用程序部署界面。 但是,由于每个集群都具有自治权,因此联邦会增加了在网络中断和其他事件期间在本地管理集群的灵活性。 跨集群联邦服务还可以提供跨容器集群应用一致的服务命名和采用,简化 DNS 解析。
很容易想象在将来的版本中具有跨集群联邦服务的强大多集群用例。 一个示例是根据治理,安全性和性能要求调度容器。 Diamanti 的调度程序扩展是在考虑了这一概念的基础上开发的。 我们的第一个实现使 Kubernetes 调度程序意识到每个群集节点本地的网络和存储资源。 将来,类似的概念可以应用于跨集群联邦服务的更广泛的放置控件。
参与其中
随着对有状态应用的兴趣日益浓厚,人们已经开始进一步增强 Kubernetes 存储的工作。 存储特别兴趣小组正在讨论支持本地存储资源的提案。 Diamanti 期待将 FlexVolume 扩展到包括更丰富的 API,这些 API 可以启用本地存储和存储服务,包括数据保护,复制和缩减。 我们还正在研究有关通过 Kubernetes 跨集群联邦服务改善应用程序放置,迁移和跨容器集群故障转移的建议。
加入对话并做出贡献! 这里是一些入门的地方:
-- Diamanti 产品副总裁 Mark Balch。 Twitter @markbalch
CoreOS Fest 2016: CoreOS 和 Kubernetes 在柏林(和旧金山)社区见面会
CoreOS Fest 2016 将汇集容器和开源分布式系统社区,其中包括 Kubernetes 领域的许多思想领袖。 这是第二次年度 CoreOS 社区会议,于5月9日至10日在柏林首次举行。 CoreOS 相信 Kubernetes 是提供 GIFEE(适用于所有人的 Google 的基础架构)服务的合适的容器编排组件。
在今年的 CoreOS Fest 上,有专门针对 Kubernetes 的报道,您将听到有关 Kubernetes 性能和可伸缩性,持续交付以及 Kubernetes,rktnetes,stackanetes 等各种主题的信息。 此外,这里将有各种各样的讲座,涵盖从入门讲习班到深入探讨容器和相关软件的方方面面。
不要错过柏林会议上的精彩演讲:
- 深入了解 Kubernetes 的性能和可扩展性 由 Google 的高级软件工程师 Filip Grzadkowski 演讲
- 在 Kubernetes 云中启动一个复杂的应用程序 由 immmr Gmbh(德国电信研发部门开发的服务)的运营和基础架构负责人Thomas Fricke 和 Jannis Rake-Revelant 演讲
- 我有 Kubernetes,现在呢? 由 Engine Yard 的 CTO 和 Deis 的创建者 Gabriel Monroy 演讲
- 当 rkt 与 Kubernetes 碰面时 :一个故障排除的故事 由 Sysdig 的软件工程师 Luca Marturana 演讲
- 使用 Kubernetes 部署电信应用程序 由华为技术有限公司高级工程师 Victor Hu 演讲
- 连续交付,Kubernetes 和您 由 Wercker首席执行官兼创始人 Micha Hernandez van Leuffen 演讲
- #GIFEE,更多容器,更多问题 由 CoreOS 构造负责人 Ed Rooth 演讲
- 带有 dex 的 Kubernetes 访问控制 由 CoreOS 的软件工程师 Eric Chiang 演讲
如果您无法到达柏林,Kubernetes 还是** CoreOS Fest 旧金山 ** 卫星事件 的焦点,这是一个专门针对 CoreOS 和 Kubernetes 的一日活动。 实际上, Google 的高级工程师, Kubernetes 的创建者之一 Tim Hockin 将以专门介绍 Kubernetes 更新的主题演讲拉开序幕。
专门针对 Kubernetes 的旧金山会议包括:
- Tim Hockin的主题演讲,Google 高级工程师
- 当 rkt 与 Kubernetes 相遇时:Sysdig 首席执行官 Loris Degioanni 的故障排除故事
- rktnetes: CoreOS的软件工程师Derek Gonyeo提供了容器运行时和 Kubernetes 的新功能
- 神奇的安全性蔓延:CoreOS 和 Kubernetes 上的安全,弹性微服务,浮力技术总监 Oliver Gould
** SF 的 Kubernetes 研讨会**:Kubernetes 入门, Google 开发人员计划工程师 Carter Morgan 和 Bill Prin 于5月10日(星期二)上午9:00至1:00 pm在 Google 旧金山办公室(Spear 街345号第7层)举办会议,之后将提供午餐。 席位有限,请 此处免费提供 RSVP 。
获取门票 :
- CoreOS Fest - 柏林, 位于 柏林会议中心 (酒店选项)
- 卫星事件在 旧金山, 在 111 米娜美术馆
要了解更多信息,请访问: coreos.com/fest/ 和 Twitter @CoreOSFest #CoreOSFest
-- Sarah Novotny, Kubernetes 社区管理者
SIG-ClusterOps: 提升 Kubernetes 集群的可操作性和互操作性
编者注: 本周我们将推出 Kubernetes 特殊兴趣小组;今天的帖子由 SIG-ClusterOps 团队负责,其任务是促进 Kubernetes 集群的可操作性和互操作性 -- 倾听,帮助和升级。
我们认为 Kubernetes 是大规模运行应用程序的绝佳方法! 不幸的是,存在一个引导问题:我们需要良好的方法来围绕 Kubernetes 构建安全可靠的扩展环境。 虽然平台管理的某些部分利用了平台(很酷!),这有一些基本的操作主题需要解决,还有一些问题(例如升级和一致性)需要回答。
输入 Cluster Ops SIG – 在平台下工作以保持其运行的社区成员。
我们对 Cluster Ops 的目标是首先成为一个人对人的社区,其次才是意见、文档、测试和脚本的来源。 这意味着我们将花费大量时间和精力来简单地比较有关工作内容的注释并讨论实际操作。 这些互动为我们提供了形成意见的数据。 这也意味着我们可以利用实际经验来为项目提供信息。
我们旨在成为对该项目进行运营审查和反馈的论坛。 为了使 Kubernetes 取得成功,运营商需要通过每周参与并收集调查数据在项目中拥有重要的声音。 我们并不是想对操作发表意见,但我们确实想创建一个协调的资源来收集项目的运营反馈。 作为一个公认的团体,操作员更容易获得影响力。
现实世界中的可交付成果如何?
我们也有切实成果的计划。 我们已经在努力实现具体的交付成果,例如参考架构,工具目录,社区部署说明和一致性测试。 Cluster Ops 希望成为运营资源的交换所。 我们将根据实际经验和经过战斗测试的部署来进行此操作。
联系我们。
集群运营可能会很辛苦–别一个人做。 我们在这里倾听,在我们可以帮助的时候提供帮助,而在我们不能帮助的时候向上一级反映。 在以下位置加入对话:
- 在 Cluster Ops Slack 频道 与我们聊天
- 通过 Cluster Ops SIG 电子邮件列表 给我们发送电子邮件
SIG Cluster Ops 每周四在太平洋标准时间下午 13:00 开会,您可以通过 视频环聊 加入我们并查看最新的 会议记录 了解所涉及的议程和主题。
-- RackN 首席执行官 Rob Hirschfeld
“SIG-Networking:1.3 版本引入 Kubernetes 网络策略 API”
编者注:本周我们将推出 Kubernetes 特殊兴趣小组、 Network-SIG 小组今天的帖子描述了 1.3 版中的网络策略 API-安全,隔离和多租户策略。
自去年下半年以来,Kubernetes SIG-Networking 一直在定期开会,致力于将网络策略引入 Kubernetes,我们开始看到这个努力的结果。
许多用户面临的一个问题是,Kubernetes 的开放访问网络策略不适用于需要对访问容器或服务的流量进行更精确控制的应用程序。 如今,这种应用可能是多层应用,其中仅允许来自某个相邻层的流量。 但是,随着新的云原生应用不断通过组合微服务构建出来,对服务间流动的数据进行控制的能力变得更加重要。
在大多数 IaaS 环境(公共和私有)中,通过允许 VM 加入“安全组(Security Group)”来提供这种控制, 其中“安全组”成员的流量由网络策略或访问控制列表( ACL )定义,并由网络数据包过滤器实施。
SIG-Networking 开始这项工作时的第一步是辩识需要特定网络隔离以增强安全性的 特定用例场景。 确保所定义的 API 适用于这些简单和常见的用例非常重要,因为它们为在 Kubernetes 内 实现更复杂的网络策略以支持多租户奠定了基础。
基于这些场景,团队考虑了几种可能的方法,并定义了一个最小的 策略规范 。 基本思想是,如果按命名空间启用了隔离,则特定流量类型被允许时会选择特定的 Pod。
快速支持此实验性 API 的最简单方法是对 API 服务器的 ThirdPartyResource 扩展,今天在 Kubernetes 1.2 中就可以实现。
如果您不熟悉它的工作方式,则可以通过定义 ThirdPartyResources 来扩展 Kubernetes API ,ThirdPartyResources 在指定的 URL 上创建一个新的 API 端点。
third-party-res-def.yaml
kind: ThirdPartyResource
apiVersion: extensions/v1beta1
metadata:
name: network-policy.net.alpha.kubernetes.io
description: "Network policy specification"
versions:
- name: v1alpha1
$kubectl create -f third-party-res-def.yaml
这将创建一个 API 端点(每个名称空间一个):
/net.alpha.kubernetes.io/v1alpha1/namespace/default/networkpolicys/
第三方网络控制器现在可以在这些端点上进行侦听,并在创建,修改或删除资源时根据需要做出反应。 注意:在即将发布的 Kubernetes 1.3 版本中-当网络政策 API 以 beta 形式发布时-无需创建如上所示的 ThirdPartyResource API 端点。
默认情况下,网络隔离处于关闭状态,以便所有Pod都能正常通信。 但是,重要的是要知道,启用网络隔离后,所有命名空间中所有容器的所有流量都会被阻止,这意味着启用隔离将改变容器的行为
通过在名称空间上定义 network-isolation 注解来启用网络隔离,如下所示:
net.alpha.kubernetes.io/network-isolation: [on | off]
启用网络隔离后,必须应用显式网络策略才能启用 Pod 通信。
可以将策略规范应用于命名空间,以定义策略的详细信息,如下所示:
POST /apis/net.alpha.kubernetes.io/v1alpha1/namespaces/tenant-a/networkpolicys/
{
"kind": "NetworkPolicy",
"metadata": {
"name": "pol1"
},
"spec": {
"allowIncoming": {
"from": [
{ "pods": { "segment": "frontend" } }
],
"toPorts": [
{ "port": 80, "protocol": "TCP" }
]
},
"podSelector": { "segment": "backend" }
}
}
在此示例中,‘ tenant-a ’名称空间将按照指示应用策略‘ pol1 ’。 具体而言,带有segment标签 ‘ 后端 ’ 的容器将允许接收来自带有“segment**标签‘ frontend ’的容器的端口80上的TCP流量。
现今,Romana, OpenShift, OpenContrail 和 Calico 支持应用于名称空间和容器的网络策略。 思科和 VMware 也在努力实施。 Romana 和 Calico 最近都在 KubeCon 上使用 Kubernetes 1.2 演示了这些功能。 你可以在此处观看他们的演讲:Romana (slides), Calico (slides)。
它是如何工作的?
