이 섹션의 다중 페이지 출력 화면임. 여기를 클릭하여 프린트.
클러스터 운영
- 1: kubeadm으로 관리하기
- 1.1: kubeadm을 사용한 인증서 관리
- 1.2: kubeadm 클러스터 업그레이드
- 1.3: 윈도우 노드 추가
- 1.4: 윈도우 노드 업그레이드
- 2: 메모리, CPU 와 API 리소스 관리
- 2.1: 네임스페이스에 대한 기본 메모리 요청량과 상한 구성
- 2.2: 네임스페이스에 대한 기본 CPU 요청량과 상한 구성
- 2.3: 네임스페이스에 대한 메모리의 최소 및 최대 제약 조건 구성
- 2.4: 네임스페이스에 대한 CPU의 최소 및 최대 제약 조건 구성
- 2.5: 네임스페이스에 대한 메모리 및 CPU 쿼터 구성
- 2.6: 네임스페이스에 대한 파드 쿼터 구성
- 3: 인증서
- 4: 네트워크 폴리시 제공자(Network Policy Provider) 설치
- 4.1: 네트워크 폴리시로 캘리코(Calico) 사용하기
- 4.2: 네트워크 폴리시로 실리움(Cilium) 사용하기
- 4.3: 네트워크 폴리시로 큐브 라우터(Kube-router) 사용하기
- 4.4: 네트워크 폴리시로 로마나(Romana)
- 4.5: 네트워크 폴리시로 위브넷(Weave Net) 사용하기
- 5: DNS 서비스 사용자 정의하기
- 6: 고가용성 쿠버네티스 클러스터 컨트롤 플레인 설정하기
- 7: 기본 스토리지클래스(StorageClass) 변경하기
- 8: 네트워크 폴리시(Network Policy) 선언하기
- 9: 노드에 대한 확장 리소스 알리기
- 10: 서비스 디스커버리를 위해 CoreDNS 사용하기
- 11: 중요한 애드온 파드 스케줄링 보장하기
- 12: 쿠버네티스 API 활성화 혹은 비활성화하기
- 13: 쿠버네티스 API를 사용하여 클러스터에 접근하기
- 14: 클러스터에서 실행되는 서비스에 접근
- 15: 토폴로지 인지 힌트 활성화하기
- 16: 퍼시스턴트볼륨 반환 정책 변경하기
1 - kubeadm으로 관리하기
1.1 - kubeadm을 사용한 인증서 관리
Kubernetes v1.15 [stable]
kubeadm으로 생성된 클라이언트 인증서는 1년 후에 만료된다. 이 페이지는 kubeadm으로 인증서 갱신을 관리하는 방법을 설명한다.
시작하기 전에
쿠버네티스의 PKI 인증서와 요구 조건에 익숙해야 한다.
사용자 정의 인증서 사용
기본적으로, kubeadm은 클러스터를 실행하는 데 필요한 모든 인증서를 생성한다. 사용자는 자체 인증서를 제공하여 이 동작을 무시할 수 있다.
이렇게 하려면, --cert-dir 플래그 또는 kubeadm ClusterConfiguration 의
certificatesDir 필드에 지정된 디렉터리에 배치해야 한다.
기본적으로 /etc/kubernetes/pki 이다.
kubeadm init 을 실행하기 전에 지정된 인증서와 개인 키(private key) 쌍이 존재하면,
kubeadm은 이를 덮어 쓰지 않는다. 이는 예를 들어, 기존 CA를
/etc/kubernetes/pki/ca.crt 와 /etc/kubernetes/pki/ca.key 에
복사할 수 있고, kubeadm은 이 CA를 사용하여 나머지 인증서에 서명한다는 걸 의미한다.
외부 CA 모드
ca.key 파일이 아닌 ca.crt 파일만 제공할
수도 있다(이는 다른 인증서 쌍이 아닌 루트 CA 파일에만 사용 가능함).
다른 모든 인증서와 kubeconfig 파일이 있으면, kubeadm은 이 조건을
인식하고 "외부 CA" 모드를 활성화한다. kubeadm은 디스크에
CA 키없이 진행한다.
대신, --controllers=csrsigner 사용하여 controller-manager를
독립적으로 실행하고 CA 인증서와 키를 가리킨다.
PKI 인증서와 요구 조건은 외부 CA를 사용하도록 클러스터 설정에 대한 지침을 포함한다.
인증서 만료 확인
check-expiration 하위 명령을 사용하여 인증서가 만료되는 시기를 확인할 수 있다.
kubeadm certs check-expiration
출력 결과는 다음과 비슷하다.
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Dec 30, 2020 23:36 UTC 364d no
apiserver Dec 30, 2020 23:36 UTC 364d ca no
apiserver-etcd-client Dec 30, 2020 23:36 UTC 364d etcd-ca no
apiserver-kubelet-client Dec 30, 2020 23:36 UTC 364d ca no
controller-manager.conf Dec 30, 2020 23:36 UTC 364d no
etcd-healthcheck-client Dec 30, 2020 23:36 UTC 364d etcd-ca no
etcd-peer Dec 30, 2020 23:36 UTC 364d etcd-ca no
etcd-server Dec 30, 2020 23:36 UTC 364d etcd-ca no
front-proxy-client Dec 30, 2020 23:36 UTC 364d front-proxy-ca no
scheduler.conf Dec 30, 2020 23:36 UTC 364d no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Dec 28, 2029 23:36 UTC 9y no
etcd-ca Dec 28, 2029 23:36 UTC 9y no
front-proxy-ca Dec 28, 2029 23:36 UTC 9y no
이 명령은 /etc/kubernetes/pki 폴더의 클라이언트 인증서와 kubeadm이 사용하는 KUBECONFIG 파일(admin.conf, controller-manager.conf 및 scheduler.conf)에 포함된 클라이언트 인증서의 만료/잔여 기간을 표시한다.
또한, kubeadm은 인증서가 외부에서 관리되는지를 사용자에게 알린다. 이 경우 사용자는 수동으로 또는 다른 도구를 사용해서 인증서 갱신 관리를 해야 한다.
kubeadm 은 외부 CA가 서명한 인증서를 관리할 수 없다.
kubelet.conf 는 위 목록에 포함되어 있지 않은데, 이는
kubeadm이 자동 인증서 갱신을 위해
/var/lib/kubelet/pki에 있는 갱신 가능한 인증서를 이용하여 kubelet을 구성하기 때문이다.
만료된 kubelet 클라이언트 인증서를 갱신하려면
kubelet 클라이언트 갱신 실패 섹션을 확인한다.
kubeadm 1.17 이전의 버전에서 kubeadm init 으로 작성된 노드에는
kubelet.conf 의 내용을 수동으로 수정해야 하는 버그가 있다. kubeadm init 수행 완료 후, client-certificate-data 및 client-key-data 를 다음과 같이 교체하여,
로테이트된 kubelet 클라이언트 인증서를 가리키도록 kubelet.conf 를 업데이트해야 한다.
client-certificate: /var/lib/kubelet/pki/kubelet-client-current.pem
client-key: /var/lib/kubelet/pki/kubelet-client-current.pem
자동 인증서 갱신
kubeadm은 컨트롤 플레인 업그레이드 동안 모든 인증서를 갱신한다.
이 기능은 가장 간단한 유스케이스를 해결하기 위해 설계되었다. 인증서 갱신에 대해 특별한 요구 사항이 없고 쿠버네티스 버전 업그레이드를 정기적으로(매 1년 이내 업그레이드 수행) 수행하는 경우, kubeadm은 클러스터를 최신 상태로 유지하고 합리적으로 보안을 유지한다.
인증서 갱신에 대해 보다 복잡한 요구 사항이 있는 경우, --certificate-renewal=false 를 kubeadm upgrade apply 또는 kubeadm upgrade node 와 함께 사용하여 기본 동작이 수행되지 않도록 할 수 있다.
kubeadm upgrade node 명령에서
--certificate-renewal 의 기본값이 false 인 버그가
있다. 이 경우 --certificate-renewal=true 를 명시적으로 설정해야 한다.
수동 인증서 갱신
kubeadm certs renew 명령을 사용하여 언제든지 인증서를 수동으로 갱신할 수 있다.
이 명령은 /etc/kubernetes/pki 에 저장된 CA(또는 프론트 프록시 CA) 인증서와 키를 사용하여 갱신을 수행한다.
명령을 실행한 후에는 컨트롤 플레인 파드를 재시작해야 한다.
이는 현재 일부 구성 요소 및 인증서에 대해 인증서를 동적으로 다시 로드하는 것이 지원되지 않기 때문이다.
스태틱(static) 파드는 API 서버가 아닌 로컬 kubelet에서 관리되므로
kubectl을 사용하여 삭제 및 재시작할 수 없다.
스태틱 파드를 다시 시작하려면 /etc/kubernetes/manifests/에서 매니페스트 파일을 일시적으로 제거하고
20초를 기다리면 된다 (KubeletConfiguration struct의 fileCheckFrequency 값을 참고한다).
파드가 매니페스트 디렉터리에 더 이상 없는 경우 kubelet은 파드를 종료한다.
그런 다음 파일을 다시 이동할 수 있으며 또 다른 fileCheckFrequency 기간이 지나면,
kubelet은 파드를 생성하고 구성 요소에 대한 인증서 갱신을 완료할 수 있다.
certs renew 는 기존 인증서를 kubeadm-config 컨피그맵(ConfigMap) 대신 속성(공통 이름, 조직, SAN 등)의 신뢰할 수 있는 소스로 사용한다. 둘 다 동기화 상태를 유지하는 것을 강력히 권장한다.
kubeadm certs renew 는 다음의 옵션을 제공한다.
쿠버네티스 인증서는 일반적으로 1년 후 만료일에 도달한다.
-
--csr-only는 실제로 인증서를 갱신하지 않고 인증서 서명 요청을 생성하여 외부 CA로 인증서를 갱신하는 데 사용할 수 있다. 자세한 내용은 다음 단락을 참고한다. -
모든 인증서 대신 단일 인증서를 갱신할 수도 있다.
쿠버네티스 인증서 API를 사용하여 인증서 갱신
이 섹션에서는 쿠버네티스 인증서 API를 사용하여 수동 인증서 갱신을 실행하는 방법에 대한 자세한 정보를 제공한다.
서명자 설정
쿠버네티스 인증 기관(Certificate Authority)은 기본적으로 작동하지 않는다. cert-manager와 같은 외부 서명자를 설정하거나, 빌트인 서명자를 사용할 수 있다.
빌트인 서명자는 kube-controller-manager의 일부이다.
빌트인 서명자를 활성화하려면, --cluster-signing-cert-file 와 --cluster-signing-key-file 플래그를 전달해야 한다.
새 클러스터를 생성하는 경우, kubeadm 구성 파일을 사용할 수 있다.
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
controllerManager:
extraArgs:
cluster-signing-cert-file: /etc/kubernetes/pki/ca.crt
cluster-signing-key-file: /etc/kubernetes/pki/ca.key
인증서 서명 요청(CSR) 생성
쿠버네티스 API로 CSR을 작성하려면 CertificateSigningRequest 생성을 본다.
외부 CA로 인증서 갱신
이 섹션에서는 외부 CA를 사용하여 수동 인증서 갱신을 실행하는 방법에 대한 자세한 정보를 제공한다.
외부 CA와 보다 효과적으로 통합하기 위해 kubeadm은 인증서 서명 요청(CSR)을 생성할 수도 있다. CSR은 클라이언트의 서명된 인증서에 대한 CA 요청을 나타낸다. kubeadm 관점에서, 일반적으로 온-디스크(on-disk) CA에 의해 서명되는 모든 인증서는 CSR로 생성될 수 있다. 그러나 CA는 CSR로 생성될 수 없다.
인증서 서명 요청(CSR) 생성
kubeadm certs renew --csr-only 로 인증서 서명 요청을 만들 수 있다.
CSR과 함께 제공되는 개인 키가 모두 출력된다.
--csr-dir 로 사용할 디텍터리를 전달하여 지정된 위치로 CSR을 출력할 수 있다.
--csr-dir 을 지정하지 않으면, 기본 인증서 디렉터리(/etc/kubernetes/pki)가 사용된다.
kubeadm certs renew --csr-only 로 인증서를 갱신할 수 있다.
kubeadm init 과 마찬가지로 출력 디렉터리를 --csr-dir 플래그로 지정할 수 있다.
CSR에는 인증서 이름, 도메인 및 IP가 포함되지만, 용도를 지정하지는 않는다. 인증서를 발행할 때 올바른 인증서 용도를 지정하는 것은 CA의 책임이다.
openssl의 경우openssl ca명령으로 수행한다.cfssl의 경우 설정 파일에 용도를 지정한다.
선호하는 방법으로 인증서에 서명한 후, 인증서와 개인 키를 PKI 디렉터리(기본적으로 /etc/kubernetes/pki)에 복사해야 한다.
인증 기관(CA) 순환(rotation)
Kubeadm은 CA 인증서의 순환이나 교체 기능을 기본적으로 지원하지 않는다.
CA의 수동 순환이나 교체에 대한 보다 상세한 정보는 CA 인증서 수동 순환 문서를 참조한다.
서명된 kubelet 인증서 활성화하기
기본적으로 kubeadm에 의해서 배포된 kubelet 인증서는 자가 서명된(self-signed) 것이다. 이것은 metrics-server와 같은 외부 서비스의 kubelet에 대한 연결은 TLS로 보안되지 않음을 의미한다.
제대로 서명된 인증서를 얻기 위해서 신규 kubeadm 클러스터의 kubelet을 구성하려면
다음의 최소 구성을 kubeadm init 에 전달해야 한다.
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
serverTLSBootstrap: true
만약 이미 클러스터를 생성했다면 다음을 따라 이를 조정해야 한다.
kube-system네임스페이스에서kubelet-config-1.22컨피그맵을 찾아서 수정한다. 해당 컨피그맵에는kubelet키가 KubeletConfiguration 문서를 값으로 가진다.serverTLSBootstrap: true가 되도록 KubeletConfiguration 문서를 수정한다.- 각 노드에서,
serverTLSBootstrap: true필드를/var/lib/kubelet/config.yaml에 추가한다. 그리고systemctl restart kubelet로 kubelet을 재시작한다.
serverTLSBootstrap: true 필드는 kubelet 인증서를 이용한 부트스트랩을
certificates.k8s.io API에 요청함으로써 활성화할 것이다. 한 가지 알려진 제약은
이 인증서들에 대한 CSR(인증서 서명 요청)들이 kube-controller-manager -
kubernetes.io/kubelet-serving의
기본 서명자(default signer)에 의해서 자동으로 승인될 수 없다는 점이다.
이것은 사용자나 제 3의 컨트롤러의 액션을 필요로 할 것이다.
이 CSR들은 다음을 통해 볼 수 있다.
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-9wvgt 112s kubernetes.io/kubelet-serving system:node:worker-1 Pending
csr-lz97v 1m58s kubernetes.io/kubelet-serving system:node:control-plane-1 Pending
이를 승인하기 위해서는 다음을 수행한다.
kubectl certificate approve <CSR-name>
기본적으로, 이 인증서는 1년 후에 만기될 것이다. Kubeadm은
KubeletConfiguration 필드의 rotateCertificates 를 true 로 설정한다. 이것은 만기가
다가오면 인증서를 위한 신규 CSR 세트가 생성되는 것을 의미하며,
해당 순환(rotation)을 완료하기 위해서는 승인이 되어야 한다는 것을 의미한다. 더 상세한 이해를 위해서는
인증서 순환를 확인한다.
만약 이 CSR들의 자동 승인을 위한 솔루션을 찾고 있다면 클라우드 제공자와 연락하여 대역 외 메커니즘(out of band mechanism)을 통해 노드의 신분을 검증할 수 있는 CSR 서명자를 가지고 있는지 문의하는 것을 추천한다.
제 3 자 커스텀 컨트롤러도 사용될 수 있다.
이러한 컨트롤러는 CSR의 CommonName과 요청된 IPs 및 도메인 네임을 모두 검증하지 않는 한, 보안이 되는 메커니즘이 아니다. 이것을 통해 악의적 행위자가 kubelet 인증서(클라이언트 인증)를 사용하여 아무 IP나 도메인 네임에 대해 인증서를 요청하는 CSR의 생성을 방지할 수 있을 것이다.
1.2 - kubeadm 클러스터 업그레이드
이 페이지는 kubeadm으로 생성된 쿠버네티스 클러스터를
1.21.x 버전에서 1.22.x 버전으로,
1.22.x 버전에서 1.22.y(여기서 y > x) 버전으로 업그레이드하는 방법을 설명한다. 업그레이드가 지원되지 않는 경우
마이너 버전을 건너뛴다.
이전 버전의 kubeadm을 사용하여 생성된 클러스터 업그레이드에 대한 정보를 보려면, 이 페이지 대신 다음의 페이지들을 참고한다.
- kubeadm 클러스터를 1.20에서 1.21로 업그레이드
- kubeadm 클러스터를 1.19에서 1.20로 업그레이드
- kubeadm 클러스터를 1.18에서 1.19로 업그레이드
- kubeadm 클러스터를 1.17에서 1.18으로 업그레이드
추상적인 업그레이드 작업 절차는 다음과 같다.
- 기본 컨트롤 플레인 노드를 업그레이드한다.
- 추가 컨트롤 플레인 노드를 업그레이드한다.
- 워커(worker) 노드를 업그레이드한다.
시작하기 전에
- 릴리스 노트를 주의 깊게 읽어야 한다.
- 클러스터는 정적 컨트롤 플레인 및 etcd 파드 또는 외부 etcd를 사용해야 한다.
- 데이터베이스에 저장된 앱-레벨 상태와 같은 중요한 컴포넌트를 반드시 백업한다.
kubeadm upgrade는 워크로드에 영향을 미치지 않고, 쿠버네티스 내부의 컴포넌트만 다루지만, 백업은 항상 모범 사례일 정도로 중요하다. - 스왑을 비활성화해야 한다.
추가 정보
- kubelet 마이너 버전을 업그레이드하기 전에 노드 드레이닝(draining)이 필요하다. 컨트롤 플레인 노드의 경우 CoreDNS 파드 또는 기타 중요한 워크로드를 실행할 수 있다.
- 컨테이너 사양 해시 값이 변경되므로, 업그레이드 후 모든 컨테이너가 다시 시작된다.
업그레이드할 버전 결정
OS 패키지 관리자를 사용하여 최신의 안정 버전(1.22)을 찾는다.
apt update
apt-cache madison kubeadm
# 목록에서 최신 버전(1.22)을 찾는다
# 1.22.x-00과 같아야 한다. 여기서 x는 최신 패치이다.
yum list --showduplicates kubeadm --disableexcludes=kubernetes
# 목록에서 최신 버전(1.22)을 찾는다
# 1.22.x-0과 같아야 한다. 여기서 x는 최신 패치이다.
컨트롤 플레인 노드 업그레이드
컨트롤 플레인 노드의 업그레이드 절차는 한 번에 한 노드씩 실행해야 한다.
먼저 업그레이드할 컨트롤 플레인 노드를 선택한다. /etc/kubernetes/admin.conf 파일이 있어야 한다.
"kubeadm upgrade" 호출
첫 번째 컨트롤 플레인 노드의 경우
- kubeadm 업그레이드
# 1.22.x-00에서 x를 최신 패치 버전으로 바꾼다.
apt-mark unhold kubeadm && \
apt-get update && apt-get install -y kubeadm=1.22.x-00 && \
apt-mark hold kubeadm
-
# apt-get 버전 1.1부터 다음 방법을 사용할 수도 있다
apt-get update && \
apt-get install -y --allow-change-held-packages kubeadm=1.22.x-00
# 1.22.x-0에서 x를 최신 패치 버전으로 바꾼다.
yum install -y kubeadm-1.22.x-0 --disableexcludes=kubernetes
-
다운로드하려는 버전이 잘 받아졌는지 확인한다.
kubeadm version -
업그레이드 계획을 확인한다.
kubeadm upgrade plan이 명령은 클러스터를 업그레이드할 수 있는지를 확인하고, 업그레이드할 수 있는 버전을 가져온다. 또한 컴포넌트 구성 버전 상태가 있는 표를 보여준다.
kubeadm upgrade 는 이 노드에서 관리하는 인증서를 자동으로 갱신한다.