每个解决方案都有其自己的特定实现细节。 今天,他们依靠某种形式的主机执行机制,但是将来的实现也可以构建为在虚拟机管理程序上,甚至直接由网络本身应用策略构建。
外部策略控制软件(具体情况因实现而异)将监视新 API 终结点是否正在创建容器和/或正在应用新策略。 当发生需要配置策略的事件时,侦听器将识别出更改,并且控制器将通过配置接口并应用策略来做出响应。 下图显示了 API 侦听器和策略控制器,它通过主机代理在本地应用网络策略来响应更新。 主机上的网络接口由主机上的 CNI 插件配置(未显示)。

如果您由于网络隔离和/或安全性问题而一直拒绝使用 Kubernetes 开发应用程序,那么这些新的网络策略将为您提供所需的控制功能大有帮助。 无需等到 Kubernetes 1.3,因为网络策略现在作为实验性 API 可用,已启用 ThirdPartyResource。
如果您对 Kubernetes 和网络感兴趣,有几种参与方式-请通过以下方式加入我们:
- 我们的 Kubernetes Networking Special Interest Group 电子邮件列表
网络“特殊兴趣小组”,每两周一次,在太平洋时间下午 3 点(15:00)在SIG-Networking 环聊开会。
--Pani Networks 联合创始人 Chris Marino
在 Rancher 中添加对 Kuernetes 的支持
今天的来宾帖子由 Rancher Labs(用于管理容器的开源软件平台)的首席架构师 Darren Shepherd 撰写。
在过去的一年中,我们看到希望在其软件开发和IT组织中利用容器的公司数量激增。 为了实现这一目标,组织一直在研究如何构建集中式的容器管理功能,该功能将使用户可以轻松访问容器,同时集中管理IT组织的可见性和控制力。 2014年,我们启动了开源 Rancher 项目,通过构建容器管理平台来解决此问题。
最近,我们发布了 Rancher v1.0。 在此最新版本中,用于管理容器的开源软件平台 Rancher 现在在创建环境时支持 Kubernetes 作为容器编排框架。 现在,使用 Rancher 启动 Kubernetes 环境是完全自动化的,只需 5 至 10 分钟即可交付运行正常的集群。
我们创建 Rancher 的目的是为组织提供完整的容器管理平台。 作为其中的一部分,我们始终支持使用 Docker API 和 Docker Compose 在本地部署 Docker 环境。 自成立以来, Kubernetes 的运营成熟度给我们留下了深刻的印象,而在此版本中,我们使得其可以在同一管理平台上部署各种容器编排和调度框架。
添加 Kubernetes 使用户可以访问增长最快的平台之一,用于在生产中部署和管理容器。 我们将在 Rancher 中提供一流的 Kubernetes 支持,并将继续支持本机 Docker 部署。
将 Kubernetes 带到 Rancher

{kind=link}
{kind=link}
{kind=link}
{kind=link}
我们的平台已经可以扩展为各种不同的包装格式,因此我们对拥抱 Kubernetes 感到乐观。 没错,作为开发人员,与 Kubernetes 项目一起工作是一次很棒的经历。 该项目的设计使这一操作变得异常简单,并且我们能够利用插件和扩展来构建 Kubernetes 发行版,从而利用我们的基础架构和应用程序服务。 例如,我们能够将 Rancher 的软件定义的网络,存储管理,负载平衡,DNS 和基础结构管理功能直接插入 Kubernetes,而无需更改代码库。
更好的是,我们已经能够围绕 Kubernetes 核心功能添加许多服务。 例如,我们在 Kubernetes 上实现了常用的 应用程序目录 。 过去,我们曾使用 Docker Compose 定义应用程序模板,但是在此版本中,我们现在支持 Kubernetes 服务、副本控制器和和 Pod 来部署应用程序。 使用目录,用户可以连接到 git 仓库并自动部署和升级作为 Kubernetes 服务部署的应用。 然后,用户只需单击一下按钮,即可配置和部署复杂的多节点企业应用程序。 升级也是完全自动化的,并集中向用户推出。
回馈
与 Kubernetes 一样,Rancher 是一个开源软件项目,任何人均可免费使用,并且不受任何限制地分发给社区。 您可以在 GitHub 上找到 Rancher 的所有源代码,即将发布的版本和问题。 我们很高兴加入 Kubernetes 社区,并期待与所有其他贡献者合作。 在Rancher here 中查看有关 Kubernetes 新支持的演示。
-- Rancher Labs 首席架构师 Darren Shepherd
KubeCon EU 2016:伦敦 Kubernetes 社区
KubeCon EU 2016 是首届欧洲 Kubernetes 社区会议,紧随 2015 年 11 月召开的北美会议。KubeCon 致力于为 Kubernetes 爱好者、产品用户和周围的生态系统提供教育和社区参与。
快来加入我们在伦敦,与 Kubernetes 社区的数百人一起出去,体验各种深入的技术专家讲座和用例。
不要错过这些优质的演讲:
-
“Kubernetes 硬件黑客:通过旋钮、推杆和滑块探索 Kubernetes API” 演讲者 Ian Lewis 和 Brian Dorsey,谷歌开发布道师* http://sched.co/6Bl3
-
“rktnetes: 容器运行时和 Kubernetes 的新功能” 演讲者 Jonathan Boulle, CoreOS 的主程 -* http://sched.co/6BY7
-
“Kubernetes 文档:贡献、修复问题、收集奖金” 作者:John Mulhausen,首席技术作家,谷歌 -* http://sched.co/6BUP
-
“OpenStack 在 Kubernetes 的世界中扮演什么角色?” 作者:Thierry carez, OpenStack 基金会工程总监 -* http://sched.co/6BYC
-
“容器调度的实用指南” 作者:Mandy Waite,开发者倡导者,谷歌 -* http://sched.co/6BZa
-
“《纽约时报》编辑部正在制作 Kubernetes” Eric Lewis,《纽约时报》网站开发人员 -* http://sched.co/67f2
-
“使用 NGINX 为 Kubernetes 创建一个高级负载均衡解决方案” 作者:Andrew Hutchings, NGINX 技术产品经理 -* http://sched.co/6Bc9
在这里获取您的 KubeCon EU 门票。
会场地址:CodeNode * 英国伦敦南广场 10 号 酒店住宿:酒店 网站:[kubecon.io] (https://www.kubecon.io/) 推特:[@KubeConio] (https://twitter.com/kubeconio) 谷歌是 KubeCon EU 2016 的钻石赞助商。下个月 3 月 10 - 11 号来伦敦,参观 13 号展位,了解 Kubernetes,Google Container Engine(GKE),Google Cloud Platform 的所有信息!
_KubeCon 是由 KubeAcademy、LLC 组织的,这是一个由社区驱动的开发者团体,专注于开发人员的教育和 kubernet.com 的推广 -* Sarah Novotny, 谷歌的 Kubernetes 社区经理
Kubernetes 社区会议记录 - 20160218
2月18号 - kmachine 演示、SIG clusterops 成立、新的 k8s.io 网站预览、1.2 版本更新和 1.3 版本计划
Kubernetes 贡献社区会议大多在星期四的 10:00 召开,通过视频会议讨论项目现有情况。这里是最近一次会议的笔记。
- 记录员: Rob Hirschfeld
- 示例 (10 min): kmachine [Sebastien Goasguen]
- 开始 :01 视频介绍
- 为 Kubernetes 创建 Docker tools 的镜像 (例如 machine,compose 等等)
- kmachine ( 它是 Docker Machine的一个分叉, 因此两者有相同的 endpoints)
- 演示案例 (10 min): 开始时间 :15
- SIG 汇报启动会
- 周五进行 Cluster Ops 启动会 (doc). [Rob Hirschfeld]
- 时区讨论 [:22]
- 当前时区不适合亚洲。
- 考虑轮转时间 - 每一个月一次
- 大约 5 或者 6 PT
- Rob 建议把例会时间上调一些
- k8s.io 网站 概述 [John Mulhausen] [:27]
- 使用 github 进行文档操作。你可以通过网站进行 fork 操作并且做一个 pull request 请求
- Google 将会提供一个 "doc bounty","doc bounty" 是一个让你得到 GCP 积分来为你的文档使用的地方
- 使用 Jekyll 创建网站 (例如 the ToC)
- 100% 使用 GitHub 页面原则; 没有脚本或者插件外挂, 仅仅只有 fork/clone,edit,和 push 操作
- 希望能在 Kubecon EU 启动
- 主页唯一概述地址: http://kub.unitedcreations.xyz
- 1.2 版本观看 [T.J. Goltermann] [:38]
- 1.3 版本更新计划 [T.J. Goltermann]
- GSoC 分享会 -- 截止日期 2月19号 [Sarah Novotny]
- 3月10号 会议? [Sarah Novotny]
想要加入 Kubernetes 社区的人,考虑加入 [Slack channel] 3频道, 在 GitHub 上看看Kubernetes project, 或者加入Kubernetes-dev Google group。
如果你对此真的充满激情,你可以做完上述所有事情并加入我们的下一次社区对话 - 在2016年2月25日。
请将您自己或您想了解的主题添加到agenda,加入this group组即可获得日历邀请。
"https://youtu.be/L5BgX2VJhlY?list=PL69nYSiGNLP1pkHsbPjzAewvMgGUpkCnJ"
_-- Kubernetes 社区 _
Kubernetes 社区会议记录 - 20160204
2月4日 - rkt演示(祝贺 1.0 版本, CoreOS!), eBay 将 k8s 放在 Openstack 上并认为 Openstack 在 k8s, SIG 和片状测试激增方面取得了进展。
Kubernetes 贡献社区在每周四 10:00 PT 开会,通过视频会议讨论项目状态。以下是最近一次会议的笔记。
- 书记员:Rob Hirschfeld
- 演示视频(20分钟):CoreOS rkt + Kubernetes[Shaya Potter]
- 期待在未来几个月内看到与rkt和k8s的整合(“rkt-netes”)。 还没有集成到 v1.2版本中。
- Shaya 做了一个演示(8分钟的会议视频参考)
- rkt的CLI显示了旋转容器