인증서 갱신을 하지 않으려면 --certificate-renewal=false 플래그를 사용할 수 있다.
자세한 내용은 인증서 관리 가이드를 참고한다.
kubeadm upgrade plan 이 수동 업그레이드가 필요한 컴포넌트 구성을 표시하는 경우, 사용자는
--config 커맨드 라인 플래그를 통해 대체 구성이 포함된 구성 파일을 kubeadm upgrade apply 에 제공해야 한다.
그렇게 하지 않으면 kubeadm upgrade apply 가 오류와 함께 종료되고 업그레이드를 수행하지 않는다.
-
업그레이드할 버전을 선택하고, 적절한 명령을 실행한다. 예를 들면 다음과 같다.
# 이 업그레이드를 위해 선택한 패치 버전으로 x를 바꾼다. sudo kubeadm upgrade apply v1.22.x명령이 완료되면 다음을 확인해야 한다.
[upgrade/successful] SUCCESS! Your cluster was upgraded to "v1.22.x". Enjoy! [upgrade/kubelet] Now that your control plane is upgraded, please proceed with upgrading your kubelets if you haven't already done so. -
CNI 제공자 플러그인을 수동으로 업그레이드한다.
CNI(컨테이너 네트워크 인터페이스) 제공자는 자체 업그레이드 지침을 따를 수 있다. 애드온 페이지에서 사용하는 CNI 제공자를 찾고 추가 업그레이드 단계가 필요한지 여부를 확인한다.
CNI 제공자가 데몬셋(DaemonSet)으로 실행되는 경우 추가 컨트롤 플레인 노드에는 이 단계가 필요하지 않다.
다른 컨트롤 플레인 노드의 경우
첫 번째 컨트롤 플레인 노드와 동일하지만 다음을 사용한다.
sudo kubeadm upgrade node
아래 명령 대신 위의 명령을 사용한다.
sudo kubeadm upgrade apply
kubeadm upgrade plan 을 호출하고 CNI 공급자 플러그인을 업그레이드할 필요가 없다.
노드 드레인
-
Prepare the node for maintenance by marking it unschedulable and evicting the workloads:
# <node-to-drain>을 드레인하는 노드의 이름으로 바꾼다. kubectl drain <node-to-drain> --ignore-daemonsets
kubelet과 kubectl 업그레이드
- 모든 컨트롤 플레인 노드에서 kubelet 및 kubectl을 업그레이드한다.
>
# 1.22.x-00의 x를 최신 패치 버전으로 바꾼다
apt-mark unhold kubelet kubectl && \
apt-get update && apt-get install -y kubelet=1.22.x-00 kubectl=1.22.x-00 && \
apt-mark hold kubelet kubectl
-
# apt-get 버전 1.1부터 다음 방법을 사용할 수도 있다
apt-get update && \
apt-get install -y --allow-change-held-packages kubelet=1.22.x-00 kubectl=1.22.x-00
# 1.22.x-0에서 x를 최신 패치 버전으로 바꾼다
yum install -y kubelet-1.22.x-0 kubectl-1.22.x-0 --disableexcludes=kubernetes
- kubelet을 다시 시작한다.
sudo systemctl daemon-reload
sudo systemctl restart kubelet
노드 uncordon
-
노드를 스케줄 가능으로 표시하여 노드를 다시 온라인 상태로 전환한다.
# <node-to-drain>을 드레인하는 노드의 이름으로 바꾼다. kubectl uncordon <node-to-drain>
워커 노드 업그레이드
워커 노드의 업그레이드 절차는 워크로드를 실행하는 데 필요한 최소 용량을 보장하면서, 한 번에 하나의 노드 또는 한 번에 몇 개의 노드로 실행해야 한다.
kubeadm 업그레이드
- 모든 워커 노드에서 kubeadm을 업그레이드한다.
# 1.22.x-00의 x를 최신 패치 버전으로 바꾼다
apt-mark unhold kubeadm && \
apt-get update && apt-get install -y kubeadm=1.22.x-00 && \
apt-mark hold kubeadm
-
# apt-get 버전 1.1부터 다음 방법을 사용할 수도 있다
apt-get update && \
apt-get install -y --allow-change-held-packages kubeadm=1.22.x-00
# 1.22.x-0에서 x를 최신 패치 버전으로 바꾼다
yum install -y kubeadm-1.22.x-0 --disableexcludes=kubernetes
"kubeadm upgrade" 호출
-
워커 노드의 경우 로컬 kubelet 구성을 업그레이드한다.
sudo kubeadm upgrade node
노드 드레인
-
스케줄 불가능(unschedulable)으로 표시하고 워크로드를 축출하여 유지 보수할 노드를 준비한다.
# <node-to-drain>을 드레이닝하려는 노드 이름으로 바꾼다. kubectl drain <node-to-drain> --ignore-daemonsets
kubelet과 kubectl 업그레이드
- kubelet 및 kubectl을 업그레이드한다.
# 1.22.x-00의 x를 최신 패치 버전으로 바꾼다
apt-mark unhold kubelet kubectl && \
apt-get update && apt-get install -y kubelet=1.22.x-00 kubectl=1.22.x-00 && \
apt-mark hold kubelet kubectl
-
# apt-get 버전 1.1부터 다음 방법을 사용할 수도 있다
apt-get update && \
apt-get install -y --allow-change-held-packages kubelet=1.22.x-00 kubectl=1.22.x-00
# 1.22.x-0에서 x를 최신 패치 버전으로 바꾼다
yum install -y kubelet-1.22.x-0 kubectl-1.22.x-0 --disableexcludes=kubernetes
-
kubelet을 다시 시작한다.
sudo systemctl daemon-reload sudo systemctl restart kubelet
노드에 적용된 cordon 해제
-
스케줄 가능(schedulable)으로 표시하여 노드를 다시 온라인 상태로 만든다.
# <node-to-drain>을 노드의 이름으로 바꾼다. kubectl uncordon <node-to-drain>
클러스터 상태 확인
모든 노드에서 kubelet을 업그레이드한 후 kubectl이 클러스터에 접근할 수 있는 곳에서 다음의 명령을 실행하여 모든 노드를 다시 사용할 수 있는지 확인한다.
kubectl get nodes
모든 노드에 대해 STATUS 열에 Ready 가 표시되어야 하고, 버전 번호가 업데이트되어 있어야 한다.
장애 상태에서의 복구
예를 들어 kubeadm upgrade 를 실행하는 중에 예기치 못한 종료로 인해 업그레이드가 실패하고 롤백하지 않는다면, kubeadm upgrade 를 다시 실행할 수 있다.
이 명령은 멱등성을 보장하며 결국 실제 상태가 선언한 의도한 상태인지 확인한다.
잘못된 상태에서 복구하기 위해, 클러스터가 실행 중인 버전을 변경하지 않고 kubeadm upgrade apply --force 를 실행할 수도 있다.
업그레이드하는 동안 kubeadm은 /etc/kubernetes/tmp 아래에 다음과 같은 백업 폴더를 작성한다.
kubeadm-backup-etcd-<date>-<time>kubeadm-backup-manifests-<date>-<time>
kubeadm-backup-etcd 는 컨트롤 플레인 노드에 대한 로컬 etcd 멤버 데이터의 백업을 포함한다.
etcd 업그레이드가 실패하고 자동 롤백이 작동하지 않으면, 이 폴더의 내용을
/var/lib/etcd 에서 수동으로 복원할 수 있다. 외부 etcd를 사용하는 경우 이 백업 폴더는 비어있다.
kubeadm-backup-manifests 는 컨트롤 플레인 노드에 대한 정적 파드 매니페스트 파일의 백업을 포함한다.
업그레이드가 실패하고 자동 롤백이 작동하지 않으면, 이 폴더의 내용을
/etc/kubernetes/manifests 에서 수동으로 복원할 수 있다. 어떤 이유로 특정 컴포넌트의 업그레이드 전
매니페스트 파일과 업그레이드 후 매니페스트 파일 간에 차이가 없는 경우, 백업 파일은 기록되지 않는다.
작동 원리
kubeadm upgrade apply 는 다음을 수행한다.
- 클러스터가 업그레이드 가능한 상태인지 확인한다.
- API 서버에 접근할 수 있다
- 모든 노드가
Ready상태에 있다 - 컨트롤 플레인이 정상적으로 동작한다
- 버전 차이(skew) 정책을 적용한다.
- 컨트롤 플레인 이미지가 사용 가능한지 또는 머신으로 가져올 수 있는지 확인한다.
- 컴포넌트 구성에 버전 업그레이드가 필요한 경우 대체 구성을 생성하거나 사용자가 제공한 것으로 덮어 쓰기한다.
- 컨트롤 플레인 컴포넌트 또는 롤백 중 하나라도 나타나지 않으면 업그레이드한다.
- 새로운
CoreDNS와kube-proxy매니페스트를 적용하고 필요한 모든 RBAC 규칙이 생성되도록 한다. - API 서버의 새 인증서와 키 파일을 작성하고 180일 후에 만료될 경우 이전 파일을 백업한다.
kubeadm upgrade node 는 추가 컨트롤 플레인 노드에서 다음을 수행한다.
- 클러스터에서 kubeadm
ClusterConfiguration을 가져온다. - 선택적으로 kube-apiserver 인증서를 백업한다.
- 컨트롤 플레인 컴포넌트에 대한 정적 파드 매니페스트를 업그레이드한다.
- 이 노드의 kubelet 구성을 업그레이드한다.
kubeadm upgrade node 는 워커 노드에서 다음을 수행한다.
- 클러스터에서 kubeadm
ClusterConfiguration을 가져온다. - 이 노드의 kubelet 구성을 업그레이드한다.
1.3 - 윈도우 노드 추가
Kubernetes v1.18 [beta]
쿠버네티스를 사용하여 리눅스와 윈도우 노드를 혼합하여 실행할 수 있으므로, 리눅스에서 실행되는 파드와 윈도우에서 실행되는 파드를 혼합할 수 있다. 이 페이지는 윈도우 노드를 클러스터에 등록하는 방법을 보여준다.
시작하기 전에
쿠버네티스 서버의 버전은 다음과 같거나 더 높아야 함. 버전: 1.17. 버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
-
윈도우 컨테이너를 호스팅하는 윈도우 노드를 구성하려면 윈도우 서버 2019 라이선스 이상이 필요하다. VXLAN/오버레이 네트워킹을 사용하는 경우 KB4489899도 설치되어 있어야 한다.
-
컨트롤 플레인에 접근할 수 있는 리눅스 기반의 쿠버네티스 kubeadm 클러스터(kubeadm을 사용하여 단일 컨트롤 플레인 클러스터 생성 참고)가 필요하다.
목적
- 클러스터에 윈도우 노드 등록
- 리눅스 및 윈도우의 파드와 서비스가 서로 통신할 수 있도록 네트워킹 구성
시작하기: 클러스터에 윈도우 노드 추가
네트워킹 구성
리눅스 기반 쿠버네티스 컨트롤 플레인 노드가 있으면 네트워킹 솔루션을 선택할 수 있다. 이 가이드는 VXLAN 모드의 플란넬(Flannel)을 사용하는 방법을 짧막하게 보여준다.
플란넬 구성
-
플란넬을 위한 쿠버네티스 컨트롤 플레인 준비
클러스터의 쿠버네티스 컨트롤 플레인에서 약간의 준비가 필요하다. 플란넬을 사용할 때 iptables 체인에 브릿지된 IPv4 트래픽을 활성화하는 것을 권장한다. 아래 명령을 모든 리눅스 노드에서 실행해야만 한다.
sudo sysctl net.bridge.bridge-nf-call-iptables=1 -
리눅스용 플란넬 다운로드 및 구성
가장 최근의 플란넬 매니페스트를 다운로드한다.
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.ymlVNI를 4096으로 설정하고 포트를 4789로 설정하려면 플란넬 매니페스트의
net-conf.json섹션을 수정한다. 다음과 같을 것이다.net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "vxlan", "VNI": 4096, "Port": 4789 } }참고: 리눅스의 플란넬이 윈도우의 플란넬과 상호 운용되도록 하려면 VNI를 4096으로, 포트를 4789로 설정해야 한다. 이 필드들에 대한 설명은 VXLAN 문서를 참고한다.참고: L2Bridge/Host-gateway 모드를 대신 사용하려면Type의 값을"host-gw"로 변경하고VNI와Port를 생략한다. -
플란넬 매니페스트 적용 및 유효성 검사
플란넬 구성을 적용해보자.
kubectl apply -f kube-flannel.yml몇 분 후에, 플란넬 파드 네트워크가 배포되었다면 모든 파드가 실행 중인 것으로 표시된다.
kubectl get pods -n kube-system출력 결과에 리눅스 flannel 데몬셋(DaemonSet)이 실행 중인 것으로 나와야 한다.
NAMESPACE NAME READY STATUS RESTARTS AGE ... kube-system kube-flannel-ds-54954 1/1 Running 0 1m -
윈도우 플란넬 및 kube-proxy 데몬셋 추가
이제 윈도우 호환 버전의 플란넬과 kube-proxy를 추가할 수 있다. 호환 가능한 kube-proxy 버전을 얻으려면, 이미지의 태그를 대체해야 한다. 다음의 예시는 쿠버네티스 v1.22.0의 사용법을 보여주지만, 사용자의 배포에 맞게 버전을 조정해야 한다.
curl -L https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/kube-proxy.yml | sed 's/VERSION/v1.22.0/g' | kubectl apply -f - kubectl apply -f https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/flannel-overlay.yml참고: host-gateway를 사용하는 경우 https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/flannel-host-gw.yml 을 대신 사용한다.참고:윈도우 노드에서 이더넷이 아닌 다른 인터페이스(예: "Ethernet0 2")를 사용하는 경우, flannel-host-gw.yml이나 flannel-overlay.yml 파일에서 다음 라인을 수정한다.
wins cli process run --path /k/flannel/setup.exe --args "--mode=overlay --interface=Ethernet"그리고, 이에 따라 인터페이스를 지정해야 한다.
# 예시 curl -L https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/flannel-overlay.yml | sed 's/Ethernet/Ethernet0 2/g' | kubectl apply -f -
윈도우 워커 노드 조인(joining)
Docker EE 설치
컨테이너 기능 설치
Install-WindowsFeature -Name containers
도커 설치 자세한 내용은 도커 엔진 설치 - 윈도우 서버 엔터프라이즈에서 확인할 수 있다.
wins, kubelet 및 kubeadm 설치
curl.exe -LO https://raw.githubusercontent.com/kubernetes-sigs/sig-windows-tools/master/kubeadm/scripts/PrepareNode.ps1
.\PrepareNode.ps1 -KubernetesVersion v1.22.0
kubeadm 실행하여 노드에 조인
컨트롤 플레인 호스트에서 kubeadm init 실행할 때 제공된 명령을 사용한다.
이 명령이 더 이상 없거나, 토큰이 만료된 경우, kubeadm token create --print-join-command
(컨트롤 플레인 호스트에서)를 실행하여 새 토큰 및 조인 명령을 생성할 수 있다.
containerD 설치
curl.exe -LO https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/Install-Containerd.ps1
.\Install-Containerd.ps1
특정 버전의 containerD를 설치하려면 -ContainerDVersion를 사용하여 버전을 지정한다.
# 예
.\Install-Containerd.ps1 -ContainerDVersion 1.4.1
윈도우 노드에서 이더넷(예: "Ethernet0 2")이 아닌 다른 인터페이스를 사용하는 경우, -netAdapterName 으로 이름을 지정한다.
# 예
.\Install-Containerd.ps1 -netAdapterName "Ethernet0 2"
wins, kubelet 및 kubeadm 설치
curl.exe -LO https://raw.githubusercontent.com/kubernetes-sigs/sig-windows-tools/master/kubeadm/scripts/PrepareNode.ps1
.\PrepareNode.ps1 -KubernetesVersion v1.22.0 -ContainerRuntime containerD
kubeadm 실행하여 노드에 조인
컨트롤 플레인 호스트에서 `kubeadm init` 실행할 때 제공된 명령을 사용한다.
이 명령이 더 이상 없거나, 토큰이 만료된 경우, `kubeadm token create --print-join-command`
(컨트롤 플레인 호스트에서)를 실행하여 새 토큰 및 조인 명령을 생성할 수 있다.
--cri-socket "npipe:////./pipe/containerd-containerd" 를 추가한다
설치 확인
이제 다음을 실행하여 클러스터에서 윈도우 노드를 볼 수 있다.
kubectl get nodes -o wide
새 노드가 NotReady 상태인 경우 플란넬 이미지가 여전히 다운로드 중일 수 있다.
kube-system 네임스페이스에서 flannel 파드를 확인하여 이전과 같이 진행 상황을 확인할 수 있다.
kubectl -n kube-system get pods -l app=flannel
flannel 파드가 실행되면, 노드는 Ready 상태가 되고 워크로드를 처리할 수 있어야 한다.
다음 내용
1.4 - 윈도우 노드 업그레이드
Kubernetes v1.18 [beta]
이 페이지는 kubeadm으로 생성된 윈도우 노드를 업그레이드하는 방법을 설명한다.
시작하기 전에
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다. 만약, 아직 클러스터를 가지고 있지 않다면, minikube를 사용해서 생성하거나 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
쿠버네티스 서버의 버전은 다음과 같거나 더 높아야 함. 버전: 1.17. 버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
- 남은 kubeadm 클러스터를 업그레이드하는 프로세스에 익숙해져야 한다. 윈도우 노드를 업그레이드하기 전에 컨트롤 플레인 노드를 업그레이드해야 한다.
워커 노드 업그레이드
kubeadm 업그레이드
-
윈도우 노드에서, kubeadm을 업그레이드한다.
# replace v1.22.0 with your desired version curl.exe -Lo C:\k\kubeadm.exe https://dl.k8s.io//bin/windows/amd64/kubeadm.exe
노드 드레인
-
쿠버네티스 API에 접근할 수 있는 머신에서, 스케줄 불가능한 것으로 표시하고 워크로드를 축출하여 유지 보수할 노드를 준비한다.
# <node-to-drain>을 드레이닝하려는 노드 이름으로 바꾼다 kubectl drain <node-to-drain> --ignore-daemonsets다음과 비슷한 출력이 표시되어야 한다.
node/ip-172-31-85-18 cordoned node/ip-172-31-85-18 drained
kubelet 구성 업그레이드
-
윈도우 노드에서, 다음의 명령을 호출하여 새 kubelet 구성을 동기화한다.
kubeadm upgrade node
kubelet 업그레이드
-
윈도우 노드에서, kubelet을 업그레이드하고 다시 시작한다.
stop-service kubelet curl.exe -Lo C:\k\kubelet.exe https://dl.k8s.io//bin/windows/amd64/kubelet.exe restart-service kubelet
노드에 적용된 cordon 해제
-
쿠버네티스 API에 접근할 수 있는 머신에서, 스케줄 가능으로 표시하여 노드를 다시 온라인으로 가져온다.
# <node-to-drain>을 노드의 이름으로 바꾼다 kubectl uncordon <node-to-drain>
kube-proxy 업그레이드
-
쿠버네티스 API에 접근할 수 있는 머신에서, 다음을 실행하여, v1.22.0을 원하는 버전으로 다시 바꾼다.
curl -L https://github.com/kubernetes-sigs/sig-windows-tools/releases/latest/download/kube-proxy.yml | sed 's/VERSION/v1.22.0/g' | kubectl apply -f -
2 - 메모리, CPU 와 API 리소스 관리
2.1 - 네임스페이스에 대한 기본 메모리 요청량과 상한 구성
이 페이지는 네임스페이스에 대한 기본 메모리 요청량(request)과 상한(limit)을 구성하는 방법을 보여준다. 기본 메모리 상한이 있는 네임스페이스에서 컨테이너가 생성되고, 컨테이너가 자체 메모리 상한을 지정하지 않으면, 컨테이너에 기본 메모리 상한이 할당된다. 쿠버네티스는 이 문서의 뒷부분에서 설명하는 특정 조건에서 기본 메모리 요청량을 할당한다.
시작하기 전에
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다. 만약, 아직 클러스터를 가지고 있지 않다면, minikube를 사용해서 생성하거나 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
클러스터의 각 노드에는 최소 2GiB의 메모리가 있어야 한다.
네임스페이스 생성
이 연습에서 생성한 리소스가 클러스터의 다른 리소스와 격리되도록 네임스페이스를 생성한다.
kubectl create namespace default-mem-example
리밋레인지(LimitRange)와 파드 생성
다음은 리밋레인지 오브젝트의 구성 파일이다. 구성은 메모리 요청량 기본값(default)과 메모리 상한 기본값을 지정한다.

apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default:
memory: 512Mi
defaultRequest:
memory: 256Mi
type: Container
default-mem-example 네임스페이스에 리밋레인지를 생성한다.
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults.yaml --namespace=default-mem-example
이제 컨테이너가 default-mem-example 네임스페이스에 생성되고, 컨테이너가 메모리 요청량 및 메모리 상한에 대해 고유한 값을 지정하지 않으면, 컨테이너에 메모리 요청량 기본값 256MiB와 메모리 상한 기본값 512MiB가 지정된다.
컨테이너가 하나인 파드의 구성 파일은 다음과 같다. 컨테이너는 메모리 요청량 및 상한을 지정하지 않는다.
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo
spec:
containers:
- name: default-mem-demo-ctr
image: nginx
파드를 생성한다.
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod.yaml --namespace=default-mem-example
파드에 대한 자세한 정보를 본다.
kubectl get pod default-mem-demo --output=yaml --namespace=default-mem-example
출력 결과는 파드의 컨테이너에 256MiB의 메모리 요청량과 512MiB의 메모리 상한이 있음을 나타낸다. 이것은 리밋레인지에 의해 지정된 기본값이다.
containers:
- image: nginx
imagePullPolicy: Always
name: default-mem-demo-ctr
resources:
limits:
memory: 512Mi
requests:
memory: 256Mi
파드를 삭제한다.
kubectl delete pod default-mem-demo --namespace=default-mem-example
컨테이너 상한은 지정하고, 요청량을 지정하지 않으면 어떻게 되나?
컨테이너가 하나인 파드의 구성 파일은 다음과 같다. 컨테이너는 메모리 상한을 지정하지만, 요청량은 지정하지 않는다.
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo-2
spec:
containers:
- name: default-mem-demo-2-ctr
image: nginx
resources:
limits:
memory: "1Gi"
파드를 생성한다.
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod-2.yaml --namespace=default-mem-example
파드에 대한 자세한 정보를 본다.
kubectl get pod default-mem-demo-2 --output=yaml --namespace=default-mem-example
출력 결과는 컨테이너의 메모리 요청량이 메모리 상한과 일치하도록 설정되었음을 보여준다. 참고로 컨테이너에는 기본 메모리 요청량의 값인 256Mi가 할당되지 않았다.
resources:
limits:
memory: 1Gi
requests:
memory: 1Gi
컨테이너의 요청량은 지정하고, 상한을 지정하지 않으면 어떻게 되나?
컨테이너가 하나인 파드의 구성 파일은 다음과 같다. 컨테이너는 메모리 요청량을 지정하지만, 상한은 지정하지 않았다.
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo-3
spec:
containers:
- name: default-mem-demo-3-ctr
image: nginx
resources:
requests:
memory: "128Mi"
파드를 생성한다.
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod-3.yaml --namespace=default-mem-example
파드 사양을 확인한다.
kubectl get pod default-mem-demo-3 --output=yaml --namespace=default-mem-example
출력 결과는 컨테이너의 메모리 요청량이 컨테이너의 구성 파일에 지정된 값으로 설정되었음을 보여준다. 컨테이너의 메모리 상한은 네임스페이스의 기본 메모리 상한인 512Mi로 설정되어 있다.
resources:
limits:
memory: 512Mi
requests:
memory: 128Mi
기본 메모리 상한 및 요청량에 대한 동기
네임스페이스에 리소스 쿼터가 있는 경우, 메모리 상한에 기본값을 설정하는 것이 좋다. 다음은 리소스 쿼터가 네임스페이스에 적용하는 두 가지 제한 사항이다.
- 네임스페이스에서 실행되는 모든 컨테이너에는 자체 메모리 상한이 있어야 한다.
- 네임스페이스의 모든 컨테이너가 사용하는 총 메모리 양은 지정된 상한을 초과하지 않아야 한다.
컨테이너가 자체 메모리 상한을 지정하지 않으면, 기본 상한이 부여되고, 쿼터에 의해 제한되는 네임스페이스에서 실행될 수 있다.
정리
네임스페이스를 삭제한다.
kubectl delete namespace default-mem-example
다음 내용
클러스터 관리자를 위한 문서
앱 개발자를 위한 문서
2.2 - 네임스페이스에 대한 기본 CPU 요청량과 상한 구성
이 페이지는 네임스페이스에 대한 기본 CPU 요청량(request) 및 상한(limit)을 구성하는 방법을 보여준다. 쿠버네티스 클러스터는 네임스페이스로 나눌 수 있다. 기본 CPU 상한이 있는 네임스페이스에서 컨테이너가 생성되고, 컨테이너가 자체 CPU 상한을 지정하지 않으면, 컨테이너에 기본 CPU 상한이 할당된다. 쿠버네티스는 이 문서의 뒷부분에서 설명하는 특정 조건에서 기본 CPU 요청량을 할당한다.
시작하기 전에
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다. 만약, 아직 클러스터를 가지고 있지 않다면, minikube를 사용해서 생성하거나 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
네임스페이스 생성
이 연습에서 생성한 리소스가 클러스터의 나머지와 격리되도록 네임스페이스를 생성한다.
kubectl create namespace default-cpu-example
리밋레인지(LimitRange)와 파드 생성
다음은 리밋레인지 오브젝트의 구성 파일이다. 구성은 기본 CPU 요청량 및 기본 CPU 상한을 지정한다.
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-limit-range
spec:
limits:
- default:
cpu: 1
defaultRequest:
cpu: 0.5
type: Container
default-cpu-example 네임스페이스에 리밋레인지를 생성한다.
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-defaults.yaml --namespace=default-cpu-example
이제 컨테이너가 default-cpu-example 네임스페이스에 생성되고, 컨테이너가 CPU 요청량 및 CPU 상한에 대해 고유한 값을 지정하지 않으면, 컨테이너에 CPU 요청량의 기본값 0.5와 CPU 상한 기본값 1이 부여된다.
컨테이너가 하나인 파드의 구성 파일은 다음과 같다. 컨테이너는 CPU 요청량과 상한을 지정하지 않는다.
apiVersion: v1
kind: Pod
metadata:
name: default-cpu-demo
spec:
containers:
- name: default-cpu-demo-ctr
image: nginx
파드를 생성한다.
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-defaults-pod.yaml --namespace=default-cpu-example
파드의 사양을 확인한다.
kubectl get pod default-cpu-demo --output=yaml --namespace=default-cpu-example
출력 결과는 파드의 컨테이너에 500 milicpu의 CPU 요청량과 1 cpu의 CPU 상한이 있음을 나타낸다. 이것은 리밋레인지에 의해 지정된 기본값이다.
containers:
- image: nginx
imagePullPolicy: Always
name: default-cpu-demo-ctr
resources:
limits:
cpu: "1"
requests:
cpu: 500m
컨테이너 상한은 지정하고, 요청량을 지정하지 않으면 어떻게 되나?
컨테이너가 하나인 파드의 구성 파일은 다음과 같다. 컨테이너는 CPU 상한을 지정하지만, 요청량은 지정하지 않는다.
apiVersion: v1
kind: Pod
metadata:
name: default-cpu-demo-2
spec:
containers:
- name: default-cpu-demo-2-ctr
image: nginx
resources:
limits:
cpu: "1"
파드를 생성한다.
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-defaults-pod-2.yaml --namespace=default-cpu-example
파드 사양을 확인한다.
kubectl get pod default-cpu-demo-2 --output=yaml --namespace=default-cpu-example
출력 결과는 컨테이너의 CPU 요청량이 CPU 상한과 일치하도록 설정되었음을 보여준다. 참고로 컨테이너에는 CPU 요청량의 기본값인 0.5 cpu가 할당되지 않았다.
resources:
limits:
cpu: "1"
requests:
cpu: "1"
컨테이너의 요청량은 지정하고, 상한을 지정하지 않으면 어떻게 되나?
컨테이너가 하나인 파드의 구성 파일은 다음과 같다. 컨테이너는 CPU 요청량을 지정하지만, 상한은 지정하지 않았다.
apiVersion: v1
kind: Pod
metadata:
name: default-cpu-demo-3
spec:
containers:
- name: default-cpu-demo-3-ctr
image: nginx
resources:
requests:
cpu: "0.75"
파드를 생성한다.
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-defaults-pod-3.yaml --namespace=default-cpu-example
파드 사양을 확인한다.
kubectl get pod default-cpu-demo-3 --output=yaml --namespace=default-cpu-example
출력 결과는 컨테이너의 CPU 요청량이 컨테이너의 구성 파일에 지정된 값으로 설정되었음을 보여준다. 컨테이너의 CPU 상한은 1 cpu로 설정되며, 이는 네임스페이스의 CPU 상한 기본값이다.
resources:
limits:
cpu: "1"
requests:
cpu: 750m
CPU 상한 및 요청량의 기본값에 대한 동기
네임스페이스에 리소스 쿼터가 있는 경우, CPU 상한에 대해 기본값을 설정하는 것이 좋다. 다음은 리소스 쿼터가 네임스페이스에 적용하는 두 가지 제한 사항이다.
- 네임스페이스에서 실행되는 모든 컨테이너에는 자체 CPU 상한이 있어야 한다.
- 네임스페이스의 모든 컨테이너가 사용하는 총 CPU 양은 지정된 상한을 초과하지 않아야 한다.
컨테이너가 자체 CPU 상한을 지정하지 않으면, 상한 기본값이 부여되고, 쿼터에 의해 제한되는 네임스페이스에서 실행될 수 있다.
정리
네임스페이스를 삭제한다.
kubectl delete namespace default-cpu-example
다음 내용
클러스터 관리자를 위한 문서
앱 개발자를 위한 문서
2.3 - 네임스페이스에 대한 메모리의 최소 및 최대 제약 조건 구성
이 페이지는 네임스페이스에서 실행되는 컨테이너가 사용하는 메모리의 최솟값과 최댓값을 설정하는 방법을 보여준다. 리밋레인지(LimitRange) 오브젝트에 최소 및 최대 메모리 값을 지정한다. 파드가 리밋레인지에 의해 부과된 제약 조건을 충족하지 않으면, 네임스페이스에서 생성될 수 없다.
시작하기 전에
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다. 만약, 아직 클러스터를 가지고 있지 않다면, minikube를 사용해서 생성하거나 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
클러스터의 각 노드에는 최소 1GiB의 메모리가 있어야 한다.
네임스페이스 생성
이 연습에서 생성한 리소스가 클러스터의 나머지와 격리되도록 네임스페이스를 생성한다.
kubectl create namespace constraints-mem-example
리밋레인지와 파드 생성
다음은 리밋레인지의 구성 파일이다.
apiVersion: v1
kind: LimitRange
metadata:
name: mem-min-max-demo-lr
spec:
limits:
- max:
memory: 1Gi
min:
memory: 500Mi
type: Container
리밋레인지를 생성한다.
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints.yaml --namespace=constraints-mem-example
리밋레인지에 대한 자세한 정보를 본다.
kubectl get limitrange mem-min-max-demo-lr --namespace=constraints-mem-example --output=yaml
출력 결과는 예상대로 메모리의 최소 및 최대 제약 조건을 보여준다. 그러나 참고로 리밋레인지의 구성 파일에 기본값(default)을 지정하지 않아도 자동으로 생성된다.
limits:
- default:
memory: 1Gi
defaultRequest:
memory: 1Gi
max:
memory: 1Gi
min:
memory: 500Mi
type: Container
이제 constraints-mem-example 네임스페이스에 컨테이너가 생성될 때마다, 쿠버네티스는 다음 단계를 수행한다.
-
컨테이너가 자체 메모리 요청량(request)과 상한(limit)을 지정하지 않으면, 기본 메모리 요청량과 상한을 컨테이너에 지정한다.
-
컨테이너에 500MiB 이상의 메모리 요청량이 있는지 확인한다.
-
컨테이너의 메모리 상한이 1GiB 이하인지 확인한다.
컨테이너가 하나인 파드의 구성 파일은 다음과 같다. 컨테이너 매니페스트는 600MiB의 메모리 요청량과 800MiB의 메모리 상한을 지정한다. 이들은 리밋레인지에 의해 부과된 메모리의 최소 및 최대 제약 조건을 충족한다.
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo
spec:
containers:
- name: constraints-mem-demo-ctr
image: nginx
resources:
limits:
memory: "800Mi"
requests:
memory: "600Mi"
파드를 생성한다.
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod.yaml --namespace=constraints-mem-example
파드의 컨테이너가 실행 중인지 확인한다.
kubectl get pod constraints-mem-demo --namespace=constraints-mem-example
파드에 대한 자세한 정보를 본다.
kubectl get pod constraints-mem-demo --output=yaml --namespace=constraints-mem-example
출력 결과는 컨테이너의 메모리 요청량이 600MiB이고 메모리 상한이 800MiB임을 나타낸다. 이는 리밋레인지에 의해 부과된 제약 조건을 충족한다.
resources:
limits:
memory: 800Mi
requests:
memory: 600Mi
파드를 삭제한다.
kubectl delete pod constraints-mem-demo --namespace=constraints-mem-example
최대 메모리 제약 조건을 초과하는 파드 생성 시도
컨테이너가 하나인 파드의 구성 파일은 다음과 같다. 컨테이너는 800MiB의 메모리 요청량과 1.5GiB의 메모리 상한을 지정한다.
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-2
spec:
containers:
- name: constraints-mem-demo-2-ctr
image: nginx
resources:
limits:
memory: "1.5Gi"
requests:
memory: "800Mi"
파드 생성을 시도한다.
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-2.yaml --namespace=constraints-mem-example
컨테이너가 너무 큰 메모리 상한을 지정하므로, 출력 결과에 파드가 생성되지 않은 것으로 표시된다.
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-2.yaml":
pods "constraints-mem-demo-2" is forbidden: maximum memory usage per Container is 1Gi, but limit is 1536Mi.
최소 메모리 요청량을 충족하지 않는 파드 생성 시도
컨테이너가 하나인 파드의 구성 파일은 다음과 같다. 컨테이너는 100MiB의 메모리 요청량과 800MiB의 메모리 상한을 지정한다.
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-3
spec:
containers:
- name: constraints-mem-demo-3-ctr
image: nginx
resources:
limits:
memory: "800Mi"
requests:
memory: "100Mi"
파드 생성을 시도한다.
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-3.yaml --namespace=constraints-mem-example
컨테이너가 너무 작은 메모리 요청량을 지정하므로, 출력 결과에 파드가 생성되지 않은 것으로 표시된다.
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-3.yaml":
pods "constraints-mem-demo-3" is forbidden: minimum memory usage per Container is 500Mi, but request is 100Mi.
메모리 요청량 또는 상한을 지정하지 않은 파드 생성
컨테이너가 하나인 파드의 구성 파일은 다음과 같다. 컨테이너는 메모리 요청량을 지정하지 않으며, 메모리 상한을 지정하지 않는다.
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-4
spec:
containers:
- name: constraints-mem-demo-4-ctr
image: nginx
파드를 생성한다.
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-4.yaml --namespace=constraints-mem-example
파드에 대한 자세한 정보를 본다.
kubectl get pod constraints-mem-demo-4 --namespace=constraints-mem-example --output=yaml
출력 결과는 파드의 컨테이너에 1GiB의 메모리 요청량과 1GiB의 메모리 상한이 있음을 보여준다. 컨테이너는 이러한 값을 어떻게 얻었을까?
resources:
limits:
memory: 1Gi
requests:
memory: 1Gi
컨테이너가 자체 메모리 요청량과 상한을 지정하지 않았으므로, 리밋레인지의 메모리의 요청량과 상한 기본값이 제공되었다.
이 시점에서, 컨테이너가 실행 중이거나 실행 중이 아닐 수 있다. 이 태스크의 전제 조건은 노드에 최소 1GiB의 메모리가 있어야 한다는 것이다. 각 노드에 1GiB의 메모리만 있는 경우, 노드에 할당할 수 있는 메모리가 1GiB의 메모리 요청량을 수용하기에 충분하지 않을 수 있다. 메모리가 2GiB인 노드를 사용하는 경우에는, 메모리가 1GiB 요청량을 수용하기에 충분할 것이다.
파드를 삭제한다.
kubectl delete pod constraints-mem-demo-4 --namespace=constraints-mem-example
메모리의 최소 및 최대 제약 조건 적용
리밋레인지에 의해 네임스페이스에 부과된 메모리의 최대 및 최소 제약 조건은 파드를 생성하거나 업데이트할 때만 적용된다. 리밋레인지를 변경해도, 이전에 생성된 파드에는 영향을 미치지 않는다.
메모리의 최소 및 최대 제약 조건에 대한 동기
클러스터 관리자는 파드가 사용할 수 있는 메모리 양에 제한을 둘 수 있다. 예를 들면 다음과 같다.
-
클러스터의 각 노드에는 2GB의 메모리가 있다. 클러스터의 어떤 노드도 2GB 이상의 요청량을 지원할 수 없으므로, 2GB 이상의 메모리를 요청하는 파드를 수락하지 않으려고 한다.
-
클러스터는 운영 부서와 개발 부서에서 공유한다. 프로덕션 워크로드가 최대 8GB의 메모리를 소비하도록 하려면, 개발 워크로드를 512MB로 제한해야 한다. 프로덕션 및 개발을 위해 별도의 네임스페이스를 만들고, 각 네임스페이스에 메모리 제약 조건을 적용한다.
정리
네임스페이스를 삭제한다.
kubectl delete namespace constraints-mem-example
다음 내용
클러스터 관리자를 위한 문서
앱 개발자를 위한 문서
2.4 - 네임스페이스에 대한 CPU의 최소 및 최대 제약 조건 구성
이 페이지는 네임스페이스에서 컨테이너와 파드가 사용하는 CPU 리소스의 최솟값과 최댓값을 설정하는 방법을 보여준다. 리밋레인지(LimitRange) 오브젝트에 CPU의 최솟값과 최댓값을 지정한다. 리밋레인지에 의해 부과된 제약 조건을 파드가 충족하지 않으면, 네임스페이스에서 생성될 수 없다.
시작하기 전에
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다. 만약, 아직 클러스터를 가지고 있지 않다면, minikube를 사용해서 생성하거나 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
태스크 예제를 실행하려면 클러스터에 적어도 1 CPU 이상이 사용 가능해야 한다.
네임스페이스 생성
이 연습에서 생성한 리소스가 클러스터의 나머지와 격리되도록 네임스페이스를 생성한다.
kubectl create namespace constraints-cpu-example
리밋레인지와 파드 생성
다음은 리밋레인지에 대한 구성 파일이다.
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-min-max-demo-lr
spec:
limits:
- max:
cpu: "800m"
min:
cpu: "200m"
type: Container
리밋레인지를 생성한다.
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints.yaml --namespace=constraints-cpu-example
리밋레인지에 대한 자세한 정보를 본다.
kubectl get limitrange cpu-min-max-demo-lr --output=yaml --namespace=constraints-cpu-example
출력 결과는 예상대로 CPU의 최소와 최대 제약 조건을 보여준다. 그러나 참고로 리밋레인지에 대한 구성 파일에 기본값을 지정하지 않아도 자동으로 생성된다.
limits:
- default:
cpu: 800m
defaultRequest:
cpu: 800m
max:
cpu: 800m
min:
cpu: 200m
type: Container
이제 constraints-cpu-example 네임스페이스에 컨테이너가 생성될 때마다, 쿠버네티스는 다음 단계를 수행한다.