- [注意:音频在点数上是乱码]
- 关于 k8s&rkt 整合的讨论
- 下周 rkt 社区同步:https://groups.google.com/forum/#!topic/rkt-dev/FlwZVIEJGbY
- Dawn Chen:
- 将 rkt 与 kubernetes 集成的其余问题:1)cadivsor 2) DNS 3)与日志记录相关的错误
- 但是需要在 e2e 测试套件上做更多的工作
- 用例(10分钟):在 OpenStack 上的 eBay k8s 和 k8s 上的 OpenStack [Ashwin Raveendran]
- eBay 目前正在 OpenStack 上运行 Kubernetes
- eBay 的目标是管理带有 k8s 的 OpenStack 控制平面。目标是实现升级。
- OpenStack Kolla 为控制平面创建容器。使用 Ansible+Docker 来管理容器。
- 致力于 k8s 控制计划管理 - Saltstack 被证明是他们想运营的规模的管理挑战。寻找 k8s 控制平面的自动化管理。
- SIG 报告
- 测试更新 [Jeff, Joe, 和 Erick]
- 努力使有助于 K8s 的工作流程更容易理解
- pull/19714有 bot 流程图来帮助用户理解
- 需要一种一致的方法来运行测试 w/hacking 配置脚本(你现在必须伪造一个 Jenkins 进程)
- 想要创建必要的基础设施,使测试设置不那么薄弱
- 想要将测试开始(单次或完整)与 Jenkins分离
- 目标是指出你有一个可以指向任何集群的脚本
- 演示包括 Google 内部视图 - 努力尝试获取外部视图。
- 希望能够收集测试运行结果
- Bob Wise 不赞同在 v1.3 版本进行测试方面的基础设施建设。
- 关于测试实践的长期讨论…
- 我们希望在多个平台上进行测试的共识。
- 为测试报告提供一个全面转储会很有帮助
- 可以使用"phone-home"收集异常
- 努力使有助于 K8s 的工作流程更容易理解
- 1.2发布观察
- CoC [Sarah]
- GSoC [Sarah]
要参与 Kubernetes 社区,请考虑加入我们的Slack 频道,查看 GitHub上的 Kubernetes 项目,或加入Kubernetes-dev Google 小组。如果你真的很兴奋,你可以完成上述所有工作并加入我们的下一次社区对话-2016年2月11日。请将您自己或您想要了解的主题添加到议程并通过加入此组来获取日历邀请。
"https://youtu.be/IScpP8Cj0hw?list=PL69nYSiGNLP1pkHsbPjzAewvMgGUpkCnJ"
容器世界现状,2016年1月
新年伊始,我们进行了一项调查,以评估容器世界的现状。 我们已经准备好发送 2 月版但在此之前,让我们从 119 条回复中看一下 1 月的数据(感谢您的参与!)。
关于这些数字的注释: 首先,您可能会注意到,这些数字加起来并不是 100%,在大多数情况下,选择不是唯一的,因此给出的百分比是选择特定选择的所有受访者的百分比。 其次,虽然我们尝试覆盖广泛的云社区,但调查最初是通过 Twitter 发送给@brendandburns,@kelseyhightower,@sarahnovotny,@juliaferraioli,@thagomizer_rb,因此受众覆盖可能并不完美。 我们正在努力扩大样本数量(我是否提到过2月份的调查?点击立即参加)。
言归正传,来谈谈数据:
首先,很多人正在使用容器!目前有 71% 的人正在使用容器,而其中有 24% 的人正在考虑尽快使用它们。 显然,这表明样本集有些偏颇。 在更广泛的社区中,容器使用的数量有所不同,但绝对低于 71%。 因此,对这些数字的其余部分要持怀疑态度。
那么人们在使用容器做什么呢? 超过 80% 的受访者使用容器进行开发,但只有 50% 的人在生产环境下使用容器。 但是他们有计划很快投入到生产环境之中,78% 的容器用户表示了意愿。
你们在哪里部署容器? 你的笔记本电脑显然是赢家,53% 的人使用笔记本电脑。 接下来是 44% 的人在自己的 VM 上运行(Vagrant?OpenStack?我们将在2月的调查中尝试深入研究),然后是 33% 的人在物理基础架构上运行,而 31% 的人在公共云 VM 上运行。
如何部署容器? 你们当中有 54% 的人使用 Kubernetes,虽然看起来有点受样本集的偏见(请参阅上面的注释),但真是令人惊讶,但有 45% 的人在使用 shell 脚本。 是因为 Kubernetes 存储库中正在运行大量(且很好)的 Bash 脚本吗? 继续下去,我们可以看到真相…… 数据显示,25% 使用 CAPS (Chef/Ansible/Puppet/Salt)系统,约 13% 使用 Docker Swarm、Mesos 或其他系统。
最后,我们让人们自由回答使用容器的挑战。 这儿有一些进行了分组和复制的最有趣的答案:
开发复杂性
- “孤立的开发环境/工作流程可能是零散的,调试容器时可以轻松访问日志等工具,但有时却不太直观,需要大量知识来掌握整个基础架构堆栈和部署/ 更新 kubernetes,到底层网络等。”
- “迁移开发者的工作流程。 那些不熟悉容器、卷等的人只是想工作。”
安全
- “网络安全”
- “Secrets”
不成熟
- “缺乏全面的非专有标准(例如,非 Docker),例如 runC / OCI”
- “仍处于早期阶段,只有很少的工具和许多缺少的功能。”
- “糟糕的 CI 支持,很多工具仍然处于非常早期的阶段。”
- "我们以前从未那样做过。"
复杂性
- “网络支持, 为 kubernetes 在裸机上为每个 Pod 提供 IP”
- “集群化还是太难了”
- “设置 Mesos 和 Kubernetes 太复杂了!!”
数据
- “卷缺乏灵活性(与 VM,物理硬件等相同的问题)”
- “坚持不懈”
- “存储”
- “永久数据”
下载完整的调查结果 链接 (CSV 文件)。
_Up-- Brendan Burns,Google 软件工程师
Kubernetes 社区会议记录 - 20160114
1 月 14 日 - RackN 演示、测试问题和 KubeCon EU CFP。
记录者:Joe Beda
-
演示:在 Metal,AWS 和其他平台上使用 Digital Rebar 自动化部署,来自 RackN 的 Rob Hirschfeld 和 Greg Althaus。
-
Greg Althaus。首席技术官。Digital Rebar 是产品。裸机置备工具。
-
检测硬件,启动硬件,配置 RAID、操作系统并部署工作负载。
-
处理 Kubernetes 的工作负载。
-
看到始于云,然后又回到裸机的趋势。
-
新的提供商模型可以在云和裸机上使用预配置系统。
-
UI, REST API, CLI
-
演示:数据包--裸机即服务
-
4个正在运行的节点归为一个“部署”
-
每个节点选择的功能性角色/操作。
-
分解的 kubernetes 带入可以订购和同步的单元。依赖关系树--诸如在启动 k8s master 之前等待 etcd 启动的事情。
-
在封面下使用 Ansible。
-
演示带来了另外5个节点--数据包将构建这些节点
-
从 ansible 中提取基本参数。诸如网络配置,DNS 设置等内容。
-
角色层次结构引入了其他组件--使节点成为主节点会带来一系列其他必要的角色。
-
通过简单的配置文件将所有这些组合到命令行工具中。
-
-
转发:扩展到多个云以进行测试部署。还希望在裸机和云之间创建拆分/复制。
-
问:秘密?
答:使用 Ansible。构建自己的证书,然后分发它们。想要将它们抽象出来并将其推入上游。 -
问:您是否支持使用 PXE 引导从真正的裸机启动?
答:是的--将发现裸机系统并安装操作系统,安装 ssh 密钥,建立网络等。
-
-
[来自 SIG-scalability]问:转到 golang 1.5 的状态如何?
答:在 HEAD,我们是1.5,但也会支持1.4。有一些跟稳定性相关的问题,但看起来现在情况稳定了。-
还希望使用1.5供应商实验。不再使用 godep。但只有在基线为1.5之前,才能这样做。
-
Sarah:现在我们正在工作的事情之一就是提供做这些事的小奖品。云积分,T恤,扑克筹码,小马。
-
-
[来自可伸缩性兴趣小组]问:清理基于 jenkins 的提交队列的状态如何?社区可以做些什么来帮助您?
答:最近几天一直很艰难。每个方面都应该有相关的问题。在这些问题上有一个片状标签。-
仍在进行联盟测试。现在有更多测试资源。随着新人们的进步,事情有希望进展的更快。这对让很多人在他们的环境中进行端到端测试非常有用。
-
Erick Fjeta 是新的测试负责人
-
Brendan很乐意帮助分享有关 Jenkins 设置的详细信息,但这不是必须的。
-
联盟可以使用 Jenkins API,但不需要 Jenkins 本身。
-
Joe 嘲笑以 Jenkins 的方式运行 e2e 测试是一件棘手的事实。布伦丹说,它应该易于运行。乔再看一眼。
-
符合性测试? etune 做到了,但他不在。 -重新访问20150121
-
-
* 3月10日至11日在伦敦举行。地点将于本周宣布。-
请发送讲话!CFP 截止日期为2月5日。
-
令人兴奋。看起来是700-800人。比SF版本大(560 人)。
-
提前购买门票--早起的鸟儿价格将很快结束,价格将上涨到100英镑。
-
为演讲者提供住宿吗?
-
三星 Bob 的提问:我们可以针对以下问题获得更多警告/计划吗:
-
答:Sarah -- 我不太早就听说过这些东西,但会尝试整理一下清单。努力使 kubernetes.io 上的事件页面更易于使用。
-
答:JJ -- 我们将确保我们早日为下届美国会议提供更多信息。
-
-
-
规模测试[RackN 的 Rob Hirschfeld] -- 如果您想帮助进行规模测试,我们将非常乐意为您提供帮助。
-
Bob 邀请 Rob 加入规模特别兴趣小组。
-
还有一个大型的裸机集群,通过 CNCF(来自 Intel)也很有用。尚无确切日期。
-
-
笔记/视频将发布在 k8s 博客上。(未录制20150114的视频。失败。)
要加入 Kubernetes 社区,请考虑加入我们的Slack 频道,看看GitHub上的Kubernetes 项目,或加入Kubernetes-dev Google 论坛。如果您真的对此感到兴奋,则可以完成上述所有操作,并加入我们的下一次社区对话-2016年1月27日。请将您自己或您想了解的话题添加到议程中,并获得一个加入此群组进行日历邀请。
为什么 Kubernetes 不用 libnetwork
在 1.0 版本发布之前,Kubernetes 已经有了一个非常基础的网络插件形式-大约在引入 Docker’s libnetwork 和 Container Network Model (CNM) 的时候。与 libnetwork 不同,Kubernetes 插件系统仍然保留它的 'alpha' 名称。现在 Docker 的网络插件支持已经发布并得到支持,我们发现一个明显的问题是 Kubernetes 尚未采用它。毕竟,供应商几乎肯定会为 Docker 编写插件-我们最好还是用相同的驱动程序,对吧?