-
컨테이너가 자체 CPU 요청량(request)과 상한(limit)을 지정하지 않으면, 컨테이너에 CPU 요청량과 상한의 기본값(default)을 지정한다.
-
컨테이너가 200 millicpu 이상의 CPU 요청량을 지정하는지 확인한다.
-
컨테이너가 800 millicpu 이하의 CPU 상한을 지정하는지 확인한다.
LimitRange 오브젝트를 생성할 때, huge-pages
또는 GPU에도 상한을 지정할 수 있다. 그러나, 이 리소스들에 default 와 defaultRequest 가
모두 지정되어 있으면, 두 값은 같아야 한다.
컨테이너가 하나인 파드의 구성 파일은 다음과 같다. 컨테이너 매니페스트는 500 millicpu의 CPU 요청량 및 800 millicpu의 CPU 상한을 지정한다. 이는 리밋레인지에 의해 부과된 CPU의 최소와 최대 제약 조건을 충족시킨다.
apiVersion: v1
kind: Pod
metadata:
name: constraints-cpu-demo
spec:
containers:
- name: constraints-cpu-demo-ctr
image: nginx
resources:
limits:
cpu: "800m"
requests:
cpu: "500m"
파드를 생성한다.
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints-pod.yaml --namespace=constraints-cpu-example
파드의 컨테이너가 실행 중인지 확인한다.
kubectl get pod constraints-cpu-demo --namespace=constraints-cpu-example
파드에 대한 자세한 정보를 본다.
kubectl get pod constraints-cpu-demo --output=yaml --namespace=constraints-cpu-example
출력 결과는 컨테이너의 CPU 요청량이 500 millicpu이고, CPU 상한이 800 millicpu임을 나타낸다. 이는 리밋레인지에 의해 부과된 제약 조건을 만족시킨다.
resources:
limits:
cpu: 800m
requests:
cpu: 500m
파드 삭제
kubectl delete pod constraints-cpu-demo --namespace=constraints-cpu-example
CPU 최대 제약 조건을 초과하는 파드 생성 시도
컨테이너가 하나인 파드의 구성 파일은 다음과 같다. 컨테이너는 500 millicpu의 CPU 요청량과 1.5 cpu의 CPU 상한을 지정한다.
apiVersion: v1
kind: Pod
metadata:
name: constraints-cpu-demo-2
spec:
containers:
- name: constraints-cpu-demo-2-ctr
image: nginx
resources:
limits:
cpu: "1.5"
requests:
cpu: "500m"
파드 생성을 시도한다.
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints-pod-2.yaml --namespace=constraints-cpu-example
컨테이너가 너무 큰 CPU 상한을 지정하므로, 출력 결과에 파드가 생성되지 않은 것으로 표시된다.
Error from server (Forbidden): error when creating "examples/admin/resource/cpu-constraints-pod-2.yaml":
pods "constraints-cpu-demo-2" is forbidden: maximum cpu usage per Container is 800m, but limit is 1500m.
최소 CPU 요청량을 충족하지 않는 파드 생성 시도
컨테이너가 하나인 파드의 구성 파일은 다음과 같다. 컨테이너는 100 millicpu의 CPU 요청량과 800 millicpu의 CPU 상한을 지정한다.
apiVersion: v1
kind: Pod
metadata:
name: constraints-cpu-demo-3
spec:
containers:
- name: constraints-cpu-demo-3-ctr
image: nginx
resources:
limits:
cpu: "800m"
requests:
cpu: "100m"
파드 생성을 시도한다.
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints-pod-3.yaml --namespace=constraints-cpu-example
컨테이너가 너무 작은 CPU 요청량을 지정하므로, 출력 결과에 파드가 생성되지 않은 것으로 표시된다.
Error from server (Forbidden): error when creating "examples/admin/resource/cpu-constraints-pod-3.yaml":
pods "constraints-cpu-demo-3" is forbidden: minimum cpu usage per Container is 200m, but request is 100m.
CPU 요청량 또는 상한을 지정하지 않은 파드 생성
컨테이너가 하나인 파드의 구성 파일은 다음과 같다. 컨테이너는 CPU 요청량을 지정하지 않으며, CPU 상한을 지정하지 않는다.
apiVersion: v1
kind: Pod
metadata:
name: constraints-cpu-demo-4
spec:
containers:
- name: constraints-cpu-demo-4-ctr
image: vish/stress
파드를 생성한다.
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints-pod-4.yaml --namespace=constraints-cpu-example
파드에 대한 자세한 정보를 본다.
kubectl get pod constraints-cpu-demo-4 --namespace=constraints-cpu-example --output=yaml
출력 결과는 파드의 컨테이너에 대한 CPU 요청량이 800 millicpu이고, CPU 상한이 800 millicpu임을 나타낸다. 컨테이너는 어떻게 이런 값을 얻었을까?
resources:
limits:
cpu: 800m
requests:
cpu: 800m
컨테이너가 자체 CPU 요청량과 상한을 지정하지 않았으므로, 리밋레인지로부터 CPU 요청량과 상한의 기본값이 주어졌다.
이 시점에서, 컨테이너는 실행 중이거나 실행 중이 아닐 수 있다. 이 태스크의 전제 조건은 클러스터에 1 CPU 이상 사용 가능해야 한다는 것이다. 각 노드에 1 CPU만 있는 경우, 노드에 할당할 수 있는 CPU가 800 millicpu의 요청량을 수용하기에 충분하지 않을 수 있다. 2 CPU인 노드를 사용하는 경우에는, CPU가 800 millicpu 요청량을 수용하기에 충분할 것이다.
파드를 삭제한다.
kubectl delete pod constraints-cpu-demo-4 --namespace=constraints-cpu-example
CPU의 최소 및 최대 제약 조건의 적용
리밋레인지에 의해 네임스페이스에 부과된 CPU의 최대 및 최소 제약 조건은 파드를 생성하거나 업데이트할 때만 적용된다. 리밋레인지를 변경해도, 이전에 생성된 파드에는 영향을 미치지 않는다.
CPU의 최소 및 최대 제약 조건에 대한 동기
클러스터 관리자는 파드가 사용할 수 있는 CPU 리소스에 제한을 둘 수 있다. 예를 들면 다음과 같다.
-
클러스터의 각 노드에는 2 CPU가 있다. 클러스터의 어떤 노드도 요청량을 지원할 수 없기 때문에, 2 CPU 이상을 요청하는 파드를 수락하지 않으려고 한다.
-
클러스터는 프로덕션과 개발 부서에서 공유한다. 프로덕션 워크로드가 최대 3 CPU를 소비하도록 하고 싶지만, 개발 워크로드는 1 CPU로 제한하려고 한다. 프로덕션과 개발을 위해 별도의 네임스페이스를 생성하고, 각 네임스페이스에 CPU 제약 조건을 적용한다.
정리
네임스페이스를 삭제한다.
kubectl delete namespace constraints-cpu-example
다음 내용
클러스터 관리자를 위한 문서
앱 개발자를 위한 문서
2.5 - 네임스페이스에 대한 메모리 및 CPU 쿼터 구성
이 페이지는 네임스페이스에서 실행 중인 모든 컨테이너가 사용할 수 있는 총 메모리 및 CPU 양에 대한 쿼터를 설정하는 방법을 보여준다. 리소스쿼터(ResourceQuota) 오브젝트에 쿼터를 지정한다.
시작하기 전에
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다. 만약, 아직 클러스터를 가지고 있지 않다면, minikube를 사용해서 생성하거나 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
클러스터의 각 노드에는 최소 1GiB의 메모리가 있어야 한다.
네임스페이스 생성
이 연습에서 생성한 리소스가 클러스터의 나머지와 격리되도록 네임스페이스를 생성한다.
kubectl create namespace quota-mem-cpu-example
리소스쿼터 생성
다음은 리소스쿼터 오브젝트의 구성 파일이다.
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-demo
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
리소스쿼터를 생성한다.
kubectl apply -f https://k8s.io/examples/admin/resource/quota-mem-cpu.yaml --namespace=quota-mem-cpu-example
리소스쿼터에 대한 자세한 정보를 본다.
kubectl get resourcequota mem-cpu-demo --namespace=quota-mem-cpu-example --output=yaml
리소스쿼터는 이러한 요구 사항을 quota-mem-cpu-example 네임스페이스에 배치한다.
- 모든 컨테이너에는 메모리 요청량(request), 메모리 상한(limit), CPU 요청량 및 CPU 상한이 있어야 한다.
- 모든 컨테이너에 대한 총 메모리 요청량은 1GiB를 초과하지 않아야 한다.
- 모든 컨테이너에 대한 총 메모리 상한은 2GiB를 초과하지 않아야 한다.
- 모든 컨테이너에 대한 총 CPU 요청량은 1 cpu를 초과해서는 안된다.
- 모든 컨테이너에 대한 총 CPU 상한은 2 cpu를 초과해서는 안된다.
파드 생성
파드의 구성 파일은 다음과 같다.
apiVersion: v1
kind: Pod
metadata:
name: quota-mem-cpu-demo
spec:
containers:
- name: quota-mem-cpu-demo-ctr
image: nginx
resources:
limits:
memory: "800Mi"
cpu: "800m"
requests:
memory: "600Mi"
cpu: "400m"
파드를 생성한다.
kubectl apply -f https://k8s.io/examples/admin/resource/quota-mem-cpu-pod.yaml --namespace=quota-mem-cpu-example
파드의 컨테이너가 실행 중인지 확인한다.
kubectl get pod quota-mem-cpu-demo --namespace=quota-mem-cpu-example
다시 한 번, 리소스쿼터에 대한 자세한 정보를 본다.
kubectl get resourcequota mem-cpu-demo --namespace=quota-mem-cpu-example --output=yaml
출력 결과는 쿼터와 사용된 쿼터를 함께 보여준다. 파드의 메모리와 CPU 요청량 및 상한이 쿼터를 초과하지 않은 것을 볼 수 있다.
status:
hard:
limits.cpu: "2"
limits.memory: 2Gi
requests.cpu: "1"
requests.memory: 1Gi
used:
limits.cpu: 800m
limits.memory: 800Mi
requests.cpu: 400m
requests.memory: 600Mi
두 번째 파드 생성 시도
다음은 두 번째 파드의 구성 파일이다.
apiVersion: v1
kind: Pod
metadata:
name: quota-mem-cpu-demo-2
spec:
containers:
- name: quota-mem-cpu-demo-2-ctr
image: redis
resources:
limits:
memory: "1Gi"
cpu: "800m"
requests:
memory: "700Mi"
cpu: "400m"
구성 파일에서, 파드의 메모리 요청량이 700MiB임을 알 수 있다. 사용된 메모리 요청량과 이 새 메모리 요청량의 합계가 메모리 요청량 쿼터를 초과한다. 600MiB + 700MiB > 1GiB
파드 생성을 시도한다.
kubectl apply -f https://k8s.io/examples/admin/resource/quota-mem-cpu-pod-2.yaml --namespace=quota-mem-cpu-example
두 번째 파드는 생성되지 않는다. 출력 결과는 두 번째 파드를 생성하면 메모리 요청량의 총 합계가 메모리 요청량 쿼터를 초과함을 보여준다.
Error from server (Forbidden): error when creating "examples/admin/resource/quota-mem-cpu-pod-2.yaml":
pods "quota-mem-cpu-demo-2" is forbidden: exceeded quota: mem-cpu-demo,
requested: requests.memory=700Mi,used: requests.memory=600Mi, limited: requests.memory=1Gi
토론
이 연습에서 보았듯이, 리소스쿼터를 사용하여 네임스페이스에서 실행 중인 모든 컨테이너에 대한 메모리 요청량의 총 합계를 제한할 수 있다. 메모리 상한, CPU 요청량 및 CPU 상한의 총 합계를 제한할 수도 있다.
모든 컨테이너에 대한 합계 대신 개별 컨테이너를 제한하려면, 리밋레인지(LimitRange)를 사용한다.
정리
네임스페이스를 삭제한다.
kubectl delete namespace quota-mem-cpu-example
다음 내용
클러스터 관리자를 위한 문서
앱 개발자를 위한 문서
2.6 - 네임스페이스에 대한 파드 쿼터 구성
이 페이지는 네임스페이스에서 실행할 수 있는 총 파드 수에 대한 쿼터를 설정하는 방법을 보여준다. 리소스쿼터(ResourceQuota) 오브젝트에 쿼터를 지정한다.
시작하기 전에
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다. 만약, 아직 클러스터를 가지고 있지 않다면, minikube를 사용해서 생성하거나 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
네임스페이스 생성
이 실습에서 생성한 리소스가 클러스터의 나머지와 격리되도록 네임스페이스를 생성한다.
kubectl create namespace quota-pod-example
리소스쿼터 생성
다음은 리소스쿼터 오브젝트의 구성 파일이다.
apiVersion: v1
kind: ResourceQuota
metadata:
name: pod-demo
spec:
hard:
pods: "2"
리소스쿼터를 생성한다.
kubectl apply -f https://k8s.io/examples/admin/resource/quota-pod.yaml --namespace=quota-pod-example
리소스쿼터에 대한 자세한 정보를 본다.
kubectl get resourcequota pod-demo --namespace=quota-pod-example --output=yaml
출력 결과는 네임스페이스에 두 개의 파드 쿼터가 있고, 현재 파드가 없음을 보여준다. 즉, 쿼터 중 어느 것도 사용되지 않았다.
spec:
hard:
pods: "2"
status:
hard:
pods: "2"
used:
pods: "0"
다음은 디플로이먼트(Deployment) 구성 파일이다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-quota-demo
spec:
selector:
matchLabels:
purpose: quota-demo
replicas: 3
template:
metadata:
labels:
purpose: quota-demo
spec:
containers:
- name: pod-quota-demo
image: nginx
구성 파일에서, replicas: 3 은 쿠버네티스가 모두 동일한 애플리케이션을 실행하는 세 개의 파드를 만들도록 지시한다.
디플로이먼트를 생성한다.
kubectl apply -f https://k8s.io/examples/admin/resource/quota-pod-deployment.yaml --namespace=quota-pod-example
디플로이먼트에 대한 자세한 정보를 본다.
kubectl get deployment pod-quota-demo --namespace=quota-pod-example --output=yaml
출력 결과는 디플로이먼트에서 3개의 레플리카를 지정하더라도, 쿼터로 인해 2개의 파드만 생성되었음을 보여준다.
spec:
...
replicas: 3
...
status:
availableReplicas: 2
...
lastUpdateTime: 2017-07-07T20:57:05Z
message: 'unable to create pods: pods "pod-quota-demo-1650323038-" is forbidden:
exceeded quota: pod-demo, requested: pods=1, used: pods=2, limited: pods=2'
정리
네임스페이스를 삭제한다.
kubectl delete namespace quota-pod-example
다음 내용
클러스터 관리자를 위한 문서
앱 개발자를 위한 문서
3 - 인증서
클라이언트 인증서로 인증을 사용하는 경우 easyrsa, openssl 또는 cfssl
을 통해 인증서를 수동으로 생성할 수 있다.
easyrsa
easyrsa 는 클러스터 인증서를 수동으로 생성할 수 있다.
-
easyrsa3의 패치 버전을 다운로드하여 압축을 풀고, 초기화한다.
curl -LO https://storage.googleapis.com/kubernetes-release/easy-rsa/easy-rsa.tar.gz tar xzf easy-rsa.tar.gz cd easy-rsa-master/easyrsa3 ./easyrsa init-pki -
새로운 인증 기관(CA)을 생성한다.
--batch는 자동 모드를 설정한다.--req-cn는 CA의 새 루트 인증서에 대한 일반 이름(Common Name (CN))을 지정한다../easyrsa --batch "--req-cn=${MASTER_IP}@`date +%s`" build-ca nopass -
서버 인증서와 키를 생성한다.
--subject-alt-name인수는 API 서버에 접근이 가능한 IP와 DNS 이름을 설정한다.MASTER_CLUSTER_IP는 일반적으로 API 서버와 컨트롤러 관리자 컴포넌트에 대해--service-cluster-ip-range인수로 지정된 서비스 CIDR의 첫 번째 IP이다.--days인수는 인증서가 만료되는 일 수를 설정하는데 사용된다. 또한, 아래 샘플은 기본 DNS 이름으로cluster.local을 사용한다고 가정한다../easyrsa --subject-alt-name="IP:${MASTER_IP},"\ "IP:${MASTER_CLUSTER_IP},"\ "DNS:kubernetes,"\ "DNS:kubernetes.default,"\ "DNS:kubernetes.default.svc,"\ "DNS:kubernetes.default.svc.cluster,"\ "DNS:kubernetes.default.svc.cluster.local" \ --days=10000 \ build-server-full server nopass -
pki/ca.crt,pki/issued/server.crt그리고pki/private/server.key를 디렉터리에 복사한다. -
API 서버 시작 파라미터에 다음 파라미터를 채우고 추가한다.
--client-ca-file=/yourdirectory/ca.crt --tls-cert-file=/yourdirectory/server.crt --tls-private-key-file=/yourdirectory/server.key
openssl
openssl 은 클러스터 인증서를 수동으로 생성할 수 있다.
-
ca.key를 2048bit로 생성한다.
openssl genrsa -out ca.key 2048 -
ca.key에 따라 ca.crt를 생성한다(인증서 유효 기간을 사용하려면 -days를 사용한다).
openssl req -x509 -new -nodes -key ca.key -subj "/CN=${MASTER_IP}" -days 10000 -out ca.crt -
server.key를 2048bit로 생성한다.
openssl genrsa -out server.key 2048 -
인증서 서명 요청(Certificate Signing Request (CSR))을 생성하기 위한 설정 파일을 생성한다. 파일에 저장하기 전에 꺾쇠 괄호(예:
<MASTER_IP>)로 표시된 값을 실제 값으로 대체한다(예:csr.conf).MASTER_CLUSTER_IP의 값은 이전 하위 섹션에서 설명한 대로 API 서버의 서비스 클러스터 IP이다. 또한, 아래 샘플에서는cluster.local을 기본 DNS 도메인 이름으로 사용하고 있다고 가정한다.[ req ] default_bits = 2048 prompt = no default_md = sha256 req_extensions = req_ext distinguished_name = dn [ dn ] C = <국가(country)> ST = <도(state)> L = <시(city)> O = <조직(organization)> OU = <조직 단위(organization unit)> CN = <MASTER_IP> [ req_ext ] subjectAltName = @alt_names [ alt_names ] DNS.1 = kubernetes DNS.2 = kubernetes.default DNS.3 = kubernetes.default.svc DNS.4 = kubernetes.default.svc.cluster DNS.5 = kubernetes.default.svc.cluster.local IP.1 = <MASTER_IP> IP.2 = <MASTER_CLUSTER_IP> [ v3_ext ] authorityKeyIdentifier=keyid,issuer:always basicConstraints=CA:FALSE keyUsage=keyEncipherment,dataEncipherment extendedKeyUsage=serverAuth,clientAuth subjectAltName=@alt_names -
설정 파일을 기반으로 인증서 서명 요청을 생성한다.
openssl req -new -key server.key -out server.csr -config csr.conf -
ca.key, ca.crt 그리고 server.csr을 사용해서 서버 인증서를 생성한다.
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key \ -CAcreateserial -out server.crt -days 10000 \ -extensions v3_ext -extfile csr.conf -
인증서 서명 요청을 확인한다.
openssl req -noout -text -in ./server.csr -
인증서를 확인한다.
openssl x509 -noout -text -in ./server.crt
마지막으로, API 서버 시작 파라미터에 동일한 파라미터를 추가한다.
cfssl
cfssl 은 인증서 생성을 위한 또 다른 도구이다.
-
아래에 표시된 대로 커맨드 라인 도구를 다운로드하여 압축을 풀고 준비한다. 사용 중인 하드웨어 아키텍처 및 cfssl 버전에 따라 샘플 명령을 조정해야 할 수도 있다.
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl_1.5.0_linux_amd64 -o cfssl chmod +x cfssl curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssljson_1.5.0_linux_amd64 -o cfssljson chmod +x cfssljson curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl-certinfo_1.5.0_linux_amd64 -o cfssl-certinfo chmod +x cfssl-certinfo -
아티팩트(artifact)를 보유할 디렉터리를 생성하고 cfssl을 초기화한다.
mkdir cert cd cert ../cfssl print-defaults config > config.json ../cfssl print-defaults csr > csr.json -
CA 파일을 생성하기 위한 JSON 설정 파일을
ca-config.json예시와 같이 생성한다.{ "signing": { "default": { "expiry": "8760h" }, "profiles": { "kubernetes": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "8760h" } } } } -
CA 인증서 서명 요청(CSR)을 위한 JSON 설정 파일을
ca-csr.json예시와 같이 생성한다. 꺾쇠 괄호로 표시된 값을 사용하려는 실제 값으로 변경한다.{ "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names":[{ "C": "<국가(country)>", "ST": "<도(state)>", "L": "<시(city)>", "O": "<조직(organization)>", "OU": "<조직 단위(organization unit)>" }] } -
CA 키(
ca-key.pem)와 인증서(ca.pem)을 생성한다.../cfssl gencert -initca ca-csr.json | ../cfssljson -bare ca -
API 서버의 키와 인증서를 생성하기 위한 JSON 구성파일을
server-csr.json예시와 같이 생성한다. 꺾쇠 괄호 안의 값을 사용하려는 실제 값으로 변경한다.MASTER_CLUSTER_IP는 이전 하위 섹션에서 설명한 API 서버의 클러스터 IP이다. 아래 샘플은 기본 DNS 도메인 이름으로cluster.local을 사용한다고 가정한다.{ "CN": "kubernetes", "hosts": [ "127.0.0.1", "<MASTER_IP>", "<MASTER_CLUSTER_IP>", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster", "kubernetes.default.svc.cluster.local" ], "key": { "algo": "rsa", "size": 2048 }, "names": [{ "C": "<국가(country)>", "ST": "<도(state)>", "L": "<시(city)>", "O": "<조직(organization)>", "OU": "<조직 단위(organization unit)>" }] } -
API 서버 키와 인증서를 생성하면, 기본적으로
server-key.pem과server.pem파일에 각각 저장된다.../cfssl gencert -ca=ca.pem -ca-key=ca-key.pem \ --config=ca-config.json -profile=kubernetes \ server-csr.json | ../cfssljson -bare server
자체 서명된 CA 인증서의 배포
클라이언트 노드는 자체 서명된 CA 인증서를 유효한 것으로 인식하지 않을 수 있다. 비-프로덕션 디플로이먼트 또는 회사 방화벽 뒤에서 실행되는 디플로이먼트의 경우, 자체 서명된 CA 인증서를 모든 클라이언트에 배포하고 유효한 인증서의 로컬 목록을 새로 고칠 수 있다.
각 클라이언트에서, 다음 작업을 수행한다.
sudo cp ca.crt /usr/local/share/ca-certificates/kubernetes.crt
sudo update-ca-certificates
Updating certificates in /etc/ssl/certs...
1 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d....
done.
인증서 API
certificates.k8s.io API를 사용해서
여기에
설명된 대로 인증에 사용할 x509 인증서를 프로비전 할 수 있다.
4 - 네트워크 폴리시 제공자(Network Policy Provider) 설치
4.1 - 네트워크 폴리시로 캘리코(Calico) 사용하기
이 페이지는 쿠버네티스에서 캘리코(Calico) 클러스터를 생성하는 몇 가지 빠른 방법을 살펴본다.
시작하기 전에
클라우드나 지역 클러스터 중에 어디에 배포할지 결정한다.
구글 쿠버네티스 엔진(GKE)에 캘리코 클러스터 생성하기
사전요구사항: gcloud.
-
캘리코로 GKE 클러스터를 시작하려면,
--enable-network-policy플래그를 추가한다.문법
gcloud container clusters create [클러스터_이름] --enable-network-policy예시
gcloud container clusters create my-calico-cluster --enable-network-policy -
배포를 확인하기 위해, 다음 커맨드를 이용하자.
kubectl get pods --namespace=kube-system캘리코 파드는
calico로 시작한다. 각각의 상태가Running임을 확인하자.
kubeadm으로 지역 캘리코 클러스터 생성하기
Kubeadm을 이용해서 15분 이내에 지역 단일 호스트 캘리코 클러스터를 생성하려면, 캘리코 빠른 시작을 참고한다.
다음 내용
클러스터가 동작하면, 쿠버네티스 네트워크 폴리시(NetworkPolicy)를 시도하기 위해 네트워크 폴리시 선언하기를 따라 할 수 있다.
4.2 - 네트워크 폴리시로 실리움(Cilium) 사용하기
이 페이지는 어떻게 네트워크 폴리시(NetworkPolicy)로 실리움(Cilium)를 사용하는지 살펴본다.
실리움의 배경에 대해서는 실리움 소개를 읽어보자.
시작하기 전에
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다. 만약, 아직 클러스터를 가지고 있지 않다면, minikube를 사용해서 생성하거나 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
기본 시험을 위해 실리움을 Minikube에 배포하기
실리움에 쉽게 친숙해지기 위해 Minikube에 실리움을 기본적인 데몬셋으로 설치를 수행하는 실리움 쿠버네티스 시작하기 안내를 따라 해볼 수 있다.
Minikube를 시작하려면 최소 버전으로 >= v1.5.2 이 필요하고, 다음의 실행 파라미터로 실행한다.
minikube version
minikube version: v1.5.2
minikube start --network-plugin=cni
minikube의 경우 CLI 도구를 사용하여 실리움을 설치할 수 있다. 실리움은 클러스터 구성을 자동으로 감지하고 성공적인 설치를 위해 적절한 구성 요소를 설치한다.
curl -LO https://github.com/cilium/cilium-cli/releases/latest/download/cilium-linux-amd64.tar.gz
sudo tar xzvfC cilium-linux-amd64.tar.gz /usr/local/bin
rm cilium-linux-amd64.tar.gz
cilium install
🔮 Auto-detected Kubernetes kind: minikube
✨ Running "minikube" validation checks
✅ Detected minikube version "1.20.0"
ℹ️ Cilium version not set, using default version "v1.10.0"
🔮 Auto-detected cluster name: minikube
🔮 Auto-detected IPAM mode: cluster-pool
🔮 Auto-detected datapath mode: tunnel
🔑 Generating CA...
2021/05/27 02:54:44 [INFO] generate received request
2021/05/27 02:54:44 [INFO] received CSR
2021/05/27 02:54:44 [INFO] generating key: ecdsa-256
2021/05/27 02:54:44 [INFO] encoded CSR
2021/05/27 02:54:44 [INFO] signed certificate with serial number 48713764918856674401136471229482703021230538642
🔑 Generating certificates for Hubble...
2021/05/27 02:54:44 [INFO] generate received request
2021/05/27 02:54:44 [INFO] received CSR
2021/05/27 02:54:44 [INFO] generating key: ecdsa-256
2021/05/27 02:54:44 [INFO] encoded CSR
2021/05/27 02:54:44 [INFO] signed certificate with serial number 3514109734025784310086389188421560613333279574
🚀 Creating Service accounts...
🚀 Creating Cluster roles...
🚀 Creating ConfigMap...
🚀 Creating Agent DaemonSet...
🚀 Creating Operator Deployment...
⌛ Waiting for Cilium to be installed...
시작하기 안내서의 나머지 부분은 예제 애플리케이션을 이용하여 L3/L4(예, IP 주소 + 포트) 모두의 보안 정책뿐만 아니라 L7(예, HTTP)의 보안 정책을 적용하는 방법을 설명한다.
실리움을 실 서비스 용도로 배포하기
실리움을 실 서비스 용도의 배포에 관련한 자세한 방법은 실리움 쿠버네티스 설치 안내를 살펴본다. 이 문서는 자세한 요구사항, 방법과 실제 데몬셋 예시를 포함한다.
실리움 구성요소 이해하기
실리움으로 클러스터를 배포하면 파드가 kube-system 네임스페이스에 추가된다.
파드의 목록을 보려면 다음을 실행한다.
kubectl get pods --namespace=kube-system -l k8s-app=cilium
다음과 유사한 파드의 목록을 볼 것이다.
NAME READY STATUS RESTARTS AGE
cilium-kkdhz 1/1 Running 0 3m23s
...
cilium 파드는 클러스터 각 노드에서 실행되며, 리눅스 BPF를 사용해서
해당 노드의 파드에 대한 트래픽 네트워크 폴리시를 적용한다.
다음 내용
클러스터가 동작하면, 실리움으로 쿠버네티스 네트워크 폴리시를 시도하기 위해 네트워크 폴리시 선언하기를 따라 할 수 있다. 재미있게 즐기고, 질문이 있다면 실리움 슬랙 채널을 이용하여 연락한다.
4.3 - 네트워크 폴리시로 큐브 라우터(Kube-router) 사용하기
이 페이지는 네트워크 폴리시(NetworkPolicy)로 큐브 라우터(Kube-router)를 사용하는 방법을 살펴본다.
시작하기 전에
운영 중인 쿠버네티스 클러스터가 필요하다. 클러스터가 없다면, Kops, Bootkube, Kubeadm 등을 이용해서 클러스터를 생성할 수 있다.
큐브 라우터 애드온 설치하기
큐브 라우터 애드온은 갱신된 모든 네트워크 폴리시 및 파드에 대해 쿠버네티스 API 서버를 감시하고, 정책에 따라 트래픽을 허용하거나 차단하도록 iptables 규칙와 ipset을 구성하는 네트워크 폴리시 컨트롤러와 함께 제공된다. 큐브 라우터 애드온을 설치하는 큐브 라우터를 클러스터 인스톨러와 함께 사용하기 안내서를 따라해 봅니다.
다음 내용
큐브 라우터 애드온을 설치한 후에는, 쿠버네티스 네트워크 폴리시를 시도하기 위해 네트워크 폴리시 선언하기를 따라 할 수 있다.
4.4 - 네트워크 폴리시로 로마나(Romana)
이 페이지는 네트워크 폴리시(NetworkPolicy)로 로마나(Romana)를 사용하는 방법을 살펴본다.
시작하기 전에
kubeadm 시작하기의 1, 2, 3 단계를 완료하자.
kubeadm으로 로마나 설치하기
Kubeadm을 위한 컨테이너화된 설치 안내서를 따른다.
네트워크 폴리시 적용하기
네트워크 폴리시를 적용하기 위해 다음 중에 하나를 사용하자.
- Romana 네트워크 폴리시.
- 네트워크 폴리시 API.
다음 내용
로마나를 설치한 후에는, 쿠버네티스 네트워크 폴리시를 시도하기 위해 네트워크 폴리시 선언하기를 따라 할 수 있다.
4.5 - 네트워크 폴리시로 위브넷(Weave Net) 사용하기
이 페이지는 네트워크 폴리시(NetworkPolicy)로 위브넷(Weave Net)를 사용하는 방법을 살펴본다.
시작하기 전에
쿠버네티스 클러스터가 필요하다. 맨 땅에서부터 시작하기를 위해서 kubeadm 시작하기 안내서를 따른다.
Weave Net 애드온을 설치한다
애드온을 통한 쿠버네티스 통합하기 가이드를 따른다.
쿠버네티스의 위브넷 애드온은 쿠버네티스의 모든 네임스페이스의
네크워크 정책 어노테이션을 자동으로 모니터링하며,
정책에 따라 트래픽을 허용하고 차단하는 iptables 규칙을 구성하는
네트워크 폴리시 컨트롤러와 함께 제공된다.
설치 시험
위브넷이 동작하는지 확인한다.
다음 커맨드를 입력한다.
kubectl get pods -n kube-system -o wide
출력은 다음과 유사하다.
NAME READY STATUS RESTARTS AGE IP NODE
weave-net-1t1qg 2/2 Running 0 9d 192.168.2.10 worknode3
weave-net-231d7 2/2 Running 1 7d 10.2.0.17 worknodegpu
weave-net-7nmwt 2/2 Running 3 9d 192.168.2.131 masternode
weave-net-pmw8w 2/2 Running 0 9d 192.168.2.216 worknode2
위브넷 파드를 가진 각 노드와 모든 파드는 Running이고 2/2 READY이다(2/2는 각 파드가 weave와 weave-npc를 가지고 있음을 뜻한다).
다음 내용
위브넷 애드온을 설치하고 나서, 쿠버네티스 네트워크 폴리시를 시도하기 위해 네트워크 폴리시 선언하기를 따라 할 수 있다. 질문이 있으면 슬랙 #weave-community 이나 Weave 유저그룹에 연락한다.
5 - DNS 서비스 사용자 정의하기
이 페이지는 클러스터 안에서 사용자의 DNS 파드(Pod) 를 설정하고 DNS 변환(DNS resolution) 절차를 사용자 정의하는 방법을 설명한다.
시작하기 전에
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다. 만약, 아직 클러스터를 가지고 있지 않다면, minikube를 사용해서 생성하거나 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
클러스터는 CoreDNS 애드온을 구동하고 있어야 한다.
CoreDNS로 이관하기
는 kubeadm 을 이용하여 kube-dns 로부터 이관하는 방법을 설명한다.
쿠버네티스 서버의 버전은 다음과 같거나 더 높아야 함. 버전: v1.12.
버전 확인을 위해서, 다음 커맨드를 실행 kubectl version.
소개
DNS는 애드온 관리자 인 클러스터 애드온을 사용하여 자동으로 시작되는 쿠버네티스 내장 서비스이다.
쿠버네티스 v1.12 부터, CoreDNS는 kube-dns를 대체하여 권장되는 DNS 서버이다. 만약 사용자의 클러스터가 원래 kube-dns를 사용하였을 경우,
CoreDNS 대신 kube-dns 를 계속 사용할 수도 있다.
metadata.name 필드에 kube-dns 로 이름이 지정된다.
이를 통해, 기존의 kube-dns 서비스 이름을 사용하여 클러스터 내부의 주소를 확인하는 워크로드에 대한 상호 운용성이 증가된다. kube-dns 로 서비스 이름을 사용하면, 해당 DNS 공급자가 어떤 공통 이름으로 실행되고 있는지에 대한 구현 세부 정보를 추상화한다.
CoreDNS를 디플로이먼트(Deployment)로 실행하고 있을 경우, 일반적으로 고정 IP 주소를 갖는 쿠버네티스 서비스로 노출된다.
Kubelet 은 --cluster-dns=<dns-service-ip> 플래그를 사용하여 DNS 확인자 정보를 각 컨테이너에 전달한다.
DNS 이름에도 도메인이 필요하다. 사용자는 kubelet 에 있는 --cluster-domain=<default-local-domain> 플래그를
통하여 로컬 도메인을 설정할 수 있다.
DNS 서버는 정방향 조회(A 및 AAAA 레코드), 포트 조회(SRV 레코드), 역방향 IP 주소 조회(PTR 레코드) 등을 지원한다. 더 자세한 내용은 서비스 및 파드용 DNS를 참고한다.
만약 파드의 dnsPolicy 가 default 로 지정되어 있는 경우,
파드는 자신이 실행되는 노드의 이름 변환(name resolution) 구성을 상속한다.
파드의 DNS 변환도 노드와 동일하게 작동해야 한다.
그 외에는 알려진 이슈를 참고한다.
만약 위와 같은 방식을 원하지 않거나, 파드를 위해 다른 DNS 설정이 필요한 경우,
사용자는 kubelet 의 --resolv-conf 플래그를 사용할 수 있다.
파드가 DNS를 상속받지 못하도록 하기 위해 이 플래그를 ""로 설정한다.
DNS 상속을 위해 /etc/resolv.conf 이외의 파일을 지정할 경우 유효한 파일 경로를 설정한다.
CoreDNS
CoreDNS는 dns 명세를 준수하며 클러스터 DNS 역할을 할 수 있는, 범용적인 권한을 갖는 DNS 서버이다.
CoreDNS 컨피그맵(ConfigMap) 옵션
CoreDNS는 모듈형이자 플러그인이 가능한 DNS 서버이며, 각 플러그인들은 CoreDNS에 새로운 기능을 부가한다. 이는 CoreDNS 구성 파일인 Corefile을 관리하여 구성할 수 있다. 클러스터 관리자는 CoreDNS Corefile에 대한 컨피그맵을 수정하여 해당 클러스터에 대한 DNS 서비스 검색 동작을 변경할 수 있다.
쿠버네티스에서 CoreDNS는 아래의 기본 Corefile 구성으로 설치된다.
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
Corefile의 구성은 CoreDNS의 아래 플러그인을 포함한다.
- errors: 오류가 표준 출력(stdout)에 기록된다.
- health: CoreDNS의 상태(healthy)가
http://localhost:8080/health에 기록된다. 이 확장 구문에서lameduck은 프로세스를 비정상 상태(unhealthy)로 만들고, 프로세스가 종료되기 전에 5초 동안 기다린다. - ready: 8181 포트의 HTTP 엔드포인트가, 모든 플러그인이 준비되었다는 신호를 보내면 200 OK 를 반환한다.
- kubernetes: CoreDNS가 쿠버네티스의 서비스 및 파드의 IP를 기반으로 DNS 쿼리에 대해 응답한다. 해당 플러그인에 대한 세부 사항은 CoreDNS 웹사이트에서 확인할 수 있다.
ttl을 사용하면 응답에 대한 사용자 정의 TTL 을 지정할 수 있으며, 기본값은 5초이다. 허용되는 최소 TTL은 0초이며, 최대값은 3600초이다. 레코드가 캐싱되지 않도록 할 경우, TTL을 0으로 설정한다.pods insecure옵션은 kube-dns 와의 하위 호환성을 위해 제공된다.pods verified옵션을 사용하여, 일치하는 IP의 동일 네임스페이스(Namespace)에 파드가 존재하는 경우에만 A 레코드를 반환하게 할 수 있다.pods disabled옵션은 파드 레코드를 사용하지 않을 경우 사용된다. - prometheus: CoreDNS의 메트릭은 프로메테우스 형식(OpenMetrics 라고도 알려진)의
http://localhost:9153/metrics에서 사용 가능하다. - forward: 쿠버네티스 클러스터 도메인에 없는 쿼리들은 모두 사전에 정의된 리졸버(/etc/resolv.conf)로 전달된다.
- cache: 프론트 엔드 캐시를 활성화한다.
- loop: 간단한 전달 루프(loop)를 감지하고, 루프가 발견되면 CoreDNS 프로세스를 중단(halt)한다.
- reload: 변경된 Corefile을 자동으로 다시 로드하도록 한다. 컨피그맵 설정을 변경한 후에 변경 사항이 적용되기 위하여 약 2분정도 소요된다.
- loadbalance: 응답에 대하여 A, AAAA, MX 레코드의 순서를 무작위로 선정하는 라운드-로빈 DNS 로드밸런서이다.
사용자는 컨피그맵을 변경하여 기본 CoreDNS 동작을 변경할 수 있다.
CoreDNS를 사용하는 스텁 도메인(Stub-domain)과 업스트림 네임서버(nameserver)의 설정
CoreDNS는 포워드 플러그인을 사용하여 스텁 도메인 및 업스트림 네임서버를 구성할 수 있다.
예시
만약 클러스터 운영자가 10.150.0.1 에 위치한 Consul 도메인 서버를 가지고 있고, 모든 Consul 이름의 접미사가 .consul.local 인 경우, CoreDNS에서 이를 구성하기 위해 클러스터 관리자는 CoreDNS 컨피그맵에서 다음 구문을 생성한다.
consul.local:53 {
errors
cache 30
forward . 10.150.0.1
}
모든 비 클러스터의 DNS 조회가 172.16.0.1 의 특정 네임서버를 통과하도록 할 경우, /etc/resolv.conf 대신 forward 를 네임서버로 지정한다.
forward . 172.16.0.1
기본 Corefile 구성에 따른 최종 컨피그맵은 다음과 같다.