在进一步说明之前,重要的是记住 Kubernetes 是一个支持多种容器运行时的系统, Docker 只是其中之一。配置网络只是每一个运行时的一个方面,所以当人们问起“ Kubernetes 会支持CNM吗?”,他们真正的意思是“ Kubernetes 会支持 Docker 运行时的 CNM 驱动吗?”如果我们能够跨运行时实现通用的网络支持会很棒,但这不是一个明确的目标。
实际上, Kubernetes 还没有为 Docker 运行时采用 CNM/libnetwork 。事实上,我们一直在研究 CoreOS 提出的替代 Container Network Interface (CNI) 模型以及 App Container (appc) 规范的一部分。为什么我们要这么做?有很多技术和非技术的原因。
首先,Docker 的网络驱动程序设计中存在一些基本假设,这些假设会给我们带来问题。
Docker 有一个“本地”和“全局”驱动程序的概念。本地驱动程序(例如 "bridge" )以机器为中心,不进行任何跨节点协调。全局驱动程序(例如 "overlay" )依赖于 libkv (一个键值存储抽象库)来协调跨机器。这个键值存储是另一个插件接口,并且是非常低级的(键和值,没有其他含义)。 要在 Kubernetes 集群中运行类似 Docker's overlay 驱动程序,我们要么需要集群管理员来运行 consul, etcd 或 zookeeper 的整个不同实例 (see multi-host networking) 否则我们必须提供我们自己的 libkv 实现,那被 Kubernetes 支持。
后者听起来很有吸引力,并且我们尝试实现它,但 libkv 接口是非常低级的,并且架构在内部定义为 Docker 。我们必须直接暴露我们的底层键值存储,或者提供键值语义(在我们的结构化API之上,它本身是在键值系统上实现的)。对于性能,可伸缩性和安全性原因,这些都不是很有吸引力。最终结果是,当使用 Docker 网络的目标是简化事情时,整个系统将显得更加复杂。
对于愿意并且能够运行必需的基础架构以满足 Docker 全局驱动程序并自己配置 Docker 的用户, Docker 网络应该“正常工作。” Kubernetes 不会妨碍这样的设置,无论项目的方向如何,该选项都应该可用。但是对于默认安装,实际的结论是这对用户来说是一个不应有的负担,因此我们不能使用 Docker 的全局驱动程序(包括 "overlay" ),这消除了使用 Docker 插件的很多价值。
Docker 的网络模型做出了许多对 Kubernetes 无效的假设。在 docker 1.8 和 1.9 版本中,它包含一个从根本上有缺陷的“发现”实现,导致容器中的 /etc/hosts 文件损坏 (docker #17190) - 并且这不容易被关闭。在 1.10 版本中,Docker 计划 捆绑一个新的DNS服务器,目前还不清楚是否可以关闭它。容器级命名不是 Kubernetes 的正确抽象 - 我们已经有了自己的服务命名,发现和绑定概念,并且我们已经有了自己的 DNS 模式和服务器(基于完善的 SkyDNS )。捆绑的解决方案不足以满足我们的需求,但不能禁用。
与本地/全局拆分正交, Docker 具有进程内和进程外( "remote" )插件。我们调查了是否可以绕过 libnetwork (从而跳过上面的问题)并直接驱动 Docker remote 插件。不幸的是,这意味着我们无法使用任何 Docker 进程中的插件,特别是 "bridge" 和 "overlay",这再次消除了 libnetwork 的大部分功能。
另一方面, CNI 在哲学上与 Kubernetes 更加一致。它比 CNM 简单得多,不需要守护进程,并且至少有合理的跨平台( CoreOS 的 rkt 容器运行时支持它)。跨平台意味着有机会启用跨运行时(例如 Docker , Rocket , Hyper )运行相同的网络配置。 它遵循 UNIX 的理念,即做好一件事。
此外,包装 CNI 插件并生成更加个性化的 CNI 插件是微不足道的 - 它可以通过简单的 shell 脚本完成。 CNM 在这方面要复杂得多。这使得 CNI 对于快速开发和迭代是有吸引力的选择。早期的原型已经证明,可以将 kubelet 中几乎 100% 的当前硬编码网络逻辑弹出到插件中。
我们调查了为 Docker 编写 "bridge" CNM驱动程序 并运行 CNI 驱动程序。事实证明这非常复杂。首先, CNM 和 CNI 模型非常不同,因此没有一种“方法”协调一致。 我们仍然有上面讨论的全球与本地和键值问题。假设这个驱动程序会声明自己是本地的,我们必须从 Kubernetes 获取有关逻辑网络的信息。
不幸的是, Docker 驱动程序很难映射到像 Kubernetes 这样的其他控制平面。具体来说,驱动程序不会被告知连接容器的网络名称 - 只是 Docker 内部分配的 ID 。这使得驱动程序很难映射回另一个系统中存在的任何网络概念。
这个问题和其他问题已由网络供应商提出给 Docker 开发人员,并且通常关闭为“按预期工作”,(libnetwork #139, libnetwork #486, libnetwork #514, libnetwork #865, docker #18864),即使它们使非 Docker 第三方系统更难以与之集成。在整个调查过程中, Docker 明确表示他们对偏离当前路线或委托控制的想法不太欢迎。这对我们来说非常令人担忧,因为 Kubernetes 补充了 Docker 并增加了很多功能,但它存在于 Docker 之外。
出于所有这些原因,我们选择投资 CNI 作为 Kubernetes 插件模型。这会有一些不幸的副作用。它们中的大多数都相对较小(例如, docker inspect 不会显示 IP 地址),特别是由 docker run 启动的容器可能无法与 Kubernetes 启动的容器通信,如果网络集成商想要与 Kubernetes 完全集成,则必须提供 CNI 驱动程序。但另一方面, Kubernetes 将变得更简单,更灵活,早期引入的许多丑陋的(例如配置 Docker 使用我们的网桥)将会消失。
当我们沿着这条道路前进时,我们会保持开放,以便更好地整合和简化。如果您对我们如何做到这一点有所想法,我们真的希望听到它们 - 在 slack 或者 network SIG mailing-list 找到我们。
Tim Hockin, Software Engineer, Google
Simple leader election with Kubernetes and Docker
title: "Kubernetes 和 Docker 简单的 leader election" date: 2016-01-11 slug: simple-leader-election-with-kubernetes url: /blog/2016/01/Simple-Leader-Election-With-Kubernetes
Kubernetes 简化了集群上运行的服务的部署和操作管理。但是,它也简化了这些服务的发展。在本文中,我们将看到如何使用 Kubernetes 在分布式应用程序中轻松地执行 leader election。分布式应用程序通常为了可靠性和可伸缩性而复制服务的任务,但通常需要指定其中一个副本作为负责所有副本之间协调的负责人。
通常在 leader election 中,会确定一组成为领导者的候选人。这些候选人都竞相宣布自己为领袖。其中一位候选人获胜并成为领袖。一旦选举获胜,领导者就会不断地“信号”以表示他们作为领导者的地位,其他候选人也会定期地做出新的尝试来成为领导者。这样可以确保在当前领导因某种原因失败时,快速确定新领导。
实现 leader election 通常需要部署 ZooKeeper、etcd 或 Consul 等软件并将其用于协商一致,或者也可以自己实现协商一致算法。我们将在下面看到,Kubernetes 使在应用程序中使用 leader election 的过程大大简化。
####在 Kubernetes 实施领导人选举
Leader election 的首要条件是确定候选人的人选。Kubernetes 已经使用 Endpoints 来表示组成服务的一组复制 pod,因此我们将重用这个相同的对象。(旁白:您可能认为我们会使用 ReplicationControllers,但它们是绑定到特定的二进制文件,而且通常您希望只有一个领导者,即使您正在执行滚动更新)
要执行 leader election,我们使用所有 Kubernetes api 对象的两个属性:
- ResourceVersions - 每个 API 对象都有一个惟一的 ResourceVersion,您可以使用这些版本对 Kubernetes 对象执行比较和交换
- Annotations - 每个 API 对象都可以用客户端使用的任意键/值对进行注释。
给定这些原语,使用 master election 的代码相对简单,您可以在这里找到here。我们自己来做吧。
$ kubectl run leader-elector --image=gcr.io/google_containers/leader-elector:0.4 --replicas=3 -- --election=example
这将创建一个包含3个副本的 leader election 集合:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
leader-elector-inmr1 1/1 Running 0 13s
leader-elector-qkq00 1/1 Running 0 13s
leader-elector-sgwcq 1/1 Running 0 13s
要查看哪个pod被选为领导,您可以访问其中一个 pod 的日志,用您自己的一个 pod 的名称替换
${pod_name}, (e.g. leader-elector-inmr1 from the above)
$ kubectl logs -f ${name}
leader is (leader-pod-name)
…或者,可以直接检查 endpoints 对象:
_'example' 是上面 kubectl run … 命令_中候选集的名称
$ kubectl get endpoints example -o yaml
现在,要验证 leader election 是否实际有效,请在另一个终端运行:
$ kubectl delete pods (leader-pod-name)
这将删除现有领导。由于 pod 集由 replication controller 管理,因此新的 pod 将替换已删除的pod,确保复制集的大小仍为3。通过 leader election,这三个pod中的一个被选为新的领导者,您应该会看到领导者故障转移到另一个pod。因为 Kubernetes 的吊舱在终止前有一个 grace period,这可能需要30-40秒。
Leader-election container 提供了一个简单的 web 服务器,可以服务于任何地址(e.g. http://localhost:4040)。您可以通过删除现有的 leader election 组并创建一个新的 leader elector 组来测试这一点,在该组中,您还可以向 leader elector 映像传递--http=(host):(port) 规范。这将导致集合中的每个成员通过 webhook 提供有关领导者的信息。
# delete the old leader elector group
$ kubectl delete rc leader-elector
# create the new group, note the --http=localhost:4040 flag
$ kubectl run leader-elector --image=gcr.io/google_containers/leader-elector:0.4 --replicas=3 -- --election=example --http=0.0.0.0:4040
# create a proxy to your Kubernetes api server
$ kubectl proxy
然后您可以访问:
http://localhost:8001/api/v1/proxy/namespaces/default/pods/(leader-pod-name):4040/
你会看到:
{"name":"(name-of-leader-here)"}
有副手的 leader election
好吧,那太好了,你可以通过 HTTP 进行leader election 并找到 leader,但是你如何从自己的应用程序中使用它呢?这就是 sidecar 的由来。Kubernetes 中,Pods 由一个或多个容器组成。通常情况下,这意味着您将 sidecar containers 添加到主应用程序中以组成 pod。(关于这个主题的更详细的处理,请参阅我之前的博客文章)。 Leader-election container 可以作为一个 sidecar,您可以从自己的应用程序中使用。Pod 中任何对当前 master 感兴趣的容器都可以简单地访问http://localhost:4040,它们将返回一个包含当前 master 名称的简单 json 对象。由于 pod中 的所有容器共享相同的网络命名空间,因此不需要服务发现!