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
forward . 172.16.0.1
cache 30
loop
reload
loadbalance
}
consul.local:53 {
errors
cache 30
forward . 10.150.0.1
}
Kubeadm 툴은 kube-dns 컨피그맵에서 동일한 설정의 CoreDNS 컨피그맵으로의
자동 변환을 지원한다.
kube-dns에 대응되는 CoreDNS 설정
CoreDNS는 kube-dns 이상의 기능을 지원한다.
StubDomains 과 upstreamNameservers 를 지원하도록 생성된 kube-dns의 컨피그맵은 CoreDNS의 forward 플러그인으로 변환된다.
예시
kube-dns에 대한 이 컨피그맵 예제는 stubDomains 및 upstreamNameservers를 지정한다.
apiVersion: v1
data:
stubDomains: |
{"abc.com" : ["1.2.3.4"], "my.cluster.local" : ["2.3.4.5"]}
upstreamNameservers: |
["8.8.8.8", "8.8.4.4"]
kind: ConfigMap
CoreDNS에서는 동등한 설정으로 Corefile을 생성한다.
- stubDomains 에 대응하는 설정:
abc.com:53 {
errors
cache 30
forward . 1.2.3.4
}
my.cluster.local:53 {
errors
cache 30
forward . 2.3.4.5
}
기본 플러그인으로 구성된 완전한 Corefile.
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
}
federation cluster.local {
foo foo.feddomain.com
}
prometheus :9153
forward . 8.8.8.8 8.8.4.4
cache 30
}
abc.com:53 {
errors
cache 30
forward . 1.2.3.4
}
my.cluster.local:53 {
errors
cache 30
forward . 2.3.4.5
}
CoreDNS로의 이관
kube-dns에서 CoreDNS로 이관하기 위하여, kube-dns를 CoreDNS로 교체하여 적용하는 방법에 대한 상세 정보는 블로그 기사를 참고한다.
또한 공식적인 CoreDNS 배포 스크립트를 사용하여 이관할 수도 있다.
다음 내용
- DNS 변환 디버깅하기 읽기
6 - 고가용성 쿠버네티스 클러스터 컨트롤 플레인 설정하기
Kubernetes v1.5 [alpha]
구글 컴퓨트 엔진(Google Compute Engine, 이하 GCE)의 kube-up이나 kube-down 스크립트에 쿠버네티스 컨트롤 플레인 노드를 복제할 수 있다. 하지만 이러한 스크립트들은 프로덕션 용도로 사용하기에 적합하지 않으며, 프로젝트의 CI에서만 주로 사용된다.
이 문서는 kube-up/down 스크립트를 사용하여 고가용(HA) 컨트롤 플레인을 관리하는 방법과 GCE와 함께 사용하기 위해 HA 컨트롤 플레인을 구현하는 방법에 관해 설명한다.
시작하기 전에
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다. 만약, 아직 클러스터를 가지고 있지 않다면, minikube를 사용해서 생성하거나 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
HA 호환 클러스터 시작
새 HA 호환 클러스터를 생성하려면, kube-up 스크립트에 다음 플래그를 설정해야 한다.
-
MULTIZONE=true- 서버의 기본 영역(zone)과 다른 영역에서 컨트롤 플레인 kubelet이 제거되지 않도록 한다. 여러 영역에서 컨트롤 플레인 노드를 실행(권장됨)하려는 경우에 필요하다. -
ENABLE_ETCD_QUORUM_READ=true- 모든 API 서버에서 읽은 내용이 최신 데이터를 반환하도록 하기 위한 것이다. true인 경우, Etcd의 리더 복제본에서 읽는다. 이 값을 true로 설정하는 것은 선택 사항이다. 읽기는 더 안정적이지만 느리게 된다.
선택적으로, 첫 번째 컨트롤 플레인 노드가 생성될 GCE 영역을 지정할 수 있다. 다음 플래그를 설정한다.
KUBE_GCE_ZONE=zone- 첫 번째 컨트롤 플레인 노드가 실행될 영역.
다음 샘플 커맨드는 europe-west1-b GCE 영역에 HA 호환 클러스터를 구성한다.
MULTIZONE=true KUBE_GCE_ZONE=europe-west1-b ENABLE_ETCD_QUORUM_READS=true ./cluster/kube-up.sh
위의 커맨드는 하나의 컨트롤 플레인 노드를 포함하는 클러스터를 생성한다. 그러나 후속 커맨드로 새 컨트롤 플레인 노드를 추가할 수 있다.
새 컨트롤 플레인 노드 추가
HA 호환 클러스터를 생성했다면, 여기에 컨트롤 플레인 노드를 추가할 수 있다.
kube-up 스크립트에 다음 플래그를 사용하여 컨트롤 플레인 노드를 추가한다.
-
KUBE_REPLICATE_EXISTING_MASTER=true- 기존 컨트롤 플레인 노드의 복제본을 만든다. -
KUBE_GCE_ZONE=zone- 컨트롤 플레인 노드가 실행될 영역. 반드시 다른 컨트롤 플레인 노드가 존재하는 영역과 동일한 지역(region)에 있어야 한다.
HA 호환 클러스터를 시작할 때, 상속되는 MULTIZONE이나 ENABLE_ETCD_QUORUM_READS 플래그를 따로
설정할 필요는 없다.
다음 샘플 커맨드는 기존 HA 호환 클러스터에서 컨트롤 플레인 노드를 복제한다.
KUBE_GCE_ZONE=europe-west1-c KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.sh
컨트롤 플레인 노드 제거
다음 플래그가 있는 kube-down 스크립트를 사용하여 HA 클러스터에서 컨트롤 플레인 노드를 제거할 수 있다.
-
KUBE_DELETE_NODES=false- kubelet을 삭제하지 않기 위한 것이다. -
KUBE_GCE_ZONE=zone- 컨트롤 플레인 노드가 제거될 영역. -
KUBE_REPLICA_NAME=replica_name- (선택) 제거할 컨트롤 플레인 노드의 이름. 명시하지 않으면, 해당 영역의 모든 복제본이 제거된다.
다음 샘플 커맨드는 기존 HA 클러스터에서 컨트롤 플레인 노드를 제거한다.
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=europe-west1-c ./cluster/kube-down.sh
동작에 실패한 컨트롤 플레인 노드 처리
HA 클러스터의 컨트롤 플레인 노드 중 하나가 동작에 실패하면, 클러스터에서 해당 노드를 제거하고 동일한 영역에 새 컨트롤 플레인 노드를 추가하는 것이 가장 좋다. 다음 샘플 커맨드로 이 과정을 시연한다.
- 손상된 복제본을 제거한다.
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=replica_zone KUBE_REPLICA_NAME=replica_name ./cluster/kube-down.sh
- 기존 복제본을 대신할 새 노드를 추가한다.
KUBE_GCE_ZONE=replica-zone KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.sh
HA 클러스터에서 컨트롤 플레인 노드 복제에 관한 모범 사례
-
다른 영역에 컨트롤 플레인 노드를 배치하도록 한다. 한 영역이 동작에 실패하는 동안, 해당 영역에 있는 컨트롤 플레인 노드도 모두 동작에 실패할 것이다. 영역 장애를 극복하기 위해 노드를 여러 영역에 배치한다 (더 자세한 내용은 멀티 영역를 참조한다).
-
두 개의 노드로 구성된 컨트롤 플레인은 사용하지 않는다. 두 개의 노드로 구성된 컨트롤 플레인에서의 합의를 위해서는 지속적 상태(persistent state) 변경 시 두 컨트롤 플레인 노드가 모두 정상적으로 동작 중이어야 한다. 결과적으로 두 컨트롤 플레인 노드 모두 필요하고, 둘 중 한 컨트롤 플레인 노드에만 장애가 발생해도 클러스터의 심각한 장애 상태를 초래한다. 따라서 HA 관점에서는 두 개의 노드로 구성된 컨트롤 플레인은 단일 노드로 구성된 컨트롤 플레인보다도 못하다.
-
컨트롤 플레인 노드를 추가하면, 클러스터의 상태(Etcd)도 새 인스턴스로 복사된다. 클러스터가 크면, 이 상태를 복제하는 시간이 오래 걸릴 수 있다. 이 작업은 etcd 관리 가이드에 기술한 대로 Etcd 데이터 디렉터리를 마이그레이션하여 속도를 높일 수 있다. (향후에 Etcd 데이터 디렉터리 마이그레이션 지원 추가를 고려 중이다)
구현 지침
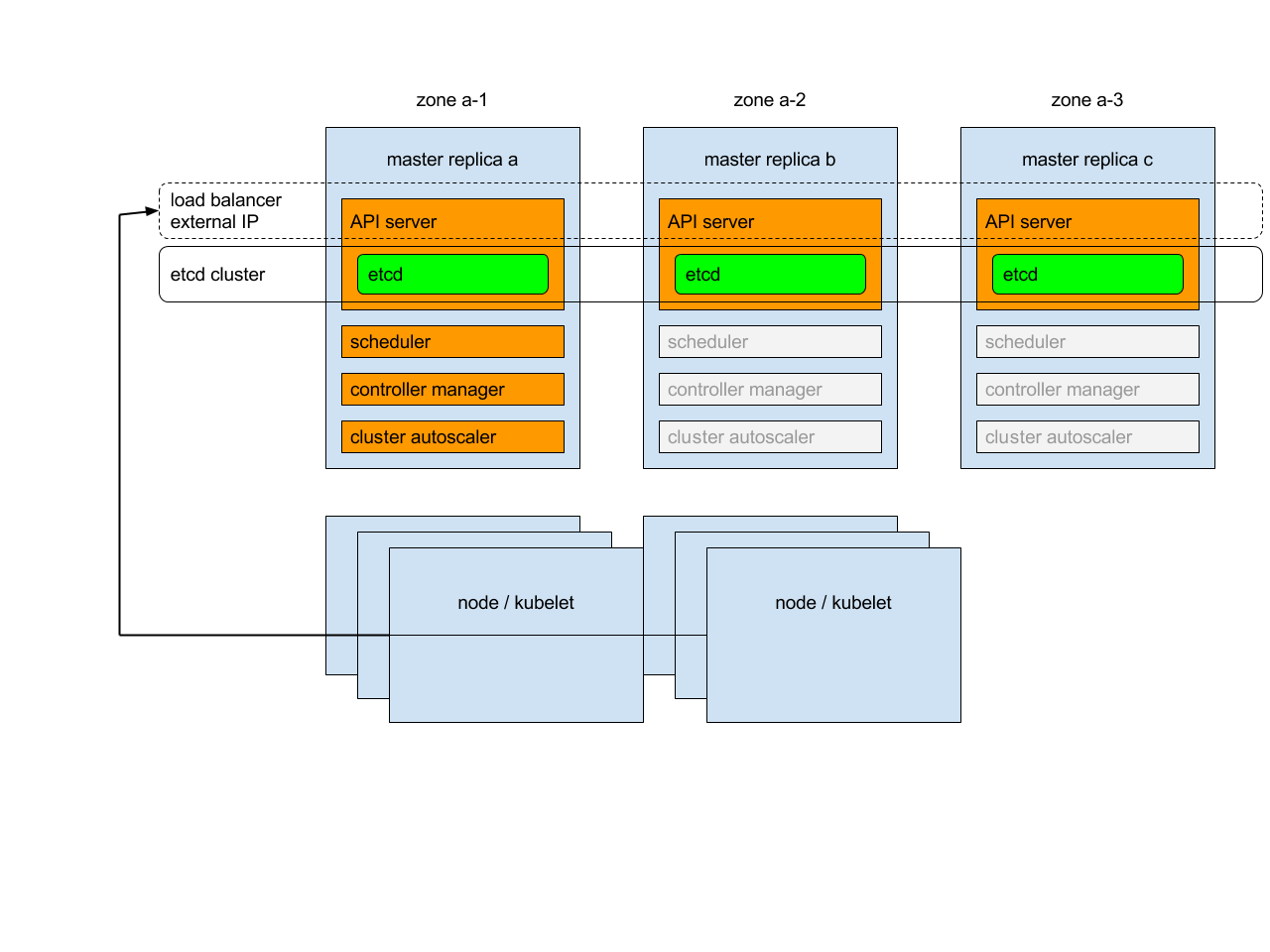
개요
각 컨트롤 플레인 노드는 다음 모드에서 다음 구성 요소를 실행한다.
-
Etcd 인스턴스: 모든 인스턴스는 합의를 사용하여 함께 클러스터화 한다.
-
API 서버: 각 서버는 내부 Etcd와 통신한다. 클러스터의 모든 API 서버가 가용하게 된다.
-
컨트롤러, 스케줄러, 클러스터 오토스케일러: 임대 방식을 이용한다. 각 인스턴스 중 하나만이 클러스터에서 활성화된다.
-
애드온 매니저: 각 매니저는 애드온의 동기화를 유지하려고 독립적으로 작업한다.
또한 API 서버 앞단에 외부/내부 트래픽을 라우팅하는 로드 밸런서가 있을 것이다.
로드 밸런싱
두 번째 컨트롤 플레인 노드를 배치할 때, 두 개의 복제본에 대한 로드 밸런서가 생성될 것이고, 첫 번째 복제본의 IP 주소가 로드 밸런서의 IP 주소로 승격된다. 비슷하게 끝에서 두 번째의 컨트롤 플레인 노드를 제거한 후에는 로드 밸런서가 제거되고 해당 IP 주소는 마지막으로 남은 복제본에 할당된다. 로드 밸런서 생성 및 제거는 복잡한 작업이며, 이를 전파하는 데 시간(~20분)이 걸릴 수 있다.
컨트롤 플레인 서비스와 Kubelet
쿠버네티스 서비스에서 최신의 쿠버네티스 API 서버 목록을 유지하는 대신, 시스템은 모든 트래픽을 외부 IP 주소로 보낸다.
-
단일 노드 컨트롤 플레인의 경우, IP 주소는 단일 컨트롤 플레인 노드를 가리킨다.
-
고가용성 컨트롤 플레인의 경우, IP 주소는 컨트롤 플레인 노드 앞의 로드밸런서를 가리킨다.
마찬가지로 Kubelet은 외부 IP 주소를 사용하여 컨트롤 플레인과 통신한다.
컨트롤 플레인 노드 인증서
쿠버네티스는 각 컨트롤 플레인 노드의 외부 퍼블릭 IP 주소와 내부 IP 주소를 대상으로 TLS 인증서를 발급한다. 컨트롤 플레인 노드의 임시 퍼블릭 IP 주소에 대한 인증서는 없다. 임시 퍼블릭 IP 주소를 통해 컨트롤 플레인 노드에 접근하려면, TLS 검증을 건너뛰어야 한다.
etcd 클러스터화
etcd를 클러스터로 구축하려면, etcd 인스턴스간 통신에 필요한 포트를 열어야 한다(클러스터 내부 통신용). 이러한 배포를 안전하게 하기 위해, etcd 인스턴스간의 통신은 SSL을 이용하여 승인한다.
API 서버 신원
Kubernetes v1.20 [alpha]
API 서버 식별 기능은
기능 게이트에
의해 제어되며 기본적으로 활성화되지 않는다.
API 서버
시작 시 APIServerIdentity 라는 기능 게이트를 활성화하여 API 서버 신원을 활성화할 수 있다.
kube-apiserver \
--feature-gates=APIServerIdentity=true \
# …다른 플래그는 평소와 같다.
부트스트랩 중에 각 kube-apiserver는 고유한 ID를 자신에게 할당한다. ID는
kube-apiserver-{UUID} 형식이다. 각 kube-apiserver는
kube-system 네임스페이스에
임대를 생성한다.
임대 이름은 kube-apiserver의 고유 ID이다. 임대에는
k8s.io/component=kube-apiserver 라는 레이블이 있다. 각 kube-apiserver는
IdentityLeaseRenewIntervalSeconds (기본값은 10초)마다 임대를 새로 갱신한다. 각
kube-apiserver는 IdentityLeaseDurationSeconds (기본값은 3600초)마다
모든 kube-apiserver 식별 ID 임대를 확인하고,
IdentityLeaseDurationSeconds 이상 갱신되지 않은 임대를 삭제한다.
IdentityLeaseRenewIntervalSeconds 및 IdentityLeaseDurationSeconds는
kube-apiserver 플래그 identity-lease-renew-interval-seconds
및 identity-lease-duration-seconds로 구성된다.
이 기능을 활성화하는 것은 HA API 서버 조정과 관련된 기능을
사용하기 위한 전제조건이다(예: StorageVersionAPI 기능 게이트).
추가 자료
7 - 기본 스토리지클래스(StorageClass) 변경하기
이 페이지는 특별한 요구사항이 없는 퍼시스턴트볼륨클레임(PersistentVolumeClaim)의 볼륨을 프로비저닝 하는데 사용되는 기본 스토리지 클래스를 변경하는 방법을 보여준다.
시작하기 전에
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다. 만약, 아직 클러스터를 가지고 있지 않다면, minikube를 사용해서 생성하거나 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
왜 기본 스토리지 클래스를 변경하는가?
설치 방법에 따라, 사용자의 쿠버네티스 클러스터는 기본으로 표시된 기존 스토리지클래스와 함께 배포될 수 있다. 이 기본 스토리지클래스는 특정 스토리지 클래스가 필요하지 않은 퍼시스턴트볼륨클레임에 대해 스토리지를 동적으로 프로비저닝 하기 위해 사용된다. 더 자세한 내용은 퍼시스턴트볼륨클레임 문서를 보자.
미리 설치된 기본 스토리지클래스가 사용자의 예상되는 워크로드에 적합하지 않을수도 있다. 예를 들어, 너무 가격이 높은 스토리지를 프로비저닝 해야할 수도 있다. 이런 경우에, 기본 스토리지 클래스를 변경하거나 완전히 비활성화 하여 스토리지의 동적 프로비저닝을 방지할 수 있다.
기본 스토리지클래스를 삭제하는 경우, 사용자의 클러스터에서 구동 중인 애드온 매니저에 의해 자동으로 다시 생성될 수 있으므로 정상적으로 삭제가 되지 않을 수도 있다. 애드온 관리자 및 개별 애드온을 비활성화 하는 방법에 대한 자세한 내용은 설치 문서를 참조하자.
기본 스토리지클래스 변경하기
-
사용자의 클러스터에 있는 스토리지클래스 목록을 조회한다.
kubectl get storageclass결과는 아래와 유사하다.
NAME PROVISIONER AGE standard (default) kubernetes.io/gce-pd 1d gold kubernetes.io/gce-pd 1d기본 스토리지클래스는
(default)로 표시되어 있다. -
기본 스토리지클래스를 기본값이 아닌 것으로 표시한다.
기본 스토리지클래스에는
storageclass.kubernetes.io/is-default-class의 값이true로 설정되어 있다. 다른 값이거나 어노테이션이 없을 경우false로 처리된다.스토리지클래스를 기본값이 아닌 것으로 표시하려면, 그 값을
false로 변경해야 한다.kubectl patch storageclass standard -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'여기서
standard는 사용자가 선택한 스토리지클래스의 이름이다. -
스토리지클래스를 기본값으로 표시한다.
이전 과정과 유사하게, 어노테이션을 추가/설정해야 한다.
storageclass.kubernetes.io/is-default-class=true.kubectl patch storageclass gold -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'최대 1개의 스토리지클래스를 기본값으로 표시할 수 있다는 것을 알아두자. 만약 2개 이상이 기본값으로 표시되면, 명시적으로
storageClassName가 지정되지 않은PersistentVolumeClaim은 생성될 수 없다. -
사용자가 선택한 스토리지클래스가 기본값으로 되어있는지 확인한다.
kubectl get storageclass결과는 아래와 유사하다.
NAME PROVISIONER AGE standard kubernetes.io/gce-pd 1d gold (default) kubernetes.io/gce-pd 1d
다음 내용
- 퍼시스턴트볼륨(PersistentVolume)에 대해 더 보기.