例如,这里有一个简单的 Node.js 应用程序,它连接到 leader election sidecar 并打印出它当前是否是 master。默认情况下,leader election sidecar 将其标识符设置为 hostname。
var http = require('http');
// This will hold info about the current master
var master = {};
// The web handler for our nodejs application
var handleRequest = function(request, response) {
response.writeHead(200);
response.end("Master is " + master.name);
};
// A callback that is used for our outgoing client requests to the sidecar
var cb = function(response) {
var data = '';
response.on('data', function(piece) { data = data + piece; });
response.on('end', function() { master = JSON.parse(data); });
};
// Make an async request to the sidecar at http://localhost:4040
var updateMaster = function() {
var req = http.get({host: 'localhost', path: '/', port: 4040}, cb);
req.on('error', function(e) { console.log('problem with request: ' + e.message); });
req.end();
};
/ / Set up regular updates
updateMaster();
setInterval(updateMaster, 5000);
// set up the web server
var www = http.createServer(handleRequest);
www.listen(8080);
当然,您可以从任何支持 HTTP 和 JSON 的语言中使用这个 sidecar。
结论
希望我已经向您展示了使用 Kubernetes 为您的分布式应用程序构建 leader election 是多么容易。在以后的部分中,我们将向您展示 Kubernetes 如何使构建分布式系统变得更加容易。同时,转到Google Container Engine或kubernetes.io开始使用Kubernetes。
使用 Puppet 管理 Kubernetes Pods,Services 和 Replication Controllers
今天的嘉宾帖子是由 IT 自动化领域的领导者 Puppet Labs 的高级软件工程师 Gareth Rushgrove 撰写的。Gareth告诉我们一个新的 Puppet 模块,它帮助管理 Kubernetes 中的资源。
熟悉[Puppet]的人(https://github.com/puppetlabs/puppet)可能使用它来管理主机上的文件、包和用户。但是Puppet首先是一个配置管理工具,配置管理是一个比管理主机级资源更广泛的规程。配置管理的一个很好的定义是它旨在解决四个相关的问题:标识、控制、状态核算和验证审计。这些问题存在于任何复杂系统的操作中,并且有了新的Puppet Kubernetes module,我们开始研究如何为 Kubernetes 解决这些问题。
Puppet Kubernetes 模块
Puppet kubernetes 模块目前假设您已经有一个 kubernetes 集群 [启动并运行]](http://kubernetes.io/gettingstarted/)。它的重点是管理 Kubernetes中的资源,如 Pods、Replication Controllers 和 Services,而不是(现在)管理底层的 kubelet 或 etcd services。下面是描述 Puppet’s DSL 中一个 Pod 的简短代码片段。
kubernetes_pod { 'sample-pod':
ensure => present,
metadata => {
namespace => 'default',
},
spec => {
containers => [{
name => 'container-name',
image => 'nginx',
}]
},
}
如果您熟悉 YAML 文件格式,您可能会立即识别该结构。 该接口故意采取相同的格式以帮助在不同格式之间进行转换 — 事实上,为此提供支持的代码是从Kubernetes API Swagger自动生成的。 运行上面的代码,假设我们将其保存为 pod.pp,就像下面这样简单:
puppet apply pod.pp
身份验证使用标准的 kubectl 配置文件。您可以在模块的自述文件中找到完整的README。
Kubernetes 有很多资源,来自 Pods、 Services、 Replication Controllers 和 Service Accounts。您可以在Puppet 中的 kubernetes 留言簿示例文章中看到管理这些资源的模块示例。这演示了如何将规范的 hello-world 示例转换为使用 Puppet代码。
然而,使用 Puppet 的一个主要优点是,您可以创建自己的更高级别和更特定于业务的接口,以连接 kubernetes 管理的应用程序。例如,对于留言簿,可以创建如下内容:
guestbook { 'myguestbook':
redis_slave_replicas => 2,
frontend_replicas => 3,
redis_master_image => 'redis',
redis_slave_image => 'gcr.io/google_samples/gb-redisslave:v1',
frontend_image => 'gcr.io/google_samples/gb-frontend:v3',
}
您可以在Puppet博客文章在 Puppet 中为 Kubernetes 构建自己的抽象中阅读更多关于使用 Puppet 定义的类型的信息,并看到更多的代码示例。
结论
使用 Puppet 而不仅仅是使用标准的 YAML 文件和 kubectl 的优点是:
- 能够创建自己的抽象,以减少重复和设计更高级别的用户界面,如上面的留言簿示例。
- 使用 Puppet 的开发工具验证代码和编写单元测试。
- 与 Puppet Server 等其他工具配合,以确保代码中的模型与集群的状态匹配,并与 PuppetDB 配合工作,以存储报告和跟踪更改。
- 能够针对 Kubernetes API 重复运行相同的代码,以检测任何更改或修正配置。
值得注意的是,大多数大型组织都将拥有非常异构的环境,运行各种各样的软件和操作系统。拥有统一这些离散系统的单一工具链可以使采用 Kubernetes 等新技术变得更加容易。
可以肯定地说,Kubernetes提供了一组优秀的组件来构建云原生系统。使用 Puppet,您可以解决在生产中运行任何复杂系统所带来的一些操作和配置管理问题。告诉我们如果您试用了该模块,您会有什么想法,以及您希望在将来看到哪些支持。
Gareth Rushgrove,Puppet Labs 高级软件工程师
Kubernetes 1.1 性能升级,工具改进和社区不断壮大
自从 Kubernetes 1.0 在七月发布以来,我们已经看到大量公司采用建立分布式系统来管理其容器集群。 我们也对帮助 Kubernetes 社区变得更好,迅速发展的人感到钦佩。 我们已经看到诸如 CoreOS 的 Tectonic 和 RedHat Atomic Host 之类的商业产品应运而生,用以提供 Kubernetes 的部署和支持。 一个不断发展的生态系统增加了 Kubernetes 的支持,包括 Sysdig 和 Project Calico 等工具供应商。
在数百名贡献者的帮助下,我们自豪地宣布 Kubernetes 1.1 的可用性,它提供了主要的性能升级、改进的工具和新特性,使应用程序更容易构建和部署。
我们想强调的一些工作包括:
- 实质性的性能提升 :从第一天开始,我们就设计了 Kubernetes 来处理 Google 规模的工作负载,而我们的客户已经按照自己的进度进行了调整。 在 Kubernetes 1.1 中,我们进行了进一步的投资,以确保您可以在超大规模环境中运行; 本周晚些时候,我们将分享运行数千个节点集群,并针对单个集群运行超过一百万个 QPS 的示例。
- 网络吞吐量显着提高 : 运行 Google 规模的工作负载也需要 Google 规模的网络。 在 Kubernetes 1.1 中,我们提供了使用本机IP表的选项,可将尾部延迟减少80%,几乎完全消除了CPU开销,并提高了可靠性和系统架构,从而确保Kubernetes可以很好地处理未来的大规模吞吐量。
- 水平 Pod 自动缩放 (测试版):许多工作负载可能会经历尖峰的使用期,从而给用户带来不均匀的体验。 Kubernetes 现在支持水平 Pod 自动缩放,这意味着您的 Pod 可以根据 CPU 使用率进行缩放。 阅读有关水平 Pod 自动缩放的更多信息。
- HTTP 负载均衡器 (测试版):Kubernetes 现在具有基于数据包自省功能来路由 HTTP 流量的内置功能。 这意味着您可以让 ‘http://foo.com/bar’ 使用一项服务,而 ‘http://foo.com/meep’ 使用一项完全独立的服务。 阅读有关Ingress对象的更多信息。
- Job 对象 (测试版):我们也经常需要集成的批处理 Job ,例如处理一批图像以创建缩略图,或者将特别大的数据文件分解成很多块。 Job 对象引入了一个新的 API 对象,该对象运行工作负载, 如果失败,则重新启动它,并继续尝试直到成功完成。 阅读有关Job 对象的更多信息。
- 新功能可缩短开发人员的测试周期 :我们将继续致力于快速便捷地为 Kubernetes 开发应用程序。 加快开发人员工作流程的两项新功能包括以交互方式运行容器的功能,以及改进的架构验证功能,可在部署配置文件之前让您知道配置文件是否存在任何问题。
- 滚动更新改进 : DevOps 运动的核心是能够发布新更新,而不会影响正在运行的服务。 滚动更新现在可确保在继续更新之前,已更新的 Pod 状况良好。
- 还有很多。有关更新的完整列表,请参见1.1. 发布在GitHub上的笔记
今天,我们也很荣幸地庆祝首届Kubernetes会议KubeCon,约有400个社区成员以及数十个供应商参加支持 Kubernetes 项目的会议。
我们想强调几个使 Kuberbetes 变得更好的众多合作伙伴中的几位:
“我们押注我们的主要产品 Tectonic-它能使任何公司都能在任何地方部署、管理和保护其容器-在 Kubernetes 上使用,因为我们认为这是数据中心的未来。 Kubernetes 1.1 的发布是另一个重要的里程碑,它将使分布式系统和容器得到更广泛的采用,并使我们走上一条必将导致新一代产品和服务的道路。” – CoreOS 首席执行官Alex Polvi
“Univa 的客户正在寻找可扩展的企业级解决方案,以简化企业中容器和非容器工作负载的管理。 我们选择Kubernetes作为我们新的 Navops 套件的基础,它将帮助 IT 和 DevOps 将容器化工作负载快速集成到他们的生产系统中,并将这些工作负载扩展到云服务中。” – Univa 首席执行官 Gary Tyreman
“我们看到通过 Kubernetes 大规模运行容器的巨大客户需求是推动 Redapt 专业服务业务增长的关键因素。 作为值得信赖的顾问,在我们的工具带中有像 Kubernetes 这样的工具能够帮助我们的客户实现他们的目标,这是非常棒的。“ – Redapt SR 云解决方案副总裁 Paul Welch
如上所述,我们希望得到您的帮助:
- 在 GitHub上参与 Kubernetes 项目;
- 通过 Slack 与社区联系;
- 关注我们的 Twitter @Kubernetesio 获取最新信息;
- 在 Stackoverflow 上发布问题(或回答问题)
- 开始运行,部署和使用 Kubernetes 指南;
但是,最重要的是,请让我们知道您是如何使用 Kubernetes 改变您的业务的,以及我们如何可以帮助您更快地做到这一点。谢谢您的支持!
- David Aronchick, Kubernetes 和谷歌容器引擎的高级产品经理
Weekly Kubernetes Community Hangout Notes - July 31 2015
title: " Kubernetes社区每周环聊笔记-2015年7月31日 " date: 2015-08-04 slug: weekly-kubernetes-community-hangout url: /blog/2015/08/Weekly-Kubernetes-Community-Hangout
每周,Kubernetes 贡献社区都会通过Google 环聊虚拟开会。我们希望任何有兴趣的人都知道本论坛讨论的内容。
这是今天会议的笔记:
-
私有镜像仓库演示 - Muhammed
-
将 docker-registry 作为 RC/Pod/Service 运行
-
在每个节点上运行代理
-
以 localhost:5000 访问
-
讨论:
-
我们应该在可能的情况下通过 GCS 或 S3 支持它吗?
-
在每个节点上运行由 $object_store 支持的真实镜像仓库
-
DNS 代替 localhost?
-
分解 docker 镜像字符串?
-
更像 DNS 策略吗?
-
-
-
-
运行大型集群 - Joe
-
三星渴望看到大规模 O(1000)
- 从 AWS 开始
-
RH 也有兴趣 - 需要测试计划
-
计划下周:讨论工作组
-
如果您有兴趣加入有关集群可扩展性的对话,请发送邮件至[joe@0xBEDA.com][4]
-
-
资源 API 提案 - Clayton
-
新东西需要更多资源信息
-
关于资源 API 的提案 - 向 apiserver 询问有关pod的信息
-
发送反馈至:#11951
-
关于快照,时间序列和聚合的讨论
-
-
容器化 kubelet - Clayton
-
打开 pull
-
Docker挂载传播 - RH 带有补丁
-
有关整个系统引导程序的大问题
- 双:引导docker /系统docker
-
Kube-in-docker非常好,但可能并不关键
-
做些小事以取得进步
-
对 docker 施加压力
-
-
-
Web UI(preilly)
-
Web UI 放在哪里?
-
确定将其拆分出去
-
将其用作容器镜像
-
作为 kube 发布过程的一部分构建映像
-
vendor回来了吗?也许吧,也许不是。
-
-
DNS将被拆分吗?
- 可能更紧密地集成在一起,而不是
-
其他潜在的衍生产品:
-
apiserver
-
clients
-
-
宣布首个Kubernetes企业培训课程
在谷歌,我们依赖 Linux 容器应用程序去运行我们的核心基础架构。所有服务,从搜索引擎到Gmail服务,都运行在容器中。事实上,我们非常喜欢容器,甚至我们的谷歌云计算引擎虚拟机也运行在容器上!由于容器对于我们的业务至关重要,我们已经与社区合作开发许多基本的容器技术(从 cgroups 到 Docker 的 LibContainer),甚至决定去构建谷歌的下一代开源容器调度技术,Kubernetes。
在 Kubernetes 项目进行一年后,在 OSCON 上发布 V1 版本的前夕,我们很高兴的宣布Kubernetes 的主要贡献者 Mesosphere 组织了有史以来第一次正规的以企业为中心的 Kubernetes 培训会议。首届会议将于 6 月 20 日在波特兰的 OSCON 举办,由来自 Mesosphere 的 Zed Shaw 和 Michael Hausenblas 演讲。Pre-registration 对于优先注册者是免费的,但名额有限,立刻行动吧!
这个为期一天的课程将包涵使用 Kubernetes 构建和部署容器化应用程序的基础知识。它将通过完整的流程引导与参会者创建一个 Kubernetes 的应用程序体系结构,创建和配置 Docker 镜像,并把它们部署到 Kubernetes 集群上。用户还将了解在我们的谷歌容器引擎和 Mesosphere 的数据中心操作系统上部署 Kubernetes 应用程序和服务的基础知识。
即将推出的 Kubernetes bootcamp 将是学习如何应用 Kubernetes 解决长期部署和应用程序管理问题的一个好途径。相对于我们所预期的,来自于广泛社区的众多培训项目而言,这只是其中一个。
幻灯片:Kubernetes 集群管理,爱丁堡大学演讲
2015年6月5日星期五,我在爱丁堡大学给普通听众做了一个演讲,题目是使用 Kubernetes 进行集群管理。这次演讲包括一个带有 Kibana 前端 UI 的音乐存储系统的例子,以及一个基于 Elasticsearch 的后端,该后端有助于生成具体的概念,如 pods、复制控制器和服务。
OpenStack 上的 Kubernetes

今天,OpenStack 基金会通过在其社区应用程序目录中包含 Kubernetes,使您更容易在 OpenStack 云上部署和管理 Docker 容器集群。 今天在温哥华 OpenStack 峰会上的主题演讲中,OpenStack 基金会的首席运营官:Mark Collier 和 Mirantis 产品线经理 Craig Peters 通过利用 OpenStack 云中已经存在的计算、存储、网络和标识系统,在几秒钟内启动了 Kubernetes 集群,展示了社区应用程序目录的工作流。
目录中的条目不仅包括启动 Kubernetes 集群的功能,还包括部署在 Kubernetes 管理的 Docker 容器中的一系列应用程序。这些应用包括:
Apache web 服务器
Nginx web 服务器
Crate - Docker的分布式数据库
GlassFish - Java EE 7 应用服务器
Tomcat - 一个开源的 web 服务器和 servlet 容器
InfluxDB - 一个开源的、分布式的、时间序列数据库
Grafana - InfluxDB 的度量仪表板
Jenkins - 一个可扩展的开放源码持续集成服务器
MariaDB 数据库
MySql 数据库
Redis - 键-值缓存和存储
PostgreSQL 数据库
MongoDB NoSQL 数据库
Zend 服务器 - 完整的 PHP 应用程序平台
此列表将会增长,并在此处进行策划。您可以检查(并参与)YAML 文件,该文件告诉 Murano 如何根据此处定义来安装和启动 ...apps/blob/master/Docker/Kubernetes/KubernetesCluster/package/Classes/KubernetesCluster.yaml)安装和启动 Kubernetes 集群。
Kubernetes 开源项目继续受到社区的欢迎,并且势头越来越好,GitHub 上有超过 11000 个提交和 7648 颗星。从 Red Hat 和 Intel 到 CoreOS 和 Box.net,它已经代表了从企业 IT 到前沿创业企业的一系列客户。我们鼓励您尝试一下,给我们您的反馈,并参与到我们不断增长的社区中来。
- Martin Buhr, Kubernetes 开源项目产品经理
Kubernetes 社区每周聚会笔记- 2015年5月1日
每个星期,Kubernetes 贡献者社区几乎都会在谷歌 Hangouts 上聚会。我们希望任何对此感兴趣的人都能了解这个论坛的讨论内容。
-
简单的滚动更新 - Brendan
-
滚动更新 = RCs和Pods很好的例子。
-
...pause… (Brendan 需要 Kelsey 的演示恢复技巧)
-
滚动更新具有恢复功能:取消更新并重新启动,更新从停止的地方继续。
-
新控制器获取旧控制器的名称,因此外观是纯粹的更新。
-
还可以在 update 中命名版本(最后不会重命名)。
-
-
Rocket 演示 - CoreOS 的伙计们
-
Rocket 和 docker 之间的主要区别: Rocket 是无守护进程和以 pod 为中心。。
-
Rocket 具有原生的 AppContainer 格式,但也支持 docker 镜像格式。
-
可以在同一个 pod 中运行 AppContainer 和 docker 容器。
-
变更接近于合并。
-
-
演示 service accounts 和 secrets 被添加到 pod - Jordan
-
问题:很难获得与API通信的令牌。
-
新的API对象:"ServiceAccount"
-
ServiceAccount 是命名空间,控制器确保命名空间中至少存在一个个默认 service account。
-
键入 "ServiceAccountToken",控制器确保至少有一个默认令牌。
-
演示
-
* 可以使用 ServiceAccountToken 创建新的 service account。控制器将为它创建令牌。 -
可以创建一个带有 service account 的 pod, pod 将在 /var/run/secrets/kubernets.io/…
-
-
Kubelet 在容器中运行 - Paul
- Kubelet 成功地运行了带有 secret 的 pod。
AppC Support for Kubernetes through RKT
title: " 通过 RKT 对 Kubernetes 的 AppC 支持 " date: 2015-05-04 slug: appc-support-for-kubernetes-through-rkt url: /blog/2015/05/Appc-Support-For-Kubernetes-Through-Rkt
我们最近接受了对 Kubernetes 项目的拉取请求,以增加对 Kubernetes 社区的应用程序支持。 AppC 是由 CoreOS 发起的新的开放容器规范,并通过 CoreOS rkt 容器运行时受到支持。
对于Kubernetes项目和更广泛的容器社区而言,这是重要的一步。 它为容器语言增加了灵活性和选择余地,并为Kubernetes开发人员带来了令人信服的新安全性和性能功能。
与智能编排技术(例如 Kubernetes 和/或 Apache Mesos)配合使用时,基于容器的运行时(例如 Docker 或 rkt)对开发人员构建和运行其应用程序的方式是一种合法干扰。 尽管支持技术还处于新生阶段,但它们确实为组装,部署,更新,调试和扩展解决方案提供了一些非常强大的新方法。 我相信,世界还没有意识到容器的全部潜力,未来几年将特别令人兴奋! 考虑到这一点,有几个具有不同属性和不同目的的项目才有意义。能够根据给定应用程序的特定需求将不同的部分(无论是容器运行时还是编排工具)插入在一起也是有意义的。
Docker 在使容器技术民主化并使外界可以访问它们方面做得非常出色,我们希望 Kubernetes 能够无限期地支持 Docker。CoreOS 还开始与 rkt 进行有趣的工作,以创建一个优雅,干净,简单和开放的平台,该平台提供了一些非常有趣的属性。 这看起来蓄势待发,可以为容器提供安全,高性能的操作环境。 Kubernetes 团队已经与 CoreOS 的 appc 团队合作了一段时间,在许多方面,他们都将 Kubernetes 作为简单的可插入运行时组件来构建 rkt。
真正的好处是,借助 Kubernetes,您现在可以根据工作负载的需求选择最适合您的容器运行时,无需替换集群环境即可更改运行时,甚至可以将在同一集群中在不同容器中运行的应用程序的不同部分混合在一起。 其他选择无济于事,但最终使最终开发人员受益。
-- Craig McLuckie Google 产品经理和 Kubernetes 联合创始人
Kubernetes 社区每周聚会笔记- 2015年4月24日
每个星期,Kubernetes 贡献者社区几乎都会在谷歌 Hangouts 上聚会。我们希望任何对此感兴趣的人都能了解这个论坛的讨论内容。
日程安排:
- Flocker 和 Kubernetes 集成演示
笔记:
- flocker 和 kubernetes 集成演示
-
-
Flocker Q/A
-
迁移后文件是否仍存在于node1上?
-
Brendan: 有没有计划把它做成一本书?我们不需要 powerstrip?
-
Luke: 需要找出感兴趣的来决定我们是否想让它成为 kube 中的一个一流的持久性磁盘提供商。
-
Brendan: 删除对 powerstrip 的需求会使其易于使用。完全去做。
-
Tim: 将它添加到 kubernetes 应该不超过45分钟:)
-
-
-
* Derek: 持久卷和请求相比呢?