8 - 네트워크 폴리시(Network Policy) 선언하기
이 문서는 사용자가 쿠버네티스 네트워크폴리시 API를 사용하여 파드(Pod)가 서로 통신하는 방법을 제어하는 네트워크 폴리시를 선언하는데 도움을 준다.
시작하기 전에
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다. 만약, 아직 클러스터를 가지고 있지 않다면, minikube를 사용해서 생성하거나 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
쿠버네티스 서버의 버전은 다음과 같거나 더 높아야 함. 버전: v1.8. 버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
네트워크 폴리시를 지원하는 네트워크 제공자를 구성하였는지 확인해야 한다. 다음과 같이 네트워크폴리시를 지원하는 많은 네트워크 제공자들이 있다.
nginx 디플로이먼트(Deployment)를 생성하고 서비스(Service)를 통해 노출하기
쿠버네티스 네트워크 폴리시가 어떻게 동작하는지 확인하기 위해서, nginx 디플로이먼트를 생성한다.
kubectl create deployment nginx --image=nginx
deployment.apps/nginx created
nginx 라는 이름의 서비스를 통해 디플로이먼트를 노출한다.
kubectl expose deployment nginx --port=80
service/nginx exposed
위 명령어들은 nginx 파드에 대한 디플로이먼트를 생성하고, nginx 라는 이름의 서비스를 통해 디플로이먼트를 노출한다. nginx 파드와 디플로이먼트는 default 네임스페이스(namespace)에 존재한다.
kubectl get svc,pod
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes 10.100.0.1 <none> 443/TCP 46m
service/nginx 10.100.0.16 <none> 80/TCP 33s
NAME READY STATUS RESTARTS AGE
pod/nginx-701339712-e0qfq 1/1 Running 0 35s
다른 파드에서 접근하여 서비스 테스트하기
사용자는 다른 파드에서 새 nginx 서비스에 접근할 수 있어야 한다. default 네임스페이스에 있는 다른 파드에서 nginx 서비스에 접근하기 위하여, busybox 컨테이너를 생성한다.
kubectl run busybox --rm -ti --image=busybox -- /bin/sh
사용자 쉘에서, 다음의 명령을 실행한다.
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
remote file exists
nginx 서비스에 대해 접근 제한하기
access: true 레이블을 가지고 있는 파드만 nginx 서비스에 접근할 수 있도록 하기 위하여, 다음과 같은 네트워크폴리시 오브젝트를 생성한다.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: access-nginx
spec:
podSelector:
matchLabels:
app: nginx
ingress:
- from:
- podSelector:
matchLabels:
access: "true"
네트워크폴리시 오브젝트의 이름은 유효한 DNS 서브도메인 이름이어야 한다.
podSelector 를 포함한다. 사용자는 이 정책이 app=nginx 레이블을 갖는 파드를 선택하는 것을 볼 수 있다. 레이블은 nginx 디플로이먼트에 있는 파드에 자동으로 추가된다. 빈 podSelector 는 네임스페이스의 모든 파드를 선택한다.
서비스에 정책 할당하기
kubectl을 사용하여 위 nginx-policy.yaml 파일로부터 네트워크폴리시를 생성한다.
kubectl apply -f https://k8s.io/examples/service/networking/nginx-policy.yaml
networkpolicy.networking.k8s.io/access-nginx created
access 레이블이 정의되지 않은 서비스에 접근 테스트
올바른 레이블이 없는 파드에서 nginx 서비스에 접근하려 할 경우, 요청 타임 아웃이 발생한다.
kubectl run busybox --rm -ti --image=busybox -- /bin/sh
사용자 쉘에서, 다음의 명령을 실행한다.
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
wget: download timed out
접근 레이블을 정의하고 다시 테스트
사용자는 요청이 허용되도록 하기 위하여 올바른 레이블을 갖는 파드를 생성한다.
kubectl run busybox --rm -ti --labels="access=true" --image=busybox -- /bin/sh
사용자 쉘에서, 다음의 명령을 실행한다.
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
remote file exists
9 - 노드에 대한 확장 리소스 알리기
이 페이지는 노드의 확장 리소스를 지정하는 방법을 보여준다. 확장 리소스를 통해 클러스터 관리자는 쿠버네티스에게 알려지지 않은 노드-레벨 리소스를 알릴 수 있다.
시작하기 전에
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다. 만약, 아직 클러스터를 가지고 있지 않다면, minikube를 사용해서 생성하거나 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
노드의 이름을 확인한다
kubectl get nodes
이 연습에 사용할 노드 중 하나를 선택한다.
노드 중 하나에 새로운 확장 리소스를 알린다
노드에서 새로운 확장 리소스를 알리려면, 쿠버네티스 API 서버에 HTTP PATCH 요청을 보낸다. 예를 들어, 노드 중 하나에 4개의 동글(dongle)이 있다고 가정한다. 다음은 노드에 4개의 동글 리소스를 알리는 PATCH 요청의 예이다.
PATCH /api/v1/nodes/<your-node-name>/status HTTP/1.1
Accept: application/json
Content-Type: application/json-patch+json
Host: k8s-master:8080
[
{
"op": "add",
"path": "/status/capacity/example.com~1dongle",
"value": "4"
}
]
참고로 쿠버네티스는 동글이 무엇인지 또는 동글이 무엇을 위한 것인지 알 필요가 없다. 위의 PATCH 요청은 노드에 동글이라고 하는 네 가지 항목이 있음을 쿠버네티스에 알려준다.
쿠버네티스 API 서버에 요청을 쉽게 보낼 수 있도록 프록시를 시작한다.
kubectl proxy
다른 명령 창에서 HTTP PATCH 요청을 보낸다.
<your-node-name> 을 노드의 이름으로 바꾼다.
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/example.com~1dongle", "value": "4"}]' \
http://localhost:8001/api/v1/nodes/<your-node-name>/status
~1 은 패치 경로의 / 문자에 대한
인코딩이다. JSON-Patch의 작업 경로값은 JSON-Pointer로
해석된다. 자세한 내용은 IETF RFC 6901의
섹션 3을 참고한다.
출력은 노드가 4개의 동글 용량을 가졌음을 나타낸다.
"capacity": {
"cpu": "2",
"memory": "2049008Ki",
"example.com/dongle": "4",
노드의 정보를 확인한다.
kubectl describe node <your-node-name>
다시 한 번, 출력에 동글 리소스가 표시된다.
Capacity:
cpu: 2
memory: 2049008Ki
example.com/dongle: 4
이제, 애플리케이션 개발자는 특정 개수의 동글을 요청하는 파드를 만들 수 있다. 컨테이너에 확장 리소스 할당하기를 참고한다.
토론
확장 리소스는 메모리 및 CPU 리소스와 비슷하다. 예를 들어, 노드에서 실행 중인 모든 컴포넌트가 공유할 특정 양의 메모리와 CPU가 노드에 있는 것처럼, 노드에서 실행 중인 모든 컴포넌트가 특정 동글을 공유할 수 있다. 또한 애플리케이션 개발자가 특정 양의 메모리와 CPU를 요청하는 파드를 생성할 수 있는 것처럼, 특정 동글을 요청하는 파드를 생성할 수 있다.
확장 리소스는 쿠버네티스에게 불투명하다. 쿠버네티스는 그것들이 무엇인지 전혀 모른다. 쿠버네티스는 노드에 특정 개수의 노드만 있다는 것을 알고 있다. 확장 리소스는 정수로 알려야 한다. 예를 들어, 노드는 4.5개의 동글이 아닌, 4개의 동글을 알릴 수 있다.
스토리지 예제
노드에 800GiB의 특별한 종류의 디스크 스토리지가 있다고 가정한다. example.com/special-storage와 같은 특별한 스토리지의 이름을 생성할 수 있다. 그런 다음 특정 크기, 100GiB의 청크로 알릴 수 있다. 이 경우, 노드에는 example.com/special-storage 유형의 8가지 리소스가 있다고 알린다.
Capacity:
...
example.com/special-storage: 8
이 특별한 스토리지에 대한 임의 요청을 허용하려면, 1바이트 크기의 청크로 특별한 스토리지를 알릴 수 있다. 이 경우, example.com/special-storage 유형의 800Gi 리소스를 알린다.
Capacity:
...
example.com/special-storage: 800Gi
그런 다음 컨테이너는 최대 800Gi의 임의 바이트 수의 특별한 스토리지를 요청할 수 있다.
정리
다음은 노드에서 동글 알림을 제거하는 PATCH 요청이다.
PATCH /api/v1/nodes/<your-node-name>/status HTTP/1.1
Accept: application/json
Content-Type: application/json-patch+json
Host: k8s-master:8080
[
{
"op": "remove",
"path": "/status/capacity/example.com~1dongle",
}
]
쿠버네티스 API 서버에 요청을 쉽게 보낼 수 있도록 프록시를 시작한다.
kubectl proxy
다른 명령 창에서 HTTP PATCH 요청을 보낸다.
<your-node-name>을 노드의 이름으로 바꾼다.
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "remove", "path": "/status/capacity/example.com~1dongle"}]' \
http://localhost:8001/api/v1/nodes/<your-node-name>/status
동글 알림이 제거되었는지 확인한다.
kubectl describe node <your-node-name> | grep dongle
(출력이 보이지 않아야 함)
다음 내용
애플리케이션 개발자를 위한 문서
클러스터 관리자를 위한 문서
10 - 서비스 디스커버리를 위해 CoreDNS 사용하기
이 페이지는 CoreDNS 업그레이드 프로세스와 kube-dns 대신 CoreDNS를 설치하는 방법을 보여준다.
시작하기 전에
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다. 만약, 아직 클러스터를 가지고 있지 않다면, minikube를 사용해서 생성하거나 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
쿠버네티스 서버의 버전은 다음과 같거나 더 높아야 함. 버전: v1.9. 버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
CoreDNS 소개
CoreDNS는 쿠버네티스 클러스터의 DNS 역할을 수행할 수 있는, 유연하고 확장 가능한 DNS 서버이다. 쿠버네티스와 동일하게, CoreDNS 프로젝트도 CNCF가 관리한다.
사용자는 기존 디플로이먼트인 kube-dns를 교체하거나, 클러스터를 배포하고 업그레이드하는 kubeadm과 같은 툴을 사용하여 클러스터 안의 kube-dns 대신 CoreDNS를 사용할 수 있다.
CoreDNS 설치
Kube-dns의 배포나 교체에 관한 매뉴얼은 CoreDNS GitHub 프로젝트에 있는 문서를 확인하자.
CoreDNS로 이관하기
Kubeadm을 사용해 기존 클러스터 업그레이드하기
쿠버네티스 버전 1.10 이상에서, kube-dns 를 사용하는 클러스터를 업그레이드하기 위하여
kubeadm 을 사용할 때 CoreDNS로 전환할 수도 있다. 이 경우, kubeadm 은
kube-dns 컨피그맵(ConfigMap)을 기반으로 스텁 도메인(stub domain), 업스트림 네임 서버의
설정을 유지하며 CoreDNS 설정("Corefile")을 생성한다.
만약 kube-dns에서 CoreDNS로 이동하는 경우, 업그레이드 과정에서 기능 게이트의 CoreDNS 값을 true 로 설정해야 한다.
예를 들어, v1.11.0 로 업그레이드 하는 경우는 다음과 같다.
kubeadm upgrade apply v1.11.0 --feature-gates=CoreDNS=true
쿠버네티스 1.13 이상에서 기능 게이트의 CoreDNS 항목은 제거되었으며, CoreDNS가 기본적으로 사용된다.
1.11 미만 버전일 경우 업그레이드 과정에서 만들어진 파일이 Corefile을 덮어쓴다. 만약 컨피그맵을 사용자 정의한 경우, 기존의 컨피그맵을 저장해야 한다. 새 컨피그맵이 시작된 후에 변경 사항을 다시 적용해야 할 수도 있다.
만약 쿠버네티스 1.11 이상 버전에서 CoreDNS를 사용하는 경우, 업그레이드 과정에서, 기존의 Corefile이 유지된다.
쿠버네티스 버전 1.21에서, kubeadm 의 kube-dns 지원 기능이 삭제되었다.
CoreDNS 업그레이드하기
CoreDNS는 쿠버네티스 1.9 버전부터 사용할 수 있다. 쿠버네티스와 함께 제공되는 CoreDNS의 버전과 CoreDNS의 변경 사항은 여기에서 확인할 수 있다.
CoreDNS는 사용자 정의 이미지를 사용하거나 CoreDNS만 업그레이드 하려는 경우에 수동으로 업그레이드할 수 있다. 업그레이드를 원활하게 수행하는 데 유용한 가이드라인 및 연습을 참고하자.
CoreDNS 튜닝하기
리소스 활용이 중요한 경우, CoreDNS 구성을 조정하는 것이 유용할 수 있다. 더 자세한 내용은 CoreDNS 스케일링에 대한 설명서를 확인하자.
다음 내용
Corefile 을 수정하여 kube-dns 보다 더 많은 유스케이스를 지원하도록
CoreDNS를 구성할 수 있다.
더 자세한 내용은 CoreDNS 웹사이트을 확인하자.
11 - 중요한 애드온 파드 스케줄링 보장하기
API 서버, 스케줄러 및 컨트롤러 매니저와 같은 쿠버네티스 주요 컴포넌트들은 컨트롤 플레인 노드에서 동작한다. 반면, 애드온들은 일반 클러스터 노드에서 동작한다. 이러한 애드온들 중 일부(예: 메트릭 서버, DNS, UI)는 클러스터 전부가 정상적으로 동작하는 데 필수적일 수 있다. 만약, 필수 애드온이 축출되고(수동 축출, 혹은 업그레이드와 같은 동작으로 인한 의도하지 않은 축출) pending 상태가 된다면, 클러스터가 더 이상 제대로 동작하지 않을 수 있다. (사용률이 매우 높은 클러스터에서 해당 애드온이 축출되자마자 다른 대기중인 파드가 스케줄링되거나 다른 이유로 노드에서 사용할 수 있는 자원량이 줄어들어 pending 상태가 발생할 수 있다)
유의할 점은, 파드를 중요(critical)로 표시하는 것은 축출을 완전히 방지하기 위함이 아니다. 이것은 단지 파드가 영구적으로 사용할 수 없게 되는 것만을 방지하기 위함이다. 중요로 표시한 스태틱(static) 파드는 축출될 수 없다. 반면, 중요로 표시한 일반적인(non-static) 파드의 경우 항상 다시 스케줄링된다.
파드를 중요(critical)로 표시하기
파드를 중요로 표시하기 위해서는, 해당 파드에 대해 priorityClassName을 system-cluster-critical이나 system-node-critical로 설정한다. system-node-critical은 가장 높은 우선 순위를 가지며, 심지어 system-cluster-critical보다도 우선 순위가 높다.
12 - 쿠버네티스 API 활성화 혹은 비활성화하기
이 페이지는 클러스터 컨트롤 플레인의 특정한 API 버전을 활성화하거나 비활성화하는 방법에 대해 설명한다.
API 서버에 --runtime-config=api/<version> 커맨드 라인 인자를 사용함으로서 특정한 API 버전을
활성화하거나 비활성화할 수 있다. 이 인자에 대한 값으로는 콤마로 구분된 API 버전의 목록을 사용한다.
뒤쪽에 위치한 값은 앞쪽의 값보다 우선적으로 사용된다.
이 runtime-config 커맨드 라인 인자에는 다음의 두 개의 특수 키를 사용할 수도 있다.
api/all: 사용할 수 있는 모든 API를 선택한다.api/legacy: 레거시 API만을 선택한다. 여기서 레거시 API란 명시적으로 사용이 중단된 모든 API를 가리킨다.
예를 들어서, v1을 제외한 모든 API 버전을 비활성화하기 위해서는 kube-apiserver에
--runtime-config=api/all=false,api/v1=true 인자를 사용한다.
다음 내용
kube-apiserver 컴포넌트에 대한 더 자세한 내용은 다음의 문서
를 참고한다.
13 - 쿠버네티스 API를 사용하여 클러스터에 접근하기
이 페이지는 쿠버네티스 API를 사용하여 클러스터에 접근하는 방법을 보여준다.
시작하기 전에
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다. 만약, 아직 클러스터를 가지고 있지 않다면, minikube를 사용해서 생성하거나 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
쿠버네티스 API에 접근
kubectl을 사용하여 처음으로 접근
쿠버네티스 API에 처음 접근하는 경우, 쿠버네티스
커맨드 라인 도구인 kubectl 을 사용한다.
클러스터에 접근하려면, 클러스터 위치를 알고 접근할 수 있는 자격 증명이 있어야 한다. 일반적으로, 시작하기 가이드를 통해 작업하거나, 다른 사람이 클러스터를 설정하고 자격 증명과 위치를 제공할 때 자동으로 설정된다.
다음의 명령으로 kubectl이 알고 있는 위치와 자격 증명을 확인한다.
kubectl config view
많은 예제는 kubectl 사용에 대한 소개를 제공한다. 전체 문서는 kubectl 매뉴얼에 있다.
REST API에 직접 접근
kubectl은 API 서버 찾기와 인증을 처리한다. curl 이나 wget 과 같은 http 클라이언트 또는 브라우저를 사용하여 REST API에
직접 접근하려는 경우, API 서버를 찾고 인증할 수 있는 여러 가지 방법이 있다.
- 프록시 모드에서 kubectl을 실행한다(권장). 이 방법은 저장된 API 서버 위치를 사용하고 자체 서명된 인증서를 사용하여 API 서버의 ID를 확인하므로 권장한다. 이 방법을 사용하면 중간자(man-in-the-middle, MITM) 공격이 불가능하다.
- 또는, 위치와 자격 증명을 http 클라이언트에 직접 제공할 수 있다. 이 방법은 프록시를 혼란스럽게 하는 클라이언트 코드와 동작한다. 중간자 공격으로부터 보호하려면, 브라우저로 루트 인증서를 가져와야 한다.
Go 또는 Python 클라이언트 라이브러리를 사용하면 프록시 모드에서 kubectl에 접근할 수 있다.
kubectl 프록시 사용
다음 명령은 kubectl을 리버스 프록시로 작동하는 모드에서 실행한다. API 서버 찾기와 인증을 처리한다.
다음과 같이 실행한다.
kubectl proxy --port=8080 &
자세한 내용은 kubectl 프록시를 참고한다.
그런 다음 curl, wget 또는 브라우저를 사용하여 API를 탐색할 수 있다.
curl http://localhost:8080/api/
출력은 다음과 비슷하다.
{
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.1.149:443"
}
]
}
kubectl 프록시 없이 접근
다음과 같이 인증 토큰을 API 서버에 직접 전달하여 kubectl 프록시 사용을 피할 수 있다.
grep/cut 방식을 사용한다.
# .KUBECONFIG에 여러 콘텍스트가 있을 수 있으므로, 가능한 모든 클러스터를 확인한다.
kubectl config view -o jsonpath='{"Cluster name\tServer\n"}{range .clusters[*]}{.name}{"\t"}{.cluster.server}{"\n"}{end}'
# 위의 출력에서 상호 작용하려는 클러스터의 이름을 선택한다.
export CLUSTER_NAME="some_server_name"
# 클러스터 이름을 참조하는 API 서버를 가리킨다.
APISERVER=$(kubectl config view -o jsonpath="{.clusters[?(@.name==\"$CLUSTER_NAME\")].cluster.server}")
# 토큰 값을 얻는다
TOKEN=$(kubectl get secrets -o jsonpath="{.items[?(@.metadata.annotations['kubernetes\.io/service-account\.name']=='default')].data.token}"|base64 --decode)
# TOKEN으로 API 탐색
curl -X GET $APISERVER/api --header "Authorization: Bearer $TOKEN" --insecure
출력은 다음과 비슷하다.
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.1.149:443"
}
]
}
jsonpath 방식을 사용한다.