* Luke: 除了基于 ZFS 的新后端之外,差别不大。使工作负载真正可移植。
* Tim: 与基于网络的卷非常不同。有趣的是,它是唯一允许升级媒体的产品。
* Brendan: 请求,它如何查找重复请求?Cassandra 希望在底层复制数据。向上和向下扩缩是有效的。根据负载动态地创建存储。它的步骤不仅仅是快照——通过编程使用预分配创建副本。
* Tim: 帮助自动配置。
* Brian: flocker 是否需要其他组件?
* Kai: Flocker 控制服务与主服务器位于同一位置。(dia 在博客上)。Powerstrip + Powerstrip Flocker。对在 etcd 中持久化状态非常有趣。它保存关于每个卷的元数据。
* Brendan: 在未来,flocker 可以是一个插件,我们将负责持久性。发布 v1.0。
* Brian: 有兴趣为 flocker 等服务添加通用插件。
* Luke: 当扩展到单个节点上的许多容器时,Zfs 会变得非常有价值。
* Alex: flocker 服务可以作为 pod 运行吗?
* Kai: 是的,唯一的要求是 flocker 控制服务应该能够与 zfs 代理对话。需要在主机上安装 zfs 代理,并且需要访问 zfs 二进制文件。
* Brendan: 从理论上讲,所有 zfs 位都可以与设备一起放入容器中。
* Luke: 是的,仍然在处理跨容器安装问题。
* Tim: pmorie 正在通过它使 kubelet 在容器中工作。可能重复使用。
* Kai: Cinder 支持即将到来。几天之后。
- Bob: 向 GKE 推送 kube 的过程是怎样的?需要更多的可见度。
Borg: Kubernetes 的前身
十多年来,谷歌一直在生产中运行容器化工作负载。 无论是像网络前端和有状态服务器之类的工作,像 Bigtable 和 Spanner一样的基础架构系统,或是像 MapReduce 和 Millwheel一样的批处理框架, Google 的几乎一切都是以容器的方式运行的。今天,我们揭开了 Borg 的面纱,Google 传闻已久的面向容器的内部集群管理系统,并在学术计算机系统会议 Eurosys 上发布了详细信息。你可以在 此处 找到论文。
Kubernetes 直接继承自 Borg。 在 Google 的很多从事 Kubernetes 的开发人员以前都是 Borg 项目的开发人员。 我们在 Kubernetes 中结合了 Borg 的最佳创意,并试图解决用户多年来在 Borg 中发现的一些痛点。
Kubernetes 中的以下四个功能特性源于我们从 Borg 获得的经验:
- Pods. Pod 是 Kubernetes 中调度的单位。 它是一个或多个容器在其中运行的资源封装。 保证属于同一 Pod 的容器可以一起调度到同一台计算机上,并且可以通过本地卷共享状态。
Borg 有一个类似的抽象,称为 alloc(“资源分配”的缩写)。 Borg 中 alloc 的常见用法包括运行 Web 服务器,该服务器生成日志,一起部署一个轻量级日志收集进程, 该进程将日志发送到集群文件系统(和 fluentd 或 logstash 没什么不同 ); 运行 Web 服务器,该 Web 服务器从磁盘目录提供数据, 该磁盘目录由从集群文件系统读取数据并为 Web 服务器准备/暂存的进程填充(与内容管理系统没什么不同); 并与存储分片一起运行用户定义的处理功能。
Pod 不仅支持这些用例,而且还提供类似于在单个 VM 中运行多个进程的环境 -- Kubernetes 用户可以在 Pod 中部署多个位于同一地点的协作过程,而不必放弃一个应用程序一个容器的部署模型。
- 服务。 尽管 Borg 的主要角色是管理任务和计算机的生命周期,但是在 Borg 上运行的应用程序还可以从许多其它集群服务中受益,包括命名和负载均衡。 Kubernetes 使用服务抽象支持命名和负载均衡:带名字的服务,会映射到由标签选择器定义的一组动态 Pod 集(请参阅下一节)。 集群中的任何容器都可以使用服务名称链接到服务。
在幕后,Kubernetes 会自动在与标签选择器匹配到 Pod 之间对与服务的连接进行负载均衡,并跟踪 Pod 在哪里运行,由于故障,它们会随着时间的推移而重新安排。
- 标签。 Borg 中的容器通常是一组相同或几乎相同的容器中的一个副本,该容器对应于 Internet 服务的一层(例如 Google Maps 的前端)或批处理作业的工人(例如 MapReduce)。 该集合称为 Job ,每个副本称为任务。 尽管 Job 是一个非常有用的抽象,但它可能是有限的。 例如,用户经常希望将其整个服务(由许多 Job 组成)作为一个实体进行管理,或者统一管理其服务的几个相关实例,例如单独的 Canary 和稳定的发行版。 另一方面,用户经常希望推理和控制 Job 中的任务子集 --最常见的示例是在滚动更新期间,此时作业的不同子集需要具有不同的配置。
通过使用标签组织 Pod ,Kubernetes 比 Borg 支持更灵活的集合,标签是用户附加到 Pod(实际上是系统中的任何对象)的任意键/值对。 用户可以通过在其 Pod 上使用 “job:<jobname>” 标签来创建与 Borg Jobs 等效的分组,但是他们还可以使用其他标签来标记服务名称,服务实例(生产,登台,测试)以及一般而言,其 pod 的任何子集。 标签查询(称为“标签选择器”)用于选择操作应用于哪一组 Pod 。 结合起来,标签和复制控制器 允许非常灵活的更新语义,以及跨等效项的操作 Borg Jobs。
- 每个 Pod 一个 IP。在 Borg 中,计算机上的所有任务都使用该主机的 IP 地址,从而共享主机的端口空间。 虽然这意味着 Borg 可以使用普通网络,但是它给基础结构和应用程序开发人员带来了许多负担:Borg 必须将端口作为资源进行调度;任务必须预先声明它们需要多少个端口,并将要使用的端口作为启动参数;Borglet(节点代理)必须强制端口隔离;命名和 RPC 系统必须处理端口以及 IP 地址。
多亏了软件定义的覆盖网络,例如 flannel 或内置于公有云网络的出现,Kubernetes 能够为每个 Pod 提供服务并为其提供自己的 IP 地址。 这消除了管理端口的基础架构的复杂性,并允许开发人员选择他们想要的任何端口,而不需要其软件适应基础架构选择的端口。 后一点对于使现成的易于运行 Kubernetes 上的开源应用程序至关重要 -- 可以将 Pod 视为 VMs 或物理主机,可以访问整个端口空间,他们可能与其他 Pod 共享同一台物理计算机,这一事实已被忽略。
随着基于容器的微服务架构的日益普及,Google 从内部运行此类系统所汲取的经验教训已引起外部 DevOps 社区越来越多的兴趣。 通过揭示集群管理器 Borg 的一些内部工作原理,并将下一代集群管理器构建为一个开源项目(Kubernetes)和一个公开可用的托管服务([Google Container Engine](http://cloud.google.com/container-engine)) ,我们希望这些课程可以使 Google 之外的广大社区受益,并推动容器调度和集群管理方面的最新技术发展。
Kubernetes 社区每周聚会笔记- 2015年4月17日
每个星期,Kubernetes 贡献者社区几乎都会在谷歌 Hangouts 上聚会。我们希望任何对此感兴趣的人都能了解这个论坛的讨论内容。
议程
- Mesos 集成
- 高可用性(HA)
- 向 e2e 添加性能和分析详细信息以跟踪回归
- 客户端版本化
笔记
-
Mesos 集成
-
Mesos 集成提案:
-
没有阻塞集成的因素。
-
文档需要更新。
-
-
HA
-
提案今天应该会提交。
-
Etcd 集群。
-
apiserver 负载均衡。
-
控制器管理器和其他主组件的冷备用。
-
-
向 e2e 添加性能和分析详细信息以跟踪回归
-
希望红色为性能回归
-
需要公共数据库才能发布数据
- 查看
-
Justin 致力于多平台 e2e 仪表盘
-
-
客户端版本化
-
客户端库当前使用内部 API 对象。
-
尽管没有人反映频繁修改
types.go有多痛苦,但我们很为此担心。 -
结构化类型在客户端中很有用。版本化的结构就可以了。
-
如果从 json/yaml (kubectl) 开始,则不应转换为结构化类型。使用 swagger。
-
-
Security context
-
管理员可以限制谁可以运行特权容器或需要特定的 unix uid
-
kubelet 将能够从 apiserver 获取证书
-
政策提案将于下周左右出台
-
-
讨论用户的上游,等等进入Kubernetes,至少是可选的
-
1.0 路线图
-
重点是性能,稳定性,集群升级
-
TJ 一直在对roadmap.md进行一些编辑,但尚未发布PR
-
-
Kubernetes UI
-
依赖关系分解为第三方
-
@lavalamp 是评论家
-
[*[3:27 PM]: 2015-04-17T15:27:00-07:00
Kubernetes Release: 0.15.0
Release 说明:
- 启用 1beta3 API 并将其设置为默认 API 版本 (#6098)
- 增加了多端口服务(#6182)
- 添加了一个控制器框架 (#5270, #5473)
- Kubelet 现在监听一个安全的 HTTPS 端口 (#6380)
- 使 kubectl 错误更加友好 (#6338)
- apiserver 现在支持客户端 cert 身份验证 (#6190)
- apiserver 现在限制了它处理的并发请求的数量 (#6207)
- 添加速度限制删除 pod (#6355)
- 将平衡资源分配算法作为优先级函数实现在调度程序包中 (#6150)
- 从主服务器启用日志收集功能 (#6396)
- 添加了一个 api 端口来从 Pod 中提取日志 (#6497)
- 为调度程序添加了延迟指标 (#6368)
- 为 REST 客户端添加了延迟指标 (#6409)
- etcd 现在在 master 上的一个 pod 中运行 (#6221)
- nginx 现在在 master上的容器中运行 (#6334)
- 开始为主组件构建 Docker 镜像 (#6326)
- 更新了 GCE 程序以使用 gcloud 0.9.54 (#6270)
- 更新了 AWS 程序来修复区域与区域语义 (#6011)
- 记录镜像 GC 失败时的事件 (#6091)
- 为 kubernetes 客户端添加 QPS 限制器 (#6203)
- 减少运行 make release 所需的时间 (#6196)
- 新卷的支持
- 更新到 heapster 版本到 v0.10.0 (#6331)
- 更新到 etcd 2.0.9 (#6544)
- 更新到 Kibana 到 v1.2 (#6426)
- 漏洞修复
要下载,请访问 https://github.com/GoogleCloudPlatform/kubernetes/releases/tag/v0.15.0
每周 Kubernetes 社区例会笔记 - 2015年4月3日
Kubernetes: 每周 Kubernetes 社区聚会笔记
每周,Kubernetes 贡献社区几乎都会通过 Google Hangouts 开会。 我们希望任何有兴趣的人都知道本论坛讨论的内容。
议程:
- Quinton - 集群联邦
- Satnam - 性能基准测试更新
会议记录:
- Quinton - 集群联邦
- 在旧金山见面会后,想法浮出水面
-
- 请阅读、评论
- 不是 1.0,而是将文档放在一起以显示路线图
- 可以在 Kubernetes 之外构建
- 用于控制多个集群中事物的 API ,包括一些逻辑
-
Auth(n)(z)
-
调度策略
-
……
- 集群联邦的不同原因
-
区域(非)可用性:对区域故障的弹性
-
混合云:有些在云中,有些在本地。 由于各种原因
-
避免锁定云提供商。 由于各种原因
-
"Cloudbursting" - 自动溢出到云中
- 困难的问题
-
位置亲和性。Pod 需要多近?