APISERVER=$(kubectl config view --minify -o jsonpath='{.clusters[0].cluster.server}')
TOKEN=$(kubectl get secret $(kubectl get serviceaccount default -o jsonpath='{.secrets[0].name}') -o jsonpath='{.data.token}' | base64 --decode )
curl $APISERVER/api --header "Authorization: Bearer $TOKEN" --insecure
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.1.149:443"
}
]
}
위의 예는 --insecure 플래그를 사용한다. 이로 인해 MITM 공격이
발생할 수 있다. kubectl이 클러스터에 접근하면 저장된 루트 인증서와
클라이언트 인증서를 사용하여 서버에 접근한다. (~/.kube 디렉터리에
설치된다.) 클러스터 인증서는 일반적으로 자체 서명되므로,
http 클라이언트가 루트 인증서를 사용하도록 하려면 특별한 구성이
필요할 수 있다.
일부 클러스터에서, API 서버는 인증이 필요하지 않다. 로컬 호스트에서 제공되거나, 방화벽으로 보호될 수 있다. 이에 대한 표준은 없다. 쿠버네티스 API에 대한 접근 제어은 클러스터 관리자로서 이를 구성하는 방법에 대해 설명한다. 이러한 접근 방식은 향후 고 가용성 지원과 충돌할 수 있다.
API에 프로그래밍 방식으로 접근
쿠버네티스는 공식적으로 Go, Python, Java, dotnet, Javascript 및 Haskell 용 클라이언트 라이브러리를 지원한다. 쿠버네티스 팀이 아닌 작성자가 제공하고 유지 관리하는 다른 클라이언트 라이브러리가 있다. 다른 언어에서 API에 접근하고 인증하는 방법에 대해서는 클라이언트 라이브러리를 참고한다.
Go 클라이언트
- 라이브러리를 얻으려면, 다음 명령을 실행한다.
go get k8s.io/client-go@kubernetes-<kubernetes-version-number>어떤 버전이 지원되는지를 확인하려면 https://github.com/kubernetes/client-go/releases를 참고한다. - client-go 클라이언트 위에 애플리케이션을 작성한다.
import "k8s.io/client-go/kubernetes" 가 맞다.
Go 클라이언트는 kubectl CLI가 API 서버를 찾아 인증하기 위해 사용하는 것과 동일한 kubeconfig 파일을 사용할 수 있다. 이 예제를 참고한다.
package main
import (
"context"
"fmt"
"k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/tools/clientcmd"
)
func main() {
// kubeconfig에서 현재 콘텍스트를 사용한다
// path-to-kubeconfig -- 예를 들어, /root/.kube/config
config, _ := clientcmd.BuildConfigFromFlags("", "<path-to-kubeconfig>")
// clientset을 생성한다
clientset, _ := kubernetes.NewForConfig(config)
// 파드를 나열하기 위해 API에 접근한다
pods, _ := clientset.CoreV1().Pods("").List(context.TODO(), v1.ListOptions{})
fmt.Printf("There are %d pods in the cluster\n", len(pods.Items))
}
애플리케이션이 클러스터 내의 파드로 배치된 경우, 파드 내에서 API 접근을 참고한다.
Python 클라이언트
Python 클라이언트를 사용하려면, 다음 명령을 실행한다. pip install kubernetes 추가 설치 옵션은 Python Client Library 페이지를 참고한다.
Python 클라이언트는 kubectl CLI가 API 서버를 찾아 인증하기 위해 사용하는 것과 동일한 kubeconfig 파일을 사용할 수 있다. 이 예제를 참고한다.
from kubernetes import client, config
config.load_kube_config()
v1=client.CoreV1Api()
print("Listing pods with their IPs:")
ret = v1.list_pod_for_all_namespaces(watch=False)
for i in ret.items:
print("%s\t%s\t%s" % (i.status.pod_ip, i.metadata.namespace, i.metadata.name))
Java 클라이언트
Java 클라이언트를 설치하려면, 다음을 실행한다.
# java 라이브러리를 클론한다
git clone --recursive https://github.com/kubernetes-client/java
# 프로젝트 아티팩트, POM 등을 설치한다
cd java
mvn install
어떤 버전이 지원되는지를 확인하려면 https://github.com/kubernetes-client/java/releases를 참고한다.
Java 클라이언트는 kubectl CLI가 API 서버를 찾아 인증하기 위해 사용하는 것과 동일한 kubeconfig 파일을 사용할 수 있다. 이 예제를 참고한다.
package io.kubernetes.client.examples;
import io.kubernetes.client.ApiClient;
import io.kubernetes.client.ApiException;
import io.kubernetes.client.Configuration;
import io.kubernetes.client.apis.CoreV1Api;
import io.kubernetes.client.models.V1Pod;
import io.kubernetes.client.models.V1PodList;
import io.kubernetes.client.util.ClientBuilder;
import io.kubernetes.client.util.KubeConfig;
import java.io.FileReader;
import java.io.IOException;
/**
* 쿠버네티스 클러스터 외부의 애플리케이션에서 Java API를 사용하는 방법에 대한 간단한 예
*
* <p>이것을 실행하는 가장 쉬운 방법: mvn exec:java
* -Dexec.mainClass="io.kubernetes.client.examples.KubeConfigFileClientExample"
*
*/
public class KubeConfigFileClientExample {
public static void main(String[] args) throws IOException, ApiException {
// KubeConfig의 파일 경로
String kubeConfigPath = "~/.kube/config";
// 파일시스템에서 클러스터 외부 구성인 kubeconfig 로드
ApiClient client =
ClientBuilder.kubeconfig(KubeConfig.loadKubeConfig(new FileReader(kubeConfigPath))).build();
// 전역 디폴트 api-client를 위에서 정의한 클러스터 내 클라이언트로 설정
Configuration.setDefaultApiClient(client);
// CoreV1Api는 전역 구성에서 디폴트 api-client를 로드
CoreV1Api api = new CoreV1Api();
// CoreV1Api 클라이언트를 호출한다
V1PodList list = api.listPodForAllNamespaces(null, null, null, null, null, null, null, null, null);
System.out.println("Listing all pods: ");
for (V1Pod item : list.getItems()) {
System.out.println(item.getMetadata().getName());
}
}
}
dotnet 클라이언트
dotnet 클라이언트를 사용하려면, 다음 명령을 실행한다. dotnet add package KubernetesClient --version 1.6.1 추가 설치 옵션은 dotnet Client Library 페이지를 참고한다. 어떤 버전이 지원되는지를 확인하려면 https://github.com/kubernetes-client/csharp/releases를 참고한다.
dotnet 클라이언트는 kubectl CLI가 API 서버를 찾아 인증하기 위해 사용하는 것과 동일한 kubeconfig 파일을 사용할 수 있다. 이 예제를 참고한다.
using System;
using k8s;
namespace simple
{
internal class PodList
{
private static void Main(string[] args)
{
var config = KubernetesClientConfiguration.BuildDefaultConfig();
IKubernetes client = new Kubernetes(config);
Console.WriteLine("Starting Request!");
var list = client.ListNamespacedPod("default");
foreach (var item in list.Items)
{
Console.WriteLine(item.Metadata.Name);
}
if (list.Items.Count == 0)
{
Console.WriteLine("Empty!");
}
}
}
}
JavaScript 클라이언트
JavaScript 클라이언트를 설치하려면, 다음 명령을 실행한다. npm install @kubernetes/client-node 어떤 버전이 지원되는지를 확인하려면 https://github.com/kubernetes-client/javascript/releases를 참고한다.
JavaScript 클라이언트는 kubectl CLI가 API 서버를 찾아 인증하기 위해 사용하는 것과 동일한 kubeconfig 파일을 사용할 수 있다. 이 예제를 참고한다.
const k8s = require('@kubernetes/client-node');
const kc = new k8s.KubeConfig();
kc.loadFromDefault();
const k8sApi = kc.makeApiClient(k8s.CoreV1Api);
k8sApi.listNamespacedPod('default').then((res) => {
console.log(res.body);
});
Haskell 클라이언트
어떤 버전이 지원되는지를 확인하려면 https://github.com/kubernetes-client/haskell/releases를 참고한다.
Haskell 클라이언트는 kubectl CLI가 API 서버를 찾아 인증하기 위해 사용하는 것과 동일한 kubeconfig 파일을 사용할 수 있다. 이 예제를 참고한다.
exampleWithKubeConfig :: IO ()
exampleWithKubeConfig = do
oidcCache <- atomically $ newTVar $ Map.fromList []
(mgr, kcfg) <- mkKubeClientConfig oidcCache $ KubeConfigFile "/path/to/kubeconfig"
dispatchMime
mgr
kcfg
(CoreV1.listPodForAllNamespaces (Accept MimeJSON))
>>= print
다음 내용
14 - 클러스터에서 실행되는 서비스에 접근
이 페이지는 쿠버네티스 클러스터에서 실행되는 서비스에 연결하는 방법을 보여준다.
시작하기 전에
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다. 만약, 아직 클러스터를 가지고 있지 않다면, minikube를 사용해서 생성하거나 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
클러스터에서 실행되는 서비스에 접근
쿠버네티스에서, 노드, 파드 및 서비스는 모두 고유한 IP를 가진다. 당신의 데스크탑 PC와 같은 클러스터 외부 장비에서는 클러스터 상의 노드 IP, 파드 IP, 서비스 IP로 라우팅되지 않아서 접근할 수 없을 것이다.
연결하는 방법
클러스터 외부에서 노드, 파드 및 서비스에 접속하기 위한 몇 가지 옵션이 있다.
- 퍼블릭 IP를 통해 서비스에 접근한다.
- 클러스터 외부에서 접근할 수 있도록
NodePort또는LoadBalancer타입의 서비스를 사용한다. 서비스와 kubectl expose 문서를 참고한다. - 클러스터 환경에 따라, 서비스는 회사 네트워크에만 노출되기도 하며, 인터넷에 노출되는 경우도 있다. 이 경우 노출되는 서비스의 보안 여부를 고려해야 한다. 해당 서비스는 자체적으로 인증을 수행하는가?
- 파드는 서비스 뒤에 위치시킨다. 디버깅과 같은 목적으로 레플리카 집합에서 특정 파드에 접근하려면, 파드에 고유한 레이블을 배치하고 이 레이블을 선택하는 새 서비스를 생성한다.
- 대부분의 경우, 애플리케이션 개발자가 nodeIP를 통해 노드에 직접 접근할 필요는 없다.
- 클러스터 외부에서 접근할 수 있도록
- 프록시 작업(Proxy Verb)을 사용하여 서비스, 노드 또는 파드에 접근한다.
- 원격 서비스에 접근하기 전에 apiserver 인증과 권한 부여를 수행한다. 서비스가 인터넷에 노출되거나, 노드 IP의 포트에 접근하거나, 디버깅하기에 충분히 안전하지 않은 경우 사용한다.
- 프록시는 일부 웹 애플리케이션에 문제를 일으킬 수 있다.
- HTTP/HTTPS에서만 작동한다.
- 여기에 설명되어 있다.
- 클러스터의 노드 또는 파드에서 접근한다.
- 파드를 실행한 다음, kubectl exec를 사용하여 셸에 연결한다. 해당 셸에서 다른 노드, 파드 및 서비스에 연결한다.
- 일부 클러스터는 클러스터의 노드로 ssh를 통해 접근하는 것을 허용한다. 거기에서 클러스터 서비스에 접근할 수 있다. 이것은 비표준 방법이며, 일부 클러스터에서는 작동하지만 다른 클러스터에서는 작동하지 않는다. 브라우저 및 기타 도구가 설치되거나 설치되지 않을 수 있다. 클러스터 DNS가 작동하지 않을 수도 있다.
빌트인 서비스 검색
일반적으로 kube-system에 의해 클러스터에 실행되는 몇 가지 서비스가 있다.
kubectl cluster-info 커맨드로 이 서비스의 리스트를 볼 수 있다.
kubectl cluster-info
출력은 다음과 비슷하다.
Kubernetes master is running at https://104.197.5.247
elasticsearch-logging is running at https://104.197.5.247/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy
kibana-logging is running at https://104.197.5.247/api/v1/namespaces/kube-system/services/kibana-logging/proxy
kube-dns is running at https://104.197.5.247/api/v1/namespaces/kube-system/services/kube-dns/proxy
grafana is running at https://104.197.5.247/api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
heapster is running at https://104.197.5.247/api/v1/namespaces/kube-system/services/monitoring-heapster/proxy
각 서비스에 접근하기 위한 프록시-작업 URL이 표시된다.
예를 들어, 이 클러스터에는 https://104.197.5.247/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/ 로
접근할 수 있는 (Elasticsearch를 사용한) 클러스터 수준 로깅이 활성화되어 있다. 적합한 자격 증명이 전달되는 경우나 kubectl proxy를 통해 도달할 수 있다. 예를 들어 다음의 URL에서 확인할 수 있다.
http://localhost:8080/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/.
apiserver 프록시 URL 수동 구성
위에서 언급한 것처럼, kubectl cluster-info 명령을 사용하여 서비스의 프록시 URL을 검색한다. 서비스 엔드포인트, 접미사 및 매개 변수를 포함하는 프록시 URL을 작성하려면, 서비스의 프록시 URL에 추가하면 된다.
http://kubernetes_master_address/api/v1/namespaces/namespace_name/services/[https:]service_name[:port_name]/proxy
포트에 대한 이름을 지정하지 않은 경우, URL에 port_name 을 지정할 필요가 없다.
예제
-
Elasticsearch 서비스 엔드포인트
_search?q=user:kimchy에 접근하려면, 다음을 사용한다.http://104.197.5.247/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/_search?q=user:kimchy -
Elasticsearch 클러스터 상태 정보
_cluster/health?pretty=true에 접근하려면, 다음을 사용한다.https://104.197.5.247/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/_cluster/health?pretty=true상태 정보는 다음과 비슷하다.
{ "cluster_name" : "kubernetes_logging", "status" : "yellow", "timed_out" : false, "number_of_nodes" : 1, "number_of_data_nodes" : 1, "active_primary_shards" : 5, "active_shards" : 5, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 5 } -
https Elasticsearch 서비스 상태 정보
_cluster/health?pretty=true에 접근하려면, 다음을 사용한다.https://104.197.5.247/api/v1/namespaces/kube-system/services/https:elasticsearch-logging/proxy/_cluster/health?pretty=true
웹 브라우저를 사용하여 클러스터에서 실행되는 서비스에 접근
브라우저의 주소 표시줄에 apiserver 프록시 URL을 넣을 수 있다. 그러나,
- 웹 브라우저는 일반적으로 토큰을 전달할 수 없으므로, 기본 (비밀번호) 인증을 사용해야 할 수도 있다. Apiserver는 기본 인증을 수락하도록 구성할 수 있지만, 클러스터는 기본 인증을 수락하도록 구성되지 않을 수 있다.
- 일부 웹 앱, 특히 프록시 경로 접두사를 인식하지 못하는 방식으로 URL을 구성하는 클라이언트 측 자바스크립트가 있는 웹 앱이 작동하지 않을 수 있다.
15 - 토폴로지 인지 힌트 활성화하기
Kubernetes v1.21 [alpha]
토폴로지 인지 힌트 는 엔드포인트슬라이스(EndpointSlices)에 포함되어 있는 토폴로지 정보를 이용해 토폴로지 인지 라우팅을 가능하게 한다. 이 방법은 트래픽을 해당 트래픽이 시작된 곳과 최대한 근접하도록 라우팅하는데, 이를 통해 비용을 줄이거나 네트워크 성능을 향상시킬 수 있다.
시작하기 전에
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다. 만약, 아직 클러스터를 가지고 있지 않다면, minikube를 사용해서 생성하거나 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
쿠버네티스 서버의 버전은 다음과 같거나 더 높아야 함. 버전: 1.21. 버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
토폴로지 인지 힌트를 활성화하기 위해서는 다음의 필수 구성 요소가 필요하다.
- kube-proxy가 iptables 모드 혹은 IPVS 모드로 동작하도록 설정
- 엔드포인트슬라이스가 비활성화되지 않았는지 확인
토폴로지 인지 힌트 활성화하기
서비스 토폴로지 힌트를 활성화하기 위해서는 kube-apiserver, kube-controller-manager, kube-proxy에 대해
TopologyAwareHints 기능 게이트를
활성화한다.
--feature-gates="TopologyAwareHints=true"
다음 내용
- 서비스 항목 아래의 토폴로지 인지 힌트를 참고
- 서비스와 애플리케이션 연결하기를 참고
16 - 퍼시스턴트볼륨 반환 정책 변경하기
이 페이지는 쿠버네티스 퍼시트턴트볼륨(PersistentVolume)의 반환 정책을 변경하는 방법을 보여준다.
시작하기 전에
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 이 튜토리얼은 컨트롤 플레인 호스트가 아닌 노드가 적어도 2개 포함된 클러스터에서 실행하는 것을 추천한다. 만약, 아직 클러스터를 가지고 있지 않다면, minikube를 사용해서 생성하거나 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
왜 퍼시스턴트볼륨 반환 정책을 변경하는가?
퍼시스턴트볼륨은 "Retain(보존)", "Recycle(재활용)", "Delete(삭제)" 를 포함한
다양한 반환 정책을 갖는다. 동적으로 프로비저닝 된 퍼시스턴트볼륨의 경우
기본 반환 정책은 "Delete" 이다. 이는 사용자가 해당 PersistentVolumeClaim 을 삭제하면,
동적으로 프로비저닝 된 볼륨이 자동적으로 삭제됨을 의미한다.
볼륨에 중요한 데이터가 포함된 경우, 이러한 자동 삭제는 부적절 할 수 있다.
이 경우에는, "Retain" 정책을 사용하는 것이 더 적합하다.
"Retain" 정책에서, 사용자가 퍼시스턴트볼륨클레임을 삭제할 경우 해당하는
퍼시스턴트볼륨은 삭제되지 않는다.
대신, Released 단계로 이동되어, 모든 데이터를 수동으로 복구할 수 있다.
퍼시스턴트볼륨 반환 정책 변경하기
-
사용자의 클러스터에서 퍼시스턴트볼륨을 조회한다.
kubectl get pv결과는 아래와 같다.
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-b6efd8da-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim1 manual 10s pvc-b95650f8-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim2 manual 6s pvc-bb3ca71d-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim3 manual 3s이 목록은 동적으로 프로비저닝 된 볼륨을 쉽게 식별할 수 있도록 각 볼륨에 바인딩 되어 있는 퍼시스턴트볼륨클레임(PersistentVolumeClaim)의 이름도 포함한다.
-
사용자의 퍼시스턴트볼륨 중 하나를 선택한 후에 반환 정책을 변경한다.
kubectl patch pv <your-pv-name> -p '{"spec":{"persistentVolumeReclaimPolicy":"Retain"}}'<your-pv-name>는 사용자가 선택한 퍼시스턴트볼륨의 이름이다.참고:윈도우에서는, 공백이 포함된 모든 JSONPath 템플릿에 _겹_ 따옴표를 사용해야 한다.(bash에 대해 위에서 표시된 홑 따옴표가 아니다.) 따라서 템플릿의 모든 표현식에서 홑 따옴표를 쓰거나, 이스케이프 처리된 겹 따옴표를 써야 한다. 예를 들면 다음과 같다.kubectl patch pv <your-pv-name> -p "{\"spec\":{\"persistentVolumeReclaimPolicy\":\"Retain\"}}" -
선택한 PersistentVolume이 올바른 정책을 갖는지 확인한다.
kubectl get pv결과는 아래와 같다.
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-b6efd8da-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim1 manual 40s pvc-b95650f8-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim2 manual 36s pvc-bb3ca71d-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Retain Bound default/claim3 manual 33s위 결과에서,
default/claim3클레임과 바인딩 되어 있는 볼륨이Retain반환 정책을 갖는 것을 볼 수 있다. 사용자가default/claim3클레임을 삭제할 경우, 볼륨은 자동으로 삭제 되지 않는다.
다음 내용
- 퍼시스턴트볼륨에 대해 더 배워 보기.
- 퍼시스턴트볼륨클레임에 대해 더 배워 보기.
Reference
- 퍼시스턴트볼륨
- 퍼시스턴트볼륨클레임
- PersistentVolumeSpec의
persistentVolumeReclaimPolicy필드에 대해 보기.