-
工作负载的耦合
-
绝对位置(例如,欧盟数据需要在欧盟内)
-
-
跨集群服务发现
- 服务/DNS 如何跨集群工作
-
跨集群工作负载迁移
- 如何在跨集群中逐块移动应用程序?
-
跨集群调度
-
如何充分了解集群以知道在哪里进行调度
-
可能使用成本函数以最小的复杂性得出亲和性
-
还可以使用成本来确定调度位置(使用不足的集群比过度使用的集群便宜)
-
- 隐含要求
-
跨集群集成不应创建跨集群故障模式
- 在 Ubernetes 死亡的灾难情况下可以独立使用。
-
统一可见性
- 希望有统一的监控,报警,日志,内省,用户体验等。
-
统一的配额和身份管理
- 希望将用户数据库和 auth(n)/(z) 放在一个位置
- 需要注意的是,导致软件故障的大多数原因不是基础架构
-
拙劣的软件升级
-
拙劣的配置升级
-
拙劣的密钥分发
-
过载
-
失败的外部依赖
- 讨论:
-
”ubernetes“ 的边界确定
- 可能在可用区,但也可能在机架,或地区
-
重要的是不要鸽子洞并防止其他用户
- Satnam - 浸泡测试
- 想要测量长时间运行的事务,以确保集群在一段时间内是稳定的。性能不会降低,不会发生内存泄漏等。
- github.com/GoogleCloudPlatform/kubernetes/test/soak/…
- 单个二进制文件,在每个节点上放置许多 Pod,并查询每个 Pod 以确保其正在运行。
- Pod 的创建速度越来越快(即使在过去一周内),也可以使事情进展得更快。
- Pod 运行起来后,我们通过代理点击 Pod。决定使用代理是有意的,因此我们测试了 kubernetes apiserver。
- 代码已经签入。
- 将 Pod 固定在每个节点上,练习每个 Pod,确保你得到每个节点的响应。
- 单个二进制文件,永远运行。
- Brian - v1beta3 默认启用, v1beta1 和 v1beta2 不支持,在6月关闭。仍应与升级现有集群等一起使用。
Kubernetes 社区每周聚会笔记 - 2015年3月27日
每个星期,Kubernetes 贡献者社区几乎都会在谷歌 Hangouts 上聚会。我们希望任何对此感兴趣的人都能了解这个论坛的讨论内容。
日程安排:
- Andy - 演示远程执行和端口转发
- Quinton - 联邦集群 - 延迟
- Clayton - 围绕 Kubernetes 的 UI 代码共享和协作
从会议指出:
1. Andy 从 RedHat:
- 演示远程执行
* kubectl exec -p $POD -- $CMD
* 作为代理与主机建立连接,找出 pod 所在的节点,代理与 kubelet 的连接,这一点很有趣。通过 nsenter。
* 使用 SPDY 通过 HTTP 进行多路复用流式传输
* 还有互动模式:
* 假设第一个容器,可以使用 -c $CONTAINER 一个特定的。
* 如果在容器中预先安装了 gdb,则可以交互地将其附加到正在运行的进程中
* backtrace、symbol tbles、print 等。 使用gdb可以做的大多数事情。
* 也可以用精心制作的参数在上面运行 rsync 或者在容器内设置 sshd。
* 一些聊天反馈:
- Andy 还演示了端口转发
- nnsenter 与 docker exec
* 想要在主机的控制下注入二进制文件,类似于预启动钩子
* socat、nsenter,任何预启动钩子需要的
- 如果能在博客上发表这方面的文章就太好了
- wheezy 中的 nginx 版本太旧,无法支持所需的主代理功能
2. Clayton: 我们的社区组织在哪里,例如 kubernetes UI 组件?
- google-containers-ui IRC 频道,邮件列表。
- Tim: google-containers 前缀是历史的,应该只做 "kubernetes-ui"
- 也希望将设计资源投入使用,并且 bower 期望自己的仓库。
- 通用协议
3. Brian Grant:
- 测试 v1beta3,准备进入。
- Paul 致力于改变命令行的内容。
- 下周初至中旬,尝试默认启用v1beta3 ?
- 对于任何其他更改,请发出文件并抄送 thockin。
4. 一般认为30分钟比60分钟好
- 不应该为了填满时间而人为地延长。
Kubernetes 采集视频
如果你错过了上个月在旧金山举行的 Kubernetes 大会,不要害怕!以下是在 YouTube 上组织成播放列表的晚间演示文稿中的视频。

欢迎来到 Kubernetes 博客!
欢迎来到新的 Kubernetes 博客。关注此博客,了解 Kubernetes 开源项目。我们计划时不时的发布发布说明,操作方法文章,活动,甚至一些非常有趣的话题。
如果您正在使用 Kubernetes 或为该项目做出贡献并想要发帖子,请告诉我。
首先,以下是 Kubernetes 最近在其他网站上发布的文章摘要:
- 使用 Vitess 和 Kubernetes 在云中扩展 MySQL
- 虚拟机上的容器群集
- 想知道的关于 kubernetes 的一切,却又不敢问
- 什么构成容器集群?
- 将 OpenStack 和 Kubernetes 与 Murano 集成
- 容器介绍,Kubernetes 以及现代云计算的发展轨迹
- 什么是 Kubernetes 以及如何使用它?
- OpenShift V3,Docker 和 Kubernetes 策略
- Kubernetes 简介
快乐的云计算!
- Kit Merker - Google 云平台产品经理
作者标注:今天的邀请帖子是 Travis Newhouse 的 系列 中的第二部分,他是 AppFormix 的首席架构师,这篇文章介绍了他们对 Kubernetes 的贡献。
历史上,Kubernetes 测试一直由谷歌托管,在 谷歌计算引擎 (GCE) 和 谷歌容器引擎 (GKE) 上运行端到端测试。实际上,提交队列的选通检查是在这些测试平台上执行测试的子集。联合测试旨在通过使组织托管各种平台的测试作业并贡献测试结果,从而让 Kubernetes 项目受益来扩大测试范围。谷歌和 SIG-Testing 的 Kubernetes 测试小组成员已经创建了一个 Kubernetes 测试历史记录仪表板,可以发布所有联合测试作业(包括谷歌托管的作业)的全部结果。
在此博客文章中,我们介绍了扩展 Azure 的端到端测试工作,并展示了如何为 Kubernetes 项目贡献联合测试。
Azure 的端到端集成测试
成功实现 在 Azure 上自动部署 Kubernetes 的 “development distro” 脚本 之后,我们的下一个目标是运行端到端集成测试,并与 Kubernetes 社区共享结果。
通过在私有 Jenkins 服务器中定义夜间工作,我们自动化了在 Azure 上执行 Kubernetes 端到端测试的工作流程。图2显示了使用 kube-up.sh 在运行于 Azure 的 Ubuntu 虚拟机上部署 Kubernetes,然后执行端到端测试的工作流程。测试完成后,该作业将测试结果和日志上传到 Google Cloud Storage 目录中,其格式可以由 生成测试历史记录仪表板的脚本 进行处理。我们的 Jenkins 作业使用 hack/jenkins/e2e-runner.sh 和 hack/jenkins/upload-to-gcs.sh 脚本生成正确格式的结果。
| 
如何进行端到端测试
在创建 Azure 端到端测试工作的整个过程中,我们与 SIG-Testing 的成员进行了合作,找到了一种将结果发布到 Kubernetes 社区的方法。合作的结果是以文档和简化的流程从联合测试工作中贡献结果。贡献端到端测试结果的过程可以归纳为4个步骤。
- 创建一个 Google Cloud Storage 空间用来发布结果。
- 定义一个自动化作业来运行端到端测试,通过设置一些环境变量,使用 hack/jenkins/e2e-runner.sh 部署 Kubernetes 二进制文件并执行测试。
- 使用 hack/jenkins/upload-to-gcs.sh 上传结果。
- 通过提交对 kubernetes/test-infra 中的几个文件进行修改的请求,将结果合并到测试历史记录仪表板中。
联合测试文档更详细地描述了这些步骤。运行端到端测试并上传结果的脚本简化了贡献新联合测试作业的工作量。设置自动化测试作业的具体步骤以及在其中部署 Kubernetes 的合适环境将留给读者进行选择。对于使用 Jenkins 的组织,用于 GCE 和 GKE 测试的 jenkins-job-builder 配置可能会提供有用的示例。
回顾
Azure 上的端到端测试已经运行了几周。在此期间,我们在 Kubernetes 中发现了两个问题。Weixu Zhuang 立即发布了修补程序并已合并到 Kubernetes master 分支中。
当我们想用 Ubuntu VM 在 Azure 上用 SaltStack 打开 Kubernetes 集群时,发生了第一个问题。一个提交 (07d7cfd3) 修改了 OpenVPN 证书生成脚本,使用了一个仅由集群或者ubuntu中的脚本初始化的变量。证书生成脚本对参数是否存在进行严格检查会导致其他使用该脚本的平台失败(例如,为支持 Azure 而进行的更改)。我们提交了一个解决问题的请求 ,通过使用默认值初始化变量让证书生成脚本在所有平台类型上都更加健壮,。
第二个 清理未使用导入的请求 在 Daemonset 单元测试文件中。import 语句打破了 golang 1.4 的单元测试。我们的夜间 Jenkins 工作帮助我们找到错误并且迅速完成修复。
结论与未来工作
在 Azure 上为 Kubernetes 添加了夜间端到端测试工作,这有助于定义为 Kubernetes 项目贡献联合测试的过程。在工作过程中,当 Azure 测试工作发现兼容性问题时,我们还发现了将测试覆盖范围扩展到更多平台的直接好处。
我们要感谢 Aaron Crickenberger, Erick Fejta, Joe Finney 和 Ryan Hutchinson 的帮助,将我们的 Azure 端到端测试结果纳入了 Kubernetes 测试历史。如果您想参与测试来创建稳定的、高质量的 Kubernetes 版本,请加入我们的 Kubernetes Testing SIG (sig-testing)。
--Travis Newhouse, AppFormix 首席架构